link: https://www.face-rec.org/algorithms/Boosting-Ensemble/16981346.pdf
OpenCV 에 구현된 Viola&Jones의 face detector 결과

Abstract:
본 논문에서는 높은 검출률을 달성하면서도 극도로 빠르게 영상처리를 할 수 있는 얼굴 검출 프레임워크를 제안함.
본 논문의 주요 기여
- 1. Integral Image: Integral Image로 image를 표현함으로써, 본 논문의 detector에서 사용하는 features들의 계산을 매우 빠르게 함.
- 2. AdaBoost learning algorithms: 다수의 잠재적인 feature들의 set으로부터 소수의 중요한 visual feature를 선택하기 위해 AdaBoost를 이용한 단순하고 효율적인 분류기를 구성
- 3. Cascaded Classifier: 얼굴과 유사한 영역에 대해서만 좀 더 많은 계산을 하면서 배경 영역에 해당하는 정보들은 빨리 버릴 수 있도록 "cascade" 형태로 classifier를 결합함.
본 논문에서 제안한 시스템은 이전의 다양한 관련 연구들과 비교할만한 성능을 보이며, 일반적인 desktop에서, 15 fps의 속도를 보임.
1. Introduction
기존의 연구보다 실시간 적인 측면에서 훨씬 더 우수하다는 이야기를 함.
본 논문의 3가지 주요 기여에 대한 설명
1) Integral Image
- 상당히 빠른 특징 평가를 수행할 수 있도록 이미지를 새로운 방식으로 표현함.
- 동기 부여: 1998년 Papageorgiou의 연구
- Haar Basis functions을 연상시키는 feature들의 set을 사용하며, 영상 밝기값을 직접적으로 이용하지 않음.
- 여러 스케일에 대해 위의 feature들의 set을 매우 빠르게 계산하기 위해, image를 integral image로 나타내는 방법을 도입함.
- 하나의 이미지로부터 integral image는 픽셀 당 몇 번의 연산으로 계산이 될 수 있으며, 일단 계산이 되면, 어떤 scale이나 location에 있는 어떠한 Haar-like feature든지 간에 일정한 시간으로 계산이 가능함.
2) AdaBoost (Freund and Schapire,1995)
- AdaBoost를 이용해서 거대한 저장소 내 잠재적인 feature 들로부터 소수의 중요한 feature들만을 선택함으로써 효율적이며 단순한 분류기를 구성하는 것임.
- 모든 image sub-window 내 Haar-like features의 전체 개수는 매우 많으며, 픽셀의 개수보다 훨씬 많음.
- 빠른 분류기를 보장하기 위해서, 학습 처리는 대다수의 활용 가능한 features들을 제외시키고, 중요한 소수의 feature들에 집중을 해야 함.
- Tieu 와 Viola (2000) 연구에서 동기를 부여 받아, 각각의 weak classifier가 단지 single feature에만 의존적이도록 제약을 줌으로써 AdaBoost learning 알고리즘을 사용하여 특징 선택을 수행함.
- 그 결과 하나의 새로운 weak classifier를 선택하는 각각의 boosting 처리의 stage는 feature 선택으로서 나타날 수 있게 됨.
- AdaBoost는 효율적인 learning 알고리즘을 제공하며, 일반화 성능이 우수함(Schapire et al., 1998).
3) Cascaded Classifier (Freund and Schapire,1995)
- 이미지 내 promising한 영역에만 초점을 맞춰 집중함으로써 detector의 속도를 엄청 빠르게 할 수 있도록, 더욱 더 복잡한 분류기들을 연속적으로 하나의 cascade 구조로 결합 하는 것임.
- 초점을 맞춰 집중하는 전략에 숨겨진 개념은 하나의 이미지 내에서 어디에 얼굴이 발생할 수 있는지를 빠르게 결정 하는 것이 가능하다는 것임.(Tsotsos et al., 1995; Itti et al., 1998; Amit and Geman, 1999; Fleuret and Geman, 2001).
- 단지 promising한 영역에 대해서만 더욱 더 복잡한 처리가 예약이 됨.
- 위와 같은 접근의 key measure는 집중적(attentional) 처리에 의한 "false negative" rate가 됨.
- 거의 모든 경우에 있어서 face에 대한 instance는 attentional filter에 의해서 선택이 되어짐.
본 논문에서는 하나의 "supervised" focus of attentional operator로서 사용될 수 있는 극도로 단순하며 효율적인 분류기를 훈련시키기 위한 과정에 대해서 기술할 것임.
- face detection attentional operator는 얼굴의 99%를 보존하면서도 이미지의 55%에 대한 filter out 을 수행 할 수 있도록 훈련될 수 있음.
- 이러한 filter는 엄청나게 효율적임; location 및 scale 마다 20개의 단순한 연산으로서 평가가 될 수 있음(대략 60 microprocessor instructions).
초기 분류기에 의해서 rejection 되지 않은 sub-windows는 이전보다 약간 더 복잡한 분류기 sequence에 의해서 처리가 됨.
- 만약 분류기가 sub-windows를 rejection 했다면 더 이상의 처리는 수행되지 않음.
- cascaded detection 처리의 구조는 degenerate decision tree와 같으며 leuret and Geman (2001) and Amit and Geman (1999) 의 연구와 관련이 있음.
완벽한 face detection cascade는 전체 80,000번의 연산을 수행하는 38개의 분류기를 가지고 있음.
- 그럼에도 불구하고 cascade 구조는 극도로 빠른 평균 검출 시간의 결과를 보임.
- 507개의 얼굴과 7천 5백만개의 sub-windows를 가지고 있는 어려운 dataset에 대해서도 sub-window 당 평균 270 microprocessor instructions 을 사용하여 얼굴이 검출이 됨.
상당히 빠른 face detector에 의해서 이전에 불가능했던 실시간 얼굴 검출 어플리케이션이 가능하게 되었음.
1.1. Overview
- Section 2: feature 의 구성 및 feature 계산을 빠르게 하기 위한 새로운 전략에 대한 내용을 기술
- Section 3: 위의 feature들이 하나의 분류기를 형성할 수 있도록 결합되는 방법에 대한 내용을 기술. AdaBoost 알고리즘은 특징 선택 메커니즘으로서의 역할을 함. 분류기가 우수한 계산 및 분류 성능을 갖도록 구성되는 동안에 실시간 분류기로서는 더욱 더 느려지게 됨.
- Section 4: 상당히 빠르며 신뢰할 만하고 효율적인 face detector를 만들기 위해서 cascaded classifier을 구성하는 방법에 대해서 기술.
- Section 5: 상당히 많은 실험 및 실험 결과에 대해서 기술함.
- Section 6: 제안한 시스템에 대한 토론 및 관련된 시스템들에 대해서 discussion 함.
2. Features
본 논문의 face detection 절차는 simple한 features의 값에 기반하여 image를 분류함. 픽셀 값을 직접 이용하기 보다는 feature를 사용하는 것에는 다양한 동기가 있음.
- 1. 가장 중요한 이유는 한정된 training data를 사용하여 학습시키기 어려운 domain knowledge를 표현하는데 feature는 적격이기 때문임.
- 2. feature 기반 시스템은 pixel 기반 시스템에 비해서 훨씬 더 빠르게 동작함.
본 논문에서 사용한 simple feature는 Papageorgiou et al. (1998)가 사용한 Haar basis fuction을 연상시킴.
- 더욱 더 구체적으로 본 논문에서는 3가지 종류의 feature를 사용함.
- two-rectangle feature 의 값은 두 개의 직사각형 영역 사이의 픽셀들의 합에 대한 차이를 구하는 것임.
- 영역은 동일한 크기 및 모양을 가지고 있으며, 수평 또는 수직적으로 인접하고 있음. (그림 1 참고)
- three-rectangle feature 는 두 개의 바깥쪽 직사각형 사이의 합과 중간의 사각형의 합에 대한 차이를 구함.
- 마지막 four-rectangle feature 는 대각 사각형의 차이를 계산함. 즉 대각 사각형의 흰색 영역에 대한 합과 대각 사각형의 검은색 영역에 대한 합의 차이를 구하는 것을 말함.

detector의 기본적인 해상도가 24 x 24 로 주어졌을 경우에, rectangle feature set은 160,000 개 이상으로 상당함.
- Haar basis와 다르게 rectangle features set은 overcomplete 함.
2.1. Integral Image
rectangle features는 integral image 라고 불리우는 image에 대한 중간적인 표현을 이용하여 매우 빠르게 계산이 될 수 있음.
- 위치 x, y에 있어서 integral image의 값은 위쪽부터 좌측을 모두 포함하고 있는 모든 픽셀들의 합에 의해서 나타남.

- ii(x, y) : integral image, i(x, y) : 원래의 image(그림 2)

- 아래와 같이 다시 표현 가능

- s(x, y) : row에 대한 누적 합, s(x, -1) = 0, ii(-1, y) = 0 임.
- integral image는 원래 image에 대해서 one pass만으로 계산이 되어질 수 있음.
integral image를 사용함으로써 어떤 rectangular feature의 sum이라도 그림 3과 같이 4번의 array 참조를 이용해서 계산이 될 수 있음.

- 명확하게, 두 개의 rectangular sum 사이의 차이는 8번의 참조에 의해서 계산이 될 수 있음.
- two-rectangle feature 는 인접한 rectangular sum을 포함하며, 6번의 array 참조를 이용해서 계산이 될 수 있음.
- three-rectangle feature 는 인접한 rectangular sum을 포함하며, 8번의 array 참조를 이용해서 계산이 될 수 있음.
- four-rectangle feature 는 인접한 rectangular sum을 포함하며, 9번의 array 참조를 이용해서 계산이 될 수 있음.
integral image에 대한 이론적 증명에 대한 이야기를 함. Simard et al.(1999).
2.2. Feature Discussion
rectangle feature는 steerable filter(Freeman and Adelson, 1991; Greenspan et al., 1994)와 같은 대안적인 접근과 비교했을 때 다소 원시적임.
- Steerable filter와 이들의 미분은 boundary의 상세한 분석, 영상 압축, 텍스처 분석 등에 있어서 상당히 훌륭한 방법임.
- 반면에 rectangle features는 에지나 bar나 다른 단순한 image 구조가 나타나는 것에 또한 민감하게 반응하며, 이들은 상당히 coarse함.
- steerable filter와는 다르게, 단지 이용할 수 있는 방향이 수직, 수평, 대각임.
- orthogonality 가 이러한 feature set에 대해서는 중심이 아니기 때문에, 본 논문에서는 매우 크며, 다양한 종류를 가지는 rectangle feature set을 생성하도록 선택함.
- 전형적으로 표현은 약 400배 overcomplete함.
- 이러한 overcomplete set은 임의의 비율을 가진 features들과 정교하게 샘플링된 위치를 가진 features들을 제공함
- 경험적으로 rectangle features들의 set은 효율적인 학습을 지원하기 위한 풍부한 이미지 표현을 제공하는 것으로 나타남.
- rectangle feature의 극단적 계산 효율성은 이들의 한계에 대한 충분한 보상을 해줌.
integral image 기법의 계산적인 이점에 대해 느끼기 위해, 인습적인 피라미드 이미지를 계산하는 것과 같은 더욱 더 복잡한 접근을 생각해 봄.
- 대부분의 얼굴 검출 시스템과 마찬가지로, 본 논문의 detector는 input에 대해 여러 scale을 고려하여 scan을 수행함: 얼굴이 검출되는 24 x 24 pixels 크기의 기본 scale 부터 시작해서, 이전 scale 보다 1.25 factor 씩 커지면서 384 x 288 pixel 크기의 이미지에 대한 12 scale 까지 scan이 됨.
- 인습적인 접근은 이전 이미지 보다 약 1.25 배 작게 하면서 총 12개의 이미지 피라미드를 계산하는 것임.
- 그 다음에 하나의 고정된 scale detector는 각각의 이러한 이미지를 가로지르며 scan을 함.
- 피라미드의 계산은 상당한 시간이 요구가 됨.
- 12 level의 이미지 피라미드를 계산하는데 일반적인 하드웨어 상(Intel PIII 700 MHz processor)에서 효율적으로 구현을 하였어도 약 0.05 초의 시간이 소요가 됨.
대조적으로 본 논문에서는 하나의 의미 있는 rectangle featuure set을 정의하였고, 이러한 feature set은 어떤 scale과location에서든지 single feature가 평가되는데는 적은 연산을 사용한다는 속성을 가짐.
- 본 논문에서는 section 4에서 가능한 적은 two-rectangle feature 를 가지고 효율적인 face detector가 구성이 될 수 있다는 것을 볼 것임.
- 이러한 features들의 계산적인 이점을 고려해봤을 때, 전체 이미지에 대한 얼굴 검출 처리는 모든 scale에 대해 15 fps로 완료가 될 수 있으며, 12 level의 이미지 피라미드를 평가하는데 동일한 시간이 소요가 됨.
- 본 논문의 detector 보다 어떠한 방법론도 느리게 동작을 할 것임.
3. Learning Classification Functions
positive 및 negative image로 구성이 되는 feature set과 training set이 주어진 경우에, 대다수의 기계 학습 접근은 classification function을 학습 시키는데 사용이 됨.
- 기계 학습과 관련된 연구:
- Sung and Poggio, 1998 : mixture of Gaussian model 사용
- Rowley et al. (1998) : simple image feature로 구성이 되는 small set + neural network 사용
- Osuna et al. (1997b) : Support Vector Machine 사용
- Roth et al. (2000) : 새롭고 unusual 한 image 표현 + Winnow learning procedure 사용
픽셀의 개수보다 훨씬 더 많은 개수의 각각의 sub-windows와 연관된 160,000개의 rectangle features들이 있음.
- 비록 각각의 feature들이 매우 효율적으로 계산이 된다 하더라도, 완벽한 set에 대한 계산은 상당히 expensive 함.
- 실험을 통해서 나타난 hypothesis: 적은 수의 features들이 하나의 효율적인 classifier를 구성하기 위해서 결합될 수 있음. 주요한 challenge는 이러한 features 들을 찾는 것임.
본 논문의 시스템에서는 AdaBoost의 변종이 feature를 선택하고 분류기를 훈련 시키는데 사용이 됨(Freund and Schapire, 1995).
- 원래의 AdaBoost 학습 알고리즘은 단순한 학습 알고리즘의 분류 성능을 boost하기 위해서 사용이 되었음(예를 들면, 단순한 perceptron의 성능을 boost 하는데 사용이 됨)
- 하나의 강 분류기를 만들기 위해서 약 분류 함수의 collection을 결합함으로써 수행이 됨.
- boosting 이라는 언어의 관점에서 단순한 학습 알고리즘은 하나의 "weak learner" 라고 불림.
- 예를 들어, perceptron 학습 알고리즘은 가능한 모든 perceptron set에 대해 탐색을 수행하고 가장 낮은 분류 에러를 가지는 perceptron을 반환함.
- learner를 weak 하다고 부르는 이유는 training data를 잘 분류하기 위한 최고의 분류 함수를 예상할 수 없기 때문임.
- weak learner가 boosting 되기 위해서, 일련의 순서를 가지는 학습 문제를 해결할 수 있도록 호출이 되어짐.
- 첫 번째 학습 round 후에, 이전 약 분류기에 의해서 부정확하게 분류된 샘플들을 강조할 수 있도록 샘플들은 re-weighted 됨.
- 최종적인 강 분류기는 하나의 perceptron 형태를 가지며, 하나의 임계치에 따른 약 분류기의 가중 조합(a weighted combination of weak classifiers)이 됨.
AdaBoost 학습 절차가 제공하는 formal한 보장은 상당히 강하다는 것임.
- Freund 와 Schapire는 강 분류기의 training 에러는 round의 수에 따라 zero exponentially 하게 근접한다는 것을 증명함.
- 일반화 성능에 대한 더욱 더 많은 결과들이 증명이 됨(Schapire et al., 1997)
- 일반화 성능과 관련된 중요한 insight는 샘플의 margin과 연관이 되어 있으며, AdaBoost는 큰 margin을 빠르게 달성할 수 있다는 것임.
인습적인 AdaBoost 절차는 greedy feature 선택 과정으로서 쉽게 이해가 될 수 있음.
- boosting의 일반적인 문제를 고려해봤을 때, 분류 함수에 대한 larget set은 하나의 weighted majority vote를 이용하여 결합이 될 수 있음.
- 어려운 점은 더 큰 weight와 각각의 우수한 분류 함수를 연관 짓고 더 작은 weight와 저조한 분류 함수를 연관 짓는 것임.
- AdaBoost는 우수한 분류 함수를 가진 작은 set을(중요한 다양성을 가지는) 선택하기 위한 aggresive한 메커니즘임.
- 약 분류기와 feature 들 사이의 유사성을 그려봤을 때, AdaBoost는 효율적인 소수의 우수한 features들을(중요한 다양성을 가지는) 끝까지 탐색하기 위한 절차임.
이러한 유사성을 완료하기 위한 하나의 실제적인 방법은 weak learner를 각각이 single feature에 의존적인 분류 함수의 set으로 제한시키는 것임.
- 이러한 목표를 지원하기 위해서, weak learning 알고리즘은 검색을 위한 이미지 데이터베이스 도메인에서 positive 와 negative 샘플을 가장 잘 분리 할 수 있는 single rectangle feature를 선택할 수 있도록 고안되어짐.
- 각각의 feature에 대해서, 최소한의 샘플 개수만이 오분류 될 수 있도록 weak learner는 최적 분류 함수를 위한 임계치를 제공함.
- 약 분류기 (h (x, f, p, theta) )의 구성
- (f): feature, (theta): 임계치, (p): polarity -> 부등식의 방향을 가리킴.
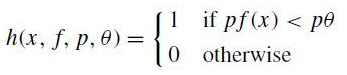
- x: 하나의 image 내에 있는 24 x 24 pixel의 크기를 가지는 sub-window
실제적으로, single feature만으로는 낮은 에러를 가지는 분류 업무를 수행 할 수 없음.
- 초기 과정에서 선택된 feature들은 0.1~0.3 사이의 에러율을 가지게 되며, 다음 round에 선택된 feature들은 분류가 더 어렵기 때문에 0.4~0.5 사이의 에러율을 가지게 됨.
- 아래 Table 1은 학습 알고리즘에 대해서 설명을 하고 있음.

본 논문에서 사용한 약 분류기(임계치가 적용된 single feature)는 single node 를 가지는 decision trees들로 보여질 수 있음.
- 기계 학습과 관련된 문헌들에서는 위와 같은 구조를 decision stumps라고 부르며, boosting decision stumps를 이용한 최초 연구는 Freund and Schapire (1995) 에서 살펴볼 수 있음.
* Table 1에 대한 구체적인 설명
-----------------------------------------------------------------------------------------------------------------------------------
* 약 분류기 h(x, f, p, q)

파라미터:
- x: 샘플 이미지, f: 해당 샘플의 특징을 하나의 수로 표현 시키는 feature
- p: 부등호의 방향을 결정 짓는 인자, theta : 임계치
위의 약 분류기는 샘플 x가 positive 이면 1을 negative 이면 0을 출력함.
- AdaBoost 알고리즘은 다수의 샘플 x를 가지고 훈련을 하여 다수의 약한 분류기 h를 생성하고 이들이 선형으로 결합하여 강한 분류기를 생성함.
- AdaBoost 알고리즘은 아래와 같이 2개의 가중치를 사용함.
1. W_t, i: 샘플에 적용되는 가중치로서 각각의 stage에서 분류가 제대로 안된 샘플들에 대해 다음 stage에 대해서는 더욱 더 큰 가중치를 적용함.
2. alpha_t: 약한 분류기에 적용되는 가중치로서 생성된 분류기의 오류율을 판단하여, 신뢰도가 높은 분류기에 대해서 더 큰 가중치를 적용함.
- AdaBoost의 핵심은 위의 1과 2에 대한 가중치를 결정 하는 것임.
-----------------------------------------------------------------------------------------------------------------------------------
* (x_1, y_1), .... ,(x_n, y_n) 과 같은 이미지 샘플이 주여졌을 경우에
<y_i : 0 또는 1의 값을 가지며 0인 경우는 negative 샘플를, 1인 경우에는 positive 샘플을 나타냄, i는 해당 샘플에 대한 index를 말함.>
<예 (x_1, y_1) : (첫번째 샘플 이미지, 첫번째 인덱스를 가리키는 샘플의 값(0 또는 1)>
* 가중치 w를 초기화시킴. w_1,i = 1/2m, 1/2l
<m: positive 샘플의 개수, l: negative sample의 개수>
* t = 1, ..., T: 1부터 T 회까지 반복하면서...
<여기서 t는 stage(또는 round)의 index를 말함>
1. 가중치 w_t, i 를 정규화시킴

2. 가중치가 적용된 에러(weighted error)를 고려하여 best weak classifier를 선택함.

<Epsilon_t: minimization 된 Epsilon_t는 선택된 약한 분류기 h의 성능을 평가하는 척도이며, 0~1 사이의 값을 가짐.
이 값이 0에 가까우면 좋은 약한 분류기가 되며, 1에 가까우면 나쁜 약한 분류기가 됨. 1에서 가중치 w_t, i를 정규화 시키는 이유는 Epsilon_t 값이 0~1 사이의 확률 값을 갖도록 하기 위해서임>
3. Epsilon_t를 minimization 시키는 f_t, p_t, q_t를 정의함.
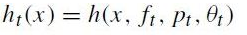
4. 가중치 w_t, i를 갱신함:

<다음 stage에 적용될 각각의 샘플에 대한 가중치를 결정하는 단계로서, beta_t는 다음 stage에 적용되는 각각의 샘플의 가중치를 결정하는 역할을 함. 만약 샘플 x_i가 바르게 분류가 되었다면 e_i = 0 이 되며, 오분류 된 경우에는 e_i = 1 이 됨.>
* 최종적인 강 분류기는 아래와 같음.
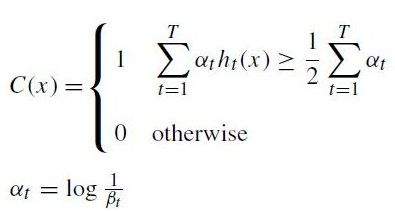
<이 단계에서는 최종적으로 이전에 생성된 약한 분류기들을 선형적으로 결합하여 하나의 강한 분류기를 생성함.
alpha_t : 각각의 약 분류기에 적용되는 가중치를 나타내며 해당 약 분류기에 대한 신뢰도를 나타냄. 즉 분류기 h_t가 신뢰도가 높을수록 높은 alpha_t 값을 갖게 되며, 신뢰도가 낮을 수도록 낮은 alpha_t 값을 가지게 됨.>
-----------------------------------------------------------------------------------------------------------------------------------
3.1. Learning Discussion
Table 1에 설명한 알고리즘은 가능한 weak classifier의 set 들로부터 key weak classifier를 선택하는데 사용이 되어짐.
- AdaBoost 처리는 상당히 효율적인 반면에, weak classifier의 set은 엄청나게 큼.
- 각각의 별개의 feature 및 threshold 조합에 대해 하나의 weak classifier가 존재하기 때문에, KN개의 효율적인 weak classifier가 존재하게 됨(K: feature의 개수, N: 샘플의 개수).
- 샘플의 개수 N에 따른 종속성을 알기 위해서, 하나의 주어진 feature 값에 의해서 샘플들이 정렬되었다는 가정을 함.
- training process에 대해, 정렬된 샘플의 동일 쌍 사이에 놓여 있는 어떠한 두 개의 thresholds들도 동등하게 됨.
- 따라서 별개의 threshold에 대한 전체 개수는 N이 됨.
- N=20000 이며, K = 160000 일 경우에 3백 2십 억개의 별개의 이진 약 분류기가 만들어지게 됨.
wrapper method는 M개의 weak classifier를 활용한 하나의 perceptron을 학습시키는데 사용 될 수 있음.(John et al.,1994)
- wrapper method는 또한 하나의 weak classifier를 각 round 마다 perceptorn에 추가함으로써 증분적으로 수행이 됨.
- 추가된 weak classifier는 현재 set에서 가장 낮은 error를 가지는 perceptron을 만들도록 추가된 것임.
- 매 round 마다 적어도 O(NKN)의 복잡도(또는 60조번의 연산)를 가짐; 모든 binary feature를 열거하기 위한 시간 및 해당 feature를 사용하여 각각의 샘플들을 평가하는데 소요되는 시간을 말함.
- 이것은 perceptron의 가중치를 학습시키는데 걸리는 시간을 무시해버리게 됨.
- 그럼에도 불구하고, 200개의 feature classifier를 학습시키기 위한 최종적인 작업은 10^16번의 연산을 필요로 하는 O(MNKN)와 유사한 복잡도를 가지게 됨.
wrapper method와 같은 경쟁에 있어서 특징 선택 메커니즘으로서 AdaBoost의 주요 이점은 학습 속도임.
- AdaBoost를 사용함으로써, 200개의 feature classiifier는 O(MNL) 또는 10^11번의 연산을 가질 수 있도록 학습될 수 있음.
- 각각의 round 마다, 샘플에 대한 가중치를 사용함으로써 이전에 선택된 feature에 대한 전체적인 의존성은 효율적이며, compact하게 부호화 될 수 있다는 주요 이점이 있음.
- 이러한 가중치는 그 다음에 일정한 시간 내에서 하나의 주어진 weak classifier를 평가하는데 사용이 되어짐.
약 분류기 선택을 위한 알고리즘의 절차
- 각각의 feature에 대해서 샘플들은 feature 값에 기반하여 분류가 됨.
- 그 다음에 feature에 대한 AdaBoost 알고리즘의 최적 threshold는 위에서 분류된 list에 대해 single pass 로 계산이 될 수 있음.
- 분류된 list에 있는 각각의 element에 대해서, 아래와 같은 4개의 sum이 유지 및 평가가 됨.
- 1) T+: positive 샘플에 대한 weight의 전체 sum
- 2) T-: negative 샘플에 대한 weight의 전체 sum
- 3) S+: 현재 샘플 아래의 임계값을 가지는 positive weight의 sum
- 4) S-: 현재 샘플 아래의 임계값을 가지는 negative weight의 sum
분류된 list 내에서 현재 및 이전 샘플 사이의 범위를 쪼갤 수 있는 임계값에 대한 에러는 아래와 같음.

- 위와 같은 sum은 탐색 처리에 의해서 쉽게 갱신이 될 수 있음.
feature selection에 대한 다양한 전략에 대한 내용들(Webb(1999)의 chapter 8 참고)
- 본 논문의 최종 어플리케이션은 매우 공격적인 처리를 요구하기 때문에 대다수의 상당한 features들을 버려야 함.
- 유사한 인식 문제에 있어서 Papageorgiou et al.(1998)는 feature의 variance에 기반한 특징 선택 전략을 제안함.
- 전체 1734개의 features들 중에서 37개의 우수한 결과를 가지는 feature만을 선택하는 기법을 설명함.
- 상당한 감소가 있었던 반면에 모든 이미지의 sub-windows 에 대해 평가된 feature의 개수는 여전히 이론적으로 많았음.
Roth et al. (2000) 는 Winnow exponential perceptron learning rule에 기반한 특징 선택 과정을 제안함.
- 매우 크고, unusual한 feature set을 사용함. 여기서 각각의 pixel들은 d개 차원의 binary vector에 매핑이 됨.
- 각 pixel에 대한 binary vector들은 nd개의 차원을 가지는 하나의 single binary를 형성할 수 있도록 연관되어짐.
- 분류 rule은 perceptron이며, 하나의 가중치를 입력 vector의 각각의 차원에 대해서 할당을 하게 됨.
- Winnow learning 처리는 이러한 대다수의 가중치가 0이 될 때 하나의 해에 수렴을 하게 됨.
- 그럼에도 불구하고 상당한 수의 feature가 남아있게 됨.
3.2. Learning Results
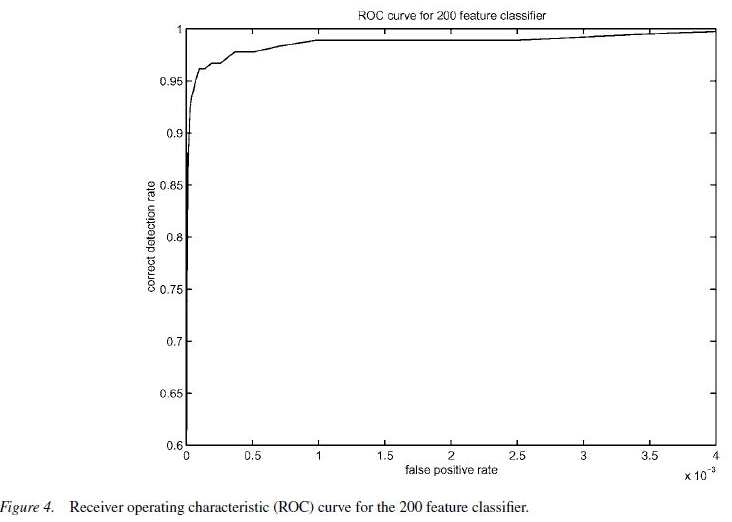
초기의 실험은 그림 4와 같이 괜찮은 결과를 보이는 200개의 features들로부터 하나의 분류기를 구성하는 것으로부터 시작하였음.
- 검출률 95%를 고려해봤을 때, testing dataset에 대해서 분류기는 1/14984의 false positive rate를 보임.
- 이러한 결과가 promising 하지만 실제 어플리케이션을 위한 face detector는 1/1,000,000의 false positive rate를 보일 수 있도록 근접해야 함.
얼굴 검출 작업에 있어서, AdaBoost에 의해 선택된 초기의 rectangle features들은 의미가 있으며 쉽게 설명이 될 수 있음.
- 첫번째 선택된 feature는 눈 영역이 종종 코와 뺨 영역 보다 어둡다는 속성에 집중하는 것으로 보임(그림 5)
- 이러한 feature는 detection sub-windows와 비교했을 때 비교적 크며, 얼굴의 size와 location에 어느정도 insensitive 해야 함.
- 두번째 선택된 feature는 눈 영역은 콧대 영역 보다 어둡다는 속성에 의존적임.

요약하면, 200개의 feature classifier는 rectangle features로부터 구성된 하나의 boosted된 classifier가 얼굴 검출을 위한 효율적인 기법이라는 것에 대한 초기의 근거를 제공함.
- 검출의 관점에서 바라보면, 이러한 결과는 호소력이 있긴 하지만 많은 실세계 문제에 있어서 충분한 조건은 아님.
- 계산의 관점에서 바라보면, 이러한 classifier는 384 x 288 pixel 크기를 가지는 image를 스캔하는데 0.7초가 소요되는 매우 빠른 결과를 보임.
- 불행이도, 검출 성능을 개선시키기 위한 대부분의 간단한 기술들은(classifier에 feature를 추가하는 기법들) 계산 시간을 증가시킴.
4. The Attentional Cascade
이번 section에서는 계산 시간을 급격하게 줄이면서도 증가된 검출 성능을 달성 할 수 있도록 classifier를 하나의 cascade로 구성하기 위한 알고리즘에 대해서 설명을 함.
- key insight: 거의 모든 positive한 instances들을 검출하면서 대다수의 negative한 sub-windows들을 rejection 시킬 수 있는 (더 작은 그래서 더 효율적인) boosted된 classifier를 구성할 수 있다는 것임.
- 낮은 false positive rates를 달성하기 위해서 더욱 더 복잡한 classifier가 호출되기 이전에 단순한 classifier가 대다수의 sub-windows를 rejection 시키는데 사용이 됨.
cascade 상에서 stage는 AdaBoost를 사용하여 classifier를 훈련시킴으로써 구성이 됨.
- two-feature strong classifier로 시작하여, false negative를 최소화 할 수 있는 strong classifier의 threshold를 조절함으로써 하나의 효율적인 face filter를 얻을 수 있음.
- 초기의 AdaBoost threshold는(아래 식 참고) 훈련 data에 대해 낮은 에러율을 보이도록 고안이 되었음.
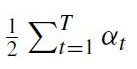
- 더 낮은 threshold는 더 높은 detection rate를 보이며 또한 더 높은 false positive rate를 보임.
- 검증을 위한 훈련 set을 사용하여 측정된 성능에 기반하여, two-feature classifier는 50%의 false positive rate를 가지는 얼굴의 100%를 검출할 수 있도록 조정될 수 있음.
- 그림 5에서는 이러한 classifier에 사용된 2개의 feature에 대해서 설명을 하고 있음.
two-feature classifier의 검출 성능은 얼굴 검출 시스템으로서 받아들이기엔 부족함.
- 그럼에도 불구하고, classifier는 매우 적은 연산을 이용하여 향 후 처리에 필요한 sub-windows의 개수를 상당히 줄일 수 있음:
- 1. rectangle features에 대해 평가를 함(feature 당 6~9번 사이의 array 참조를 요구함)
- 2. 각각의 feature에 대해 weak classifier를 계산함(feature 당 한개의 threshold 연산을 요구함)
- 3. weak classifier를 결합함(feature 당 한번의 곱셈과, 덧셈과, 임계값을 요구함)
two-feature classifier는 합계가 약 60 microprocessor instructions이 됨.
- 어떠한 단순한 필터도 더 높은 rejection rate를 달성할 수 없다고 판단이 됨.
- 그에 비해, 하나의 단순한 image template에 대한 스캐닝 시 sub-windows 당 적어도 20번의 많은 연산을 필요로 하게 됨.
detection process의 전반적인 형태는 본 논문에서 "cascade" 라고 부르는 degenerate decision tree의 형태와 같음.(Quinlan, 1986), 그림 6 참고
- 첫번째 classifier의 positive 결과는 두번째 classifier의 평가가 매우 높은 detection rate를 달성하기 위해 조정되도록 촉진 시킴.
- 두번째 classifier의 positive 결과는 세번째 classifier를 촉진시킴 등등..
- 어떤 시점에서든지 negative 결과는 sub-window의 즉각적인 rejection을 하도록 해줌.

cascade 구조는 하나의 single image 내에서 압도적인 대다수의 sub-windows들이 negative 라는 사실을 반영함.
- 엄밀한 의미에서, cascade는 가장 이른 stage 상에서 가능한 많은 negative들을 rejection 시키려고 시도를 함.
- positive instance가 cascade 상에서 모든 classifier에 대한 평가를 촉진시키긴(trigger) 하지만, 이것은 매우 드문 일임.
거의 대부분 decision tree와 비슷하게, 이후의 classifier들은 모든 이전 stage를 통과한 샘플들을 이용하여 훈련이 되어짐.
- 결과적으로, 두번째 classifier는 첫번째 classifier에 비해서 보다 어려운 문제에 직면하게 됨.=> 첫번째 stage를 통과한 샘플들은 전형적인 샘플들 보다 "harder" 함.
- 더 깊은(depper) classifier에 직면한 더욱 더 어려운 샘플들은 전체 ROC(receiver operating characteristic) 커브를 아래로 향하게 만듬.
- 해당 detection rate에 대해, 더 깊은 classifier는 이에 상응하는 더 높은 false positive rate를 가지게 됨.
4.1. Training a Cascade of Classifiers
cascade design process 는 detection 및 performance goal 이라는 하나의 set으로부터 driven 되어짐.
- 얼굴 검출 관련 연구들에 있어서, 과거의 시스템들은 우수한 검출률(85~95%)과 상당히 낮은 false postive rate(10^-5 또는 10^-6)를 달성함.
- cascade의 stage 개수와 각 stage의 크기는 계산을 최소화 하면서도 유사한 검출 성능을 달성 할 수 있도록 충분해야 함.
하나의 훈련된 classifiers의 cascade가 주어졌을 때, 해당 cascade의 false positive rate는 아래와 같음.
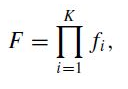
- <F: cascaded classifier의 false positive rate, K: classifier의 개수, f_i : stage를 통과하여 도달된 i번째 classifier 샘플에서의 false positive rate>
detection rate는 아래와 같음.
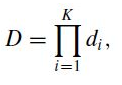
- <D: cascaded classifier의 detection rate, K: classifier의 개수, d_i : stage를 통과하여 도달된 i번째 classifier 샘플에서의 detection rate>
전반적인 false positive 및 detection rate에 대한 구체적 목표를 고려했을 때, target rate는 cascade process 내 각각의 stage에 대해 결정이 될 수 있음.
- 예를 들어, detection rate 0.9는 만약 각 stage가 0.99의 detection rate를 가지고 있다면 10개 stage classifier에 의해서 달성이 될 수 있음.(0.9 = 0.99^10 이기 때문임)
- 이러한 detection rate를 달성하는 것이 벅찬 일이긴 하지만, 각 stage는 단지 약 30% 정도의 false positive rate만 달성하면 된다(0.30^10 = 6 x 10^-6)는 사실에 의해서 쉽게 가능하게 됨.
실제 이미지를 스캔할 때 평가된 feature의 개수는 필연적으로 하나의 확률 처리가 됨.
- 어떤 주어진 sub-window 든지 window가 negative로 결정되거나, 또는 거의 드문 경우지만 window가 각각의 test를 통과하여 성공하고 positive로 labeling 될 때까지 cascade를 통하여 아래로 향해갈 수 있음.
- 이러한 처리에 있어서 예상되는 behavior는 전형적인 test set에 대한 image windows의 분포에 의해서 결정이 될 수 있음.
- 각각의 classifier에 대한 key measure는 해당 classifier의 "positive rate" 가 됨. 여기서 positive rate는 잠재적으로 얼굴을 포함하고 있다고 labeling 된 windows의 비율을 말함.
예상된 feature의 개수는 아래와 같이 평가가 되어짐.

- <N: 평가된 feature의 예상된 개수, K: classifier의 개수, p_i: i번째 classifier의 positive rate, n_i: i번째 classifier 에서의 feature의 개수>
- 흥미 있게도, 얼굴은 극도로 드물기 때문에 "positive rate" 는 효율면에서 false positive rate와 동등함.
cascade의 각각의 element가 훈련이 되는 과정에서 몇 가지 주의해야 할 것들이 있음.
- 섹션 3에 기술한 Adaboost 학습 절차는 단지 에러를 최소화도록 시도하며, large한 false positive rate를 낮추면서 높은 detection rate를 달성하도록 설계 되어 있지 않음.
- 이러한 에러를 trading off 시키기 위한 단순하며 인습적인 전략은 AdaBoost에 의해서 만들어진 perceptron의 threshold를 조절하는 것임.
- 더 높은 thresholds는 적은 false positive를 가지는 classifier를 만들지만 더 낮은 detection rate를 보이게 됨.
- 반대로 더 낮은 threshold는 많은 false positive를 가지는 classifier를 만들지만 더 높은 detection rate를 보이게 됨.
- 이러한 점에서, 분명하지 않지만, 이러한 방식으로 threshold를 조절하는 것은 Adaboost에서 제공된 훈련 및 일반화 보증에 대해 보존을 하게 됨.
전반적인 training process는 2개 타입의 tradeoff를 포함하게 됨.
- 대부분의 경우에 있어서, 더 많은 feature를 가진 classifier는 높은 detection rate와 낮은 false positive rate를 달성할 것임.
- 동시에, 더 많은 feature를 가진 classifier는 더 많은 계산 시간을 요구하게 됨.
- F와 D에 대한 목표가 주어졌을 때, 원칙적으로 예상되는 feature의 개수 N를 최소화 시킬 수 있도록 아래와 같은 요소의 tade-off를 고려하여 최적화 프레임워크를 정의할 수 있음.
- <classifier stage의 개수, 각 stage 에서의 feature의 개수 n_i, 각 stage에 대한 threshold>
- 하지만 불행히도, 이러한 최적 상태를 찾는 것은 극도로 어려운 문제임.
실제적으로, 높은 효율성을 보이는 하나의 효율적인 classifier를 만들기 위해 아주 단순한 프레임워크가 사용이 됨.
- 사용자는 아래와 같은 요소를 선택해야 함.
- 1. f_i 에 대해 최대로 허용할 수 있는 비율
- 2. d_i 에 대해 최소로 허용할 수 있는 비율
- cascade의 각각의 layer는 현재 레벨에 대해 목표로 하는 detection rate와 false positive rate가 충족될 때까지 features의 개수를 증가 시키면서 (Table 1에 기술한) Adaboost에 의해서 훈련이 되어짐.
- rate는 현재 detector를 validation set에 대해 test 함으로써 결정이 되어짐.
- 만약 목표로 하는 전체적인 false positive rate가 아직 충족되지 않았다면, 다른 layer가 cascade에 추가가 됨.
- 다음 layer를 훈련하기 위한 negative set은 현재 detector를 어떠한 얼굴의 instance도 포함하고 있지 않은 image set에 적용하여 발견된 모든 false detection을 수집함으로써 얻을 수 있음.
- 이 알고리즘에 대한 자세한 설명은 아래 table 2와 같음.

-----------------------------------------------------------------------------------------------------------------------------------
Table 2. cascaded detector를 구축하기 위한 훈련 알고리즘 설명
* 사용자는 아래와 같이 3개의 값을 먼저 설정을 함. 즉 알고리즘의 input 이 됨.
- f: layer 당 최대로 허용할 수 있는 false positive rate
- d: layer 당 최소로 허용할 수 있는 detection rate
- F_target: 목표로 하는 전체 false positive rate
* P: positive 샘플들로 구성된 set, N: negative 샘플들로 구성된 set 을 의미함.
* 아래와 같이 F_0 와 D_0 와 i 를 초기화 시킴. (F_0와 D_0는 각각 0번째 분류기에 대한 false positive rate와 detection rate를 말함)
- F_0 = 1.0, D_0 = 1.0, i=0
* while( F_i > F_target) (i 번째 분류기에 대한 False positive rate가 목표로 하는 전체 False positive rate보다 크다면(즉 F_target를 충족하지 못하는 경우라면))
- i <- i+1 (분류기에 대한 index 를 1씩 증가시킴)
- n_i = 0; F_i = F_i-1 (i 번째 분류기에서의 특징의 개수 n_i 을 0으로, i 번째 분류기에서의 false positive rate인 F_i 를 F_i-1 로 초기화 시킴)
- while( F_i > f x F_i-1) ("i 번째 분류기에 대한 False positive rate인 F_i" >"layer 당 최대로 허용할 수 있는 false positive rate인 f x 위에서 초기화된 F_i-1" 라면)
- ** n_i <- n_i + 1 (i 번째 분류기에서의 특징의 개수 n_i 를 1씩 증가시킴)
- ** AdaBoost를 이용한 n개의 특징을 가진 분류기를 훈련시키는데 P 와 N을 사용함.
- ** F_i와 D_i를 결정하기 위해서 현재의 cascaded된 분류기를 validation set에 대해 평가를 함.
- ** 현재 cascaded된 분류기가 적어도 d x D_i-1의 detection rate를 가질 때까지 i 번째 분류기에 대한 임계값을 감소시킴.
- N <- ∅ (N을 empty set으로 만들어버림)
- 만약 (F_i > F_target) 라면
- 현재 cascaded된 detector를 비얼굴 이미지의 집합에 대해서 평가를 하고, false detection들은 위에서 비어진 집합 N에 넣어줌.
-----------------------------------------------------------------------------------------------------------------------------------
4.2. Simple Experiment
cascaded 접근에 대한 가능성을 탐험하기 위해서, 두 개의 단순한 detector가 훈련이 되어짐.
- 1) 한덩어리로 된 200개의 특징을 가지는 분류기
- 2) 20개의 특징을 가지는 분류기 10개를 cascade로 만듬.
- cascade 내에 있는 첫번째 stage의 분류기는 5000개의 얼굴과 비얼굴 이미지로부터 랜덤하게 선택된 10000개의 비얼굴 sub-windows를 이용하여 훈련이 되어짐.
- cascade 내에 있는 두번째 stage의 분류기는 동일한 5000개의 얼굴과 추가로 첫번째 분류기에서 발생한 5000개의 false positive에 대해서 훈련이 되어짐.
- 이러한 처리는 이후의 stages들이 이전 stage의 false positive를 이용하여 훈련될 수 있도록 계속 되어짐.
1)의 분류기는 cascaded된 분류기의 모든 stage를 훈련 시키는데 사용된 모든 샘플들의 조합에 대해서 훈련이 되어짐.
- cascaded된 분류기에 대한 참고 없이는, 1)의 분류기를 훈련시키기 위해서 비얼굴의 훈련 샘플에 대한 set을 선택하는 것이 어려울 수 있다는 것을 기억해야 함.
- 물론, 본 논문의 모든 비얼굴 이미지로부터 모든 가능한 sub-windows를 사용할 수 있었으나 이것은 훈련 시간을 실행 불가능 할 정도로 길게 만들어버림.
- 2)의 분류기가 사용하는 순차적인 방식은 쉬운 샘플들은 버리고 "hard"한 샘플들에 대해서 집중함으로써 비얼굴 훈련 set을 줄이도록 효율적으로 훈련이 됨.
그림 7은 1)과 2)의 성능에 대한 비교 결과를 ROC 커브로 나타내고 있음.
- 정확도의 관점에서는 적은 차이가 있지만, 속도의 관점에서는 상당한 차이가 있음.
- 2)의 분류기는 첫번째 stage에서 대부분의 비얼굴을 버리기 때문에(그 결과 이후의 stage에서는 버려진 비얼굴은 절대로 평가가 되지 않음) 거의 10배나 빠름.

4.3. Detector Cascade Discussion
detector를 분류기의 일련의 sequence로서 훈련을 시키는데는 숨겨진 이점이 있음.
- 많은 features들을 가진 하나의 커다란 분류기에 대한 훈련을 생각할 수 있으며, 그 다음에 feature의 부분 합을 살펴보고, 만약 부분합이 적절한 임계값 아래라면 계산을 초기에 멈춤으로서 수행 시간을 가속 할려고 시도할 것임.
- 위와 같은 접근에 있어서 하나의 단점은 훈련을 수행할려면 negative 샘플에 대한 훈련 set이(10,000개~100,000개) 비교적 작아야만 한다는 것임.
- Cascaded detector를 이용하여, cascade의 최종 layer는 cascade 상에서 실패한 좀 더 초기의 layer에 있는 만개의 negative 샘플들의 set을 찾기 위해 수억개의 negative 샘플들을 통하여 효율적으로 볼 수 있음.
- 따라서 negative 샘플들은 상당히 커야 하며, cascaded detector에게 어려운 샘플들에 좀 더 초점을 맞춰야 함.
얼굴 검출 시스템에 있어서 cascade와 유사한 관점은 Rowley et al. (1998)의 연구에서 나타나 있음.
- Rowley은 2개의 neural networks를 가지고 훈련을 수행함.
- 하나의 neural network는 적당히 복잡하였으며, 영상의 작은 영역에 대해 초점을 맞추고 더 낮은 false positive rate를 갖도록 얼굴을 검출함.
- 다른 하나의 neural network는 훨씬 더 빠르며, 영상의 큰 영역에 대해 초점을 맞추고 더 높은 false positive rate를 갖도록 얼굴을 검출함.
- Rowley는 또한 두번째 neural network를 더 느리지만 더욱 더 정확한 network에 대한 후보 영역을 찾기 위해 이미지를 미리 차단하는 용도로 사용함.
- 비록 정확하게 결정하기 어렵지만, 얼굴 검출 시스템에 있어서 Rowley의 두개의 network를 사용하는 전략은 존재하는 얼굴 검출기 중에서 가장 빠르다고 할 수 있음.
- 본 논문에서는 유사한 접근을 사용했지만 위의 연구에서 사용한 2개의 stage cascade를 38개의 satage를 포함할 수 있도록 확장시킴.
cascaded detection process의 구조는 본질적으로 degenerate decision tree와 같음. 그러한 의미해서 Amit and Geman (1999)의 연구와 관련이 있음.
- 그리고 이에 대한 전략을 이야기 하고 있음.
본 논문에서 사용한 detector와 feature의 형태는 극도로 효율적이며, 모든 scale 과 location에 대해 detector를 평가하는데 드는 비용을 분할 상환하는 방식이기 때문에 위의 연구(Amit and Geman (1999))처럼 이미지 내에서 에지를 찾고 그룹핑 하는 방식 보다 훨씬 더 빠름.
Fleuret and Geman (2001)는 특정한 scale 및 location에 대해 얼굴이 있는지 여부를 확인하기 위해서 "chain"을 이용한 test를 사용하는 기법을 제안함.
- 그리고 이에 대한 전략을 이야기 하고 있음.
5. Results
이번 섹션에는 최종적인 얼굴 검출 시스템에 대해서 설명을 하며, cascaded detector의 구조 및 훈련과 대량의 실세계 데이터 셋을 이용한 실험 결과에 대해서 논의함.
5.1. Training Dataset
training set: 손으로 labeling 한 4916개의 얼굴 set으로서 24 x 24 pixel의 해상도를 갖도록 scaling 되고 alignment 됨.
얼굴은 웹에서 랜덤하게 다운 받은 이미지로부터 추출이 됨.
- 그림 8은 이에 대한 예를 나타내고 있음.

- training face는 단지 rough하게 alignement 됨.
- 입과 턱 사이의 약 절반과 눈썹 바로위의 얼굴 주변에 bounding box를 갖는 얼굴이 되도록 align 되어짐.
- 이러한 bounding box는 50% 확대되고 그 다음에 cropping되고 24 x 24 pixel의 크기를 가지도록 scaling 됨.
- 더 이상의 alignment는 수행되지 않음(예를 들면 눈은 align 되지 않음)
- 이러한 샘플들은 Rowley et al. (1998) or Sung and Poggio (1998) 등의 연구에서 사용한 샘플 보다 더 많은 head를 포함하고 있는 샘플임을 기억할 것.
- 초기의 실험은 또한, 얼굴이 보다 tight하게 cropped된 16 x 16 pixel의 훈련 이미지를 사용하여 실험이 되었는데 이는 사소하게 나쁜 결과를 얻음.
- 짐작컨데, 24 x 24 샘플은 턱과 뺨과 머리카락 라인의 윤곽 등과 같은 추가의 시각적인 정보를 더 포함하고 있으며 이러한 정보가 정확도를 개선하는데 도움이 되었을 것이라고 추정이 됨.
- 사용한 feture의 본질 때문에, 더 큰 크기를 가진 sub-window들은 성능을 늦추지 않을 것임.
- 사실, large sub-windows 에 포함된 추가적인 정보는 detection cascade에서 초기의 비얼굴을 rejection 하는데 사용될 수 있음.
5.2. Structure of the Detector Cascade
최종적인 detector는 38개의 layer를 가진 cascaded classifier 가 되며, 전체 6060개의 features를 포함하고 있음. cascade 상의 첫번째 분류기는 2개의 feature를 사용하여 구성이 되며, 100%에 근접하도록 올바르게 얼굴을 검출하면서 약 50%의 비얼굴을 rejection 시킴.
- 다음의 두번째 layer는 25개의 feature를 가진 분류기이며, 세번째 layer는 50개의 특징을 가진 분류기이며,.. Table 2에 있는 알고리즘에 따라서 선택된 다양한 서로 다른 개수의 feature를 갖게 됨.
- layer 당 feature의 개수에 대한 특정한 선택은 feature의 개수가 false positive rate의 의미 있는 감소가 있을 때까지 증가 되도록 하는 시행 착오에 의해서 얻어지게 됨.
- 여전히 높은 detection rate를 유지하면서 검증 set에 대한 false positive rate가 거의 zero가 될 때까지 더 많은 level들이 추가가 되어짐.
- layer의 최종 개수와 각 layer의 크기는 최종 시스템의 성능에 결정적인 요소는 아님.
- 본 논문에서 layer 당 feature의 개수를 선택하기 위해 사용한 절차는 detector에 대한 훈련 시간을 줄일 수 있도록 (첫번째 7개의 layer에 대해) 사람의 개입에 의해서 guide를 받음.
- Table 2에 기술한 알고리즘은 손으로 layer 당 feature의 최소 개수를 명시함으로써 그리고 한번에 1개 이상의 feature를 추가함으로써 계산적인 부담을 덜 수 있도록 사소하게 변경이 되었음.
- 나중의 layer에 있어서는, 검증 set에 대한 테스트 이전에 25개의 feature가 한번에 추가가 되었음.
cascade의 첫번째 레벨을 훈련시키는데 사용된 비얼굴의 sub-windows는 얼굴을 포함하고 있지 않은 9500개의 image set에서 랜덤하게 선택되어 수집됨.
- 다음의 layer를 훈련시키는데 사용된 비얼굴 샘플은 커다란 비얼굴 이미지들을 가로지르며 부분적인 cascade를 scanning 하고 false positives를 수집함으로써 얻을 수 있었음.
- 각 layer 당 최대 6000개의 비얼굴 sub-windows가 수집되어짐.
- 9500개의 비얼굴 이미지에는 대략 3억 5천개의 비얼굴 sub-windows가 포함되어 있음.
전체 38개의 layer를 가진 detector를 훈련하는데 소요된 시간은 약 1주 정도 걸렸음(single 466 MHz AlphaStation XP900).
- 이후에 하루만에 완벽한 cascade를 훈련시키는게 가능할 수 있도록 알고리즘의 병렬화를 수행하였음.
5.3. Speed of Final Detector
cascaded detector의 속도는 스캔된 window 당 평가된 feature의 개수와 직접적으로 관련이 있음.
- 섹션 4.1에서 기술했듯이, 평가된 feature의 개수는 스캔된 이미지에 의존적임.
- 커다란 대다수의 sub-windows 들이 cascade의 첫번째 2개의 stage에서 버려지기 때문에, sub-window 당 전체 6060개의 feature 로부터 평균 8개의 feature가 평가가 되어짐.MIT + CMU (Rowley et al., 1998, DB)
- 700 Mhz Pentium III processor에서, 본 논문의 얼굴 검출기는 384 x 288 pixel의 image를 약 0.067 초에 처리할 수 있음.
- 이것은 Rowley-Baluja-Kanade detector (Rowley et al., 1998) 연구에 비해서 약 15배가 빠르며, Schneiderman-Kanade detector (Schneiderman and Kanade, 2000) 보다 약 600배가 빠름.
5.4. Image Processing
훈련에 사용된 모든 샘플 sub-windows들은 서로 다른 빛 상태의 영향을 최소화하도록 variance가 정규화 되어짐.
- 그러므로, 검출을 잘 하기 위해서는 정규화는 필수적임.
- 하나의 image sub-windows에 대한 variance는 integral image의 쌍을 이용하여 빠르게 계산이 될 수 있음.
- 아래와 같은 식을 생각해 봄.

- <sigma: 표준 편차, m: 평균, x : sub-windows 내에 있는 픽셀의 값>
- sub-windows의 평균은 integral image를 이용하여 계산이 될 수 있음.
- 픽셀값을 제곱한 후의 합은 제곱된 image에 대한 하나의 integral image를 이용하여 계산이 될 수 있음.(예를 들면, 2개의 integral image들은 scanning process에서 사용이 됨)
- scanning 동안에, 이미지 정규화의 효과는 픽셀 값에 대한 연산 보다는 특징 값을 곱함으로써 완성이 될 수 있음.
5.5. Scanning the Detector
최종적인 detector는 multi scale과 location에서 이미지를 가로지르면서 스캔을 하게 됨.
1) scaling에 대한 내용
- scaling의 경우 이미지 자체를 scaling 하기보단 detector 자체를 scaling 하면서 수행이 됨.
- 이러한 처리는 feature가 어떤 scale에서든지 간에 동일한 비용으로 평가가 될 수 있기 때문에 타당한 방법임.
- scale factor를 1.25로 했을 때 우수한 검출 성능을 얻을 수 있었음.
2) location에 대한 내용
detector는 또한 location을 가로지르면서 스캔을 하게 됨.
- 그 다음의 location은 windows을 delta의 몇 pixel 만큼 shifting 함으로써 얻을 수 있음.
- 이러한 shifting 과정은 detector의 scale에 의해서 영향을 받음: 만약 현재 scale을 s라고 할 경우 window는 s[delta] 만큼 shift 되며, 여기서 []는 rounding 연산을 말함.
delta의 선택은 detector의 속도와 정확도 모두에 영향을 줌.
- 훈련 이미지가 translational variability를 가지고 있기 때문에 이미지 내 작은 shift 에도 불구하고 학습된 detector는 우수한 검출 성능을 달성함.
- 결과적으로 detector sub-window는 한번에 1픽셀 이상 옮겨질 수 있음.
- 하지만, 1픽셀 이상의 step size는 detection rate를 사소하게 감소키시는 경향이 있으며, 반면에 false positive의 개수도 줄어드는 경향을 보임.
- 본 논문에서는 2개의 다른 step size에 따른 결과를 보임.
5.6. Integration of Multiple Detections
최종적인 detector가 translation 및 scale의 작은 변화에 대해서는 둔감하기 때문에 multiple detection은 스캔된 이미지 상에서 각각의 얼굴 주변에 발생을 하게 됨.
- 동일한 곳에서 몇몇 타입의 false positive가 trure로 인식되어서 나타남.
- 실제적으로, 얼굴 당 하나의 최종적인 detection 결과만을 반환하는 것이 타당함.
- 끝단에서는 겹쳐진 detection 결과를 하나의 detection 결과로 결합하기 위해 검출된 sub-windows에 대해 후처리를 하는 것이 유용함.
본 논문의 실험에서는 검출은 하나의 매우 단순한 방식으로 결합이 되어짐.
- detetion 결과의 set은 먼저 분리할 수 있는 subset으로 분할이 됨.
- 만약 이들의 bouding 영역이 겹쳐있다면, 2개의 detection 결과는 동일한 subset을 가리키게 됨.
- 각각의 partitions들은 하나의 최종적인 detection 결과를 만들어 냄.
- 최종적인 bouding 영역의 코너는 detection 결과 set 내에 있는 모든 검출에 대한 코너들의 평균이 됨.
몇몇 경우에 있어서, 이러한 후처리는 false positive의 겹쳐진 subset 이 하나의 detection 결과로 줄어들기 때문에 false positive의 개수를 감소시킴.
5.7. Experiments on Real-World Test Set
본 논문에서 사용한 test data set의 구성
- MIT + CMU의 정면 얼굴 test set(Rowley et al., 1998)을 이용함.
- 이러한 507개의 labeling 된 정면 얼굴을 가진 130개의 이미지로 구성이 되어 있음.
본 논문에서 사용한 ROC 커브에 대한 이야기를 함.
false positive rate를 계산하기 위해서, 단순히 스캔된 sub-windows의 전체 개수로 나눔.
- delta = 1.0 이며, starting scale = 1.0 인 경우에, 스캔된 sub-windows의 개수는 75,081,800 개임.
- delta = 1.5 이며, starting scale = 1.25 인 경우에, 스캔된 sub-windows의 개수는 18,901,947 개임.
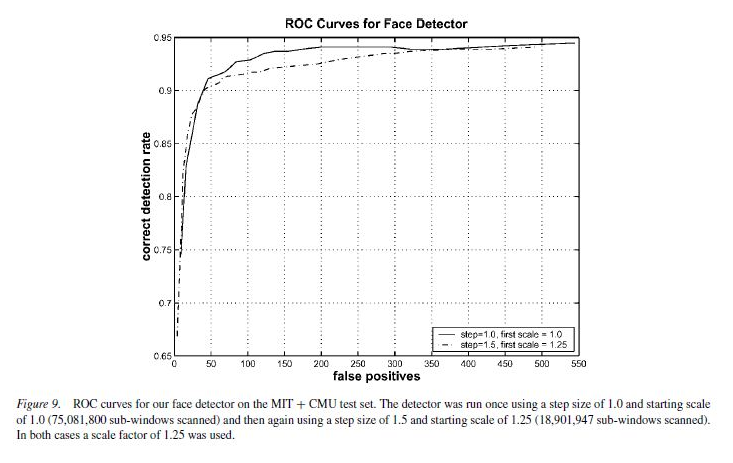
불행이도, 얼굴 검출과 관련하여 이전에 알려진 결과들은 하나의 연산 체제만을 포함하고 있음.(예. ROC 커브에 대한 single point)
- 비교를 위해, 본 논문에서 제안한 detector와 다른 시스템에서 보고한 동일한 false positive rate에 대해 detection rate를 목록화 함.
- 본 논문의 방법과 다른 논문들의 방법에 있어서 Table 3의 목록은 false detection의 개수가 변화함에 따라 detection rate에 주는 영향을 나타내고 있음.
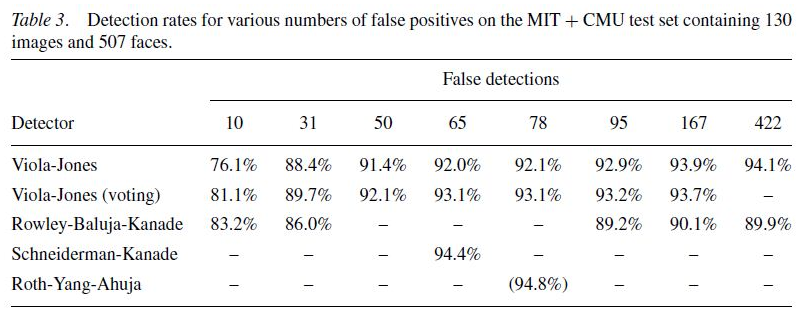
- 위 테이블의 결과에 대해 분석하는 이야기를 하고 있음.
- 위의 결과 중에서 어떤 방법이 best 하다는 것은 언급하지 않고 있음.
- false positive의 개수가 가장 많은 상황에서(422개) 본 논문의 방법이 가장 우수한 detection rate(94.1%)을 보임.
- false positive의 개수가 가장 적은 상황에서는(10개) 다른 논문의 방법이 본 논문의 방법보다 우수한 detection rate(83.2%)을 보임.
그림 10은 MIT + CMU test set으로부터 몇개의 test 이미지를 이용하여 본 논문에서 제안한 face detector를 적용한 결과를 보여주고 있음.

5.7.1. A Simple Voting Scheme Further Improves Results.
가장 우수한 결과는 3개의 detector의 조합을 통해서 얻을 수 있었음.
- 1. 서로 다른 초기의 negative 샘플을 사용하고 2. negative vs positive error에 대해 사소하게 나마 서로 다른 가중치를 적용하고 3. classifier size에 대한 false positives의 tadeoff를 위해 사소하게 나마 서로 다른 criteria를 사용함.
- 이러한 3개의 시스템은 최종 작업을 위해서 유사한 방식으로 수행이 되었지만, 몇몇 경우에 있어서 에러는 서로 달랐음.
- 이러한 3개의 detector를 통해 얻어진 검출 결과는 적어도 3개의 detector 중에서 2개의 detector에 대한 동의를 얻으면, 검출 결과를 유지함으로써 결합이 되어짐.
- 이것은 더 많은 false positives를 제거할 수 있을 뿐만 아니라 최종 detection rate를 개선시킬 수 있음.
- detector의 error가 uncorrelated 하기 때문에, 결합 결과는 측정이 가능하며, 결합 결과는 best한 single detector 보다 어느정도 개선이 될 수 있었음.
5.7.2. Failure Modes.
상당한 양의 test image에 대해 본 논문의 face detector의 성능을 관측하면서 몇 가지 서로 다른 실패 모드가 있다는 것을 발견함.
1. 회전 변화에 대한 측면을 이야기 하고 있음.
본 논문의 face detector는 얼굴이 정면이며 수직인 샘플을 이용하여 훈련이 되어짐.
- 얼굴은 상당히 rough하게 align 되었기 때문에 약간의 회전 등의 변화가 있음.
- 본 연구의 일반적 관측에 의한 성능은 face detector가 얼굴을 plane 내 tilt up의 경우 +/- 15도 까지, out of plane 내 +/- 45 도 까지 검출할 수 있음.
- 이 이상의 회전에 대해서는 detector는 신뢰할 수 없게 됨.
2. 조명 변화에 대한 측면을 이야기 하고 있음.
- 얼굴에 눈에 거슬릴정도의 역광조명이 발생하는 경우에는 얼굴이 매우 어둡게 되며, 반면에 배경은 비교적 밝기 때문에 실패를 야기시킴.
- 이러한 상황에서는 강건한 statistics를 기반으로 하는 nonlinear variance 정규화를 사용함으로써 outlier를 제거하면서도 detection rate를 개선시킬 수 있음.
- 하지만 문제는 이러한 정규화 접근은 본 논문에서 제안한 integral image framework에 있어서 계산 비용을 상당히 증가시킬 수 있다는 것임.
3. 가려짐에 대한 이야기를 하고 있음.
- 얼굴에 상당한 가려짐이 발생한 경우에 실패를 하게 됨.
- 예를 들어서 눈이 가려져 있다면 보통 실패를 하게 되며, 입은 그렇게 중요하지 않기 때문에 입이 가려진 얼굴은 보통 여전히 검출이 가능하게 됨.
6. Conclusions
본 논문에서는 높은 검출 정확도를 유지하면서 계산 시간을 최소화 할 수 있는 얼굴 검출 시스템을 제안함.
- 제안된 시스템은 이전 연구들보다 약 15배가 빠름.
- 제안된 시스템은 보행자나 자동차와 같은 다른 객체를 검출하기 위한 효율적인 detector가 될 수 있음.
본 논문의 기여에 대한 설명
1. Integral Image
- integral image를 이용하여 풍부한 set의 image feature를 계산하기 위한 새로운 기법을 제안함.
- 진짜 scale invariance를 달성하기 위해서, 거의 대부분의 모든 얼굴 검출 시스템은 multiple image scale에 대해서 연산을 함.
- 반면에 integral image는 multi-scale의 image pyramid에 대한 계산의 필요성을 제거함으로써 얼굴 검출에 요구되는 초기의 image processing을 상당히 줄일 수 있음.
- integral image를 사용함으로써, 하나의 image pyramid가 계산되어지는데 거의 동일한 시간이 소요되면서 얼굴 검출을 완료할 수 있음.
- integraim image는 Haar-like feature(Papageorgiou et al. (1998))를 사용하는 다른 시스템에서 즉각적인 사용성을 가져야 하며, Haar-like feature의 값이 되는데 영향을 줄 수 있다는 것을 예측할 수 있음.
- 초기의 실험은 하나의 유사한 feature set은 또한 얼굴의 표정과 머리의 위치 또는 객체의 자세 결정 등과 같은 파라미터 추정과 같은 업무에 효율적이다는 것을 보여줌.
2. AdaBoost learning algorithms
- feature 선택을 위해 AdaBoost를 이용하여 단순하고 효율적인 classifier가 계산적으로 효율적인 feature로부터 구축이 될 수 있다는 것임.
- 이러한 classifier는 얼굴 검출에 있어서 명백하게 효율적인 것이며, 자동차나 보행자 검출과 같은 다른 분야에서도 효율적일 것이라는 것을 확신함.
- 더욱이, feature 선택을 위해 공격적이며 효율적인 기법을 사용하는 아이디어는 넓고 다양한 학습 task에도 영향을 줄 수 있을 것임.
- feature 선택을 위해 하나의 효율적인 도구가 주어졌을 경우에, 시스템 고안자는 학습 처리를 위해 입력으로서 매우 크고 매우 복잡한 feature set을 정의하는 것으로부터 자유롭게 됨.
- 그럼에도 불구하고 실행 시간 때는 평가를 위해 단지 작은 개수의 feature 만을 필요로 하기 때문에 classifier의 결과는 계산적으로 효율적임.
- 종종 classifier의 결과는 상당히 단순할 수 있음; 복잡한 feature로 구성이 되어 있는 커다란 set에서 분류 문제의 구조를 capture 할 수 있는 몇몇의 결정적인 feature가 발견되기 쉬움.
3. Cascaded Classifier
- 검출 정확도를 개선시키면서도 계산 시간을 급격하게 줄일 수 있도록 classifier을 이용하여 하나의 cascade를 구성하는 기법을 제안함.
- cascade의 초기 stage는 이후 처리에서는 promising한 영역에 대해 초점을 맞추도록 대다수의 이미지를 rejection 시키도록 고안되었음.
- 하나의 매우 중요한 점은 제안된 cascade는 매우 단순하며, 구조에 있어서 homogeneous 하다는 것임.