문서 버전
발표 버전
Link: https://arxiv.org/pdf/2004.10934.pdf
Abstract
Convolutional Neural Network (CNN)의 정확도 개선을 위한 수많은 features들이 존재
이러한 feature들의 조합에 대해 대규모 데이터셋을 이용한 실제적 테스트와 결과에 대한 이론적 정당화가 요구됨
몇몇의 features들은 특정한 model에 국한되어 동작하거나, 특정한 problem에 국한되어 동작하거나, 소규모의 데이터셋에 대해서만 동작
반면에 대부분의 model, task, 데이터셋에 적용이 가능한 universal한 features들도 존재
- Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT), Mish-activation
본 연구에서는 아래와 같은 새로운 features들을 적용하고 이들 중 몇개를 조합하여 최신의 결과를 달성
- WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, DropBlock regularization, CIoU loss
- 정확도: MS COCO 데이터셋 기준 43.5% AP(AP_50: 65.7%)
- 속도: Tesla V100 기준 ~65 FPS의 실시간 속도
1. Intoduction
대부분의 CNN 기반 object detector들은 recommendation systems에 대해서만 주로 적용 가능
- 도심지 내 비디오 카메라를 이용한 주차 가능 공간 탐색: 느리지만 정확한 model들이 적용
- 차량 충돌 경고: 빠르지만 부정확한 model들이 적용
정확도와 실시간 속도 모두를 만족하는 object detector가 필요
- recommendation systems뿐만 아니라 stand-alone한 프로세스 관리 및 인력 투입 감소 등에도 사용 가능
- 대부분의 정확한 최신의 neural network들은 실시간으로 동작하지 않고, 큰 mini-batch-size로 여러개의 GPU를 이용한 training이 필요
- 기존 GPU에서 실시간으로 동작하며, training에 한개의 기존 GPU만 필요한 CNN을 만들어서 위와 같은 문제를 해결하고자 함
본 논문의 주요 목적
- BFLOP가 아니라 생산 시스템에서 빠른 속도로 동작하는 object detector를 고안하고 병렬 계산을 최적화 하는 것
- 기존 GPU를 사용하여 training과 test를 수행하는 사람이라면 누구나 그림 1에 표시된 YOLOv4와 같이 실시간, 고품질의 확실한 object detection 결과를 얻을 수 있음

본 논문의 기여
- 효율적이며 강력한 object detection model을 개발: 1080 Ti 또는 2080 Ti GPU를 사용하는 누구나 상당히 빠른 속도로 training이 가능하며, 정확한 object detector를 사용 가능
- detector를 training하는 동안 사용될 수 있는 최신의 Bag-of-Freebies 및 Bag-of-Specials 기법들이 주는 영향에 대해 검증
- 단일 GPU training에 보다 효율적이며 적합하도록, CBN [89], PAN [49], SAM [85] 등을 포함한 최신의 기법들을 수정
2. Related Work
2.1. Object detection models
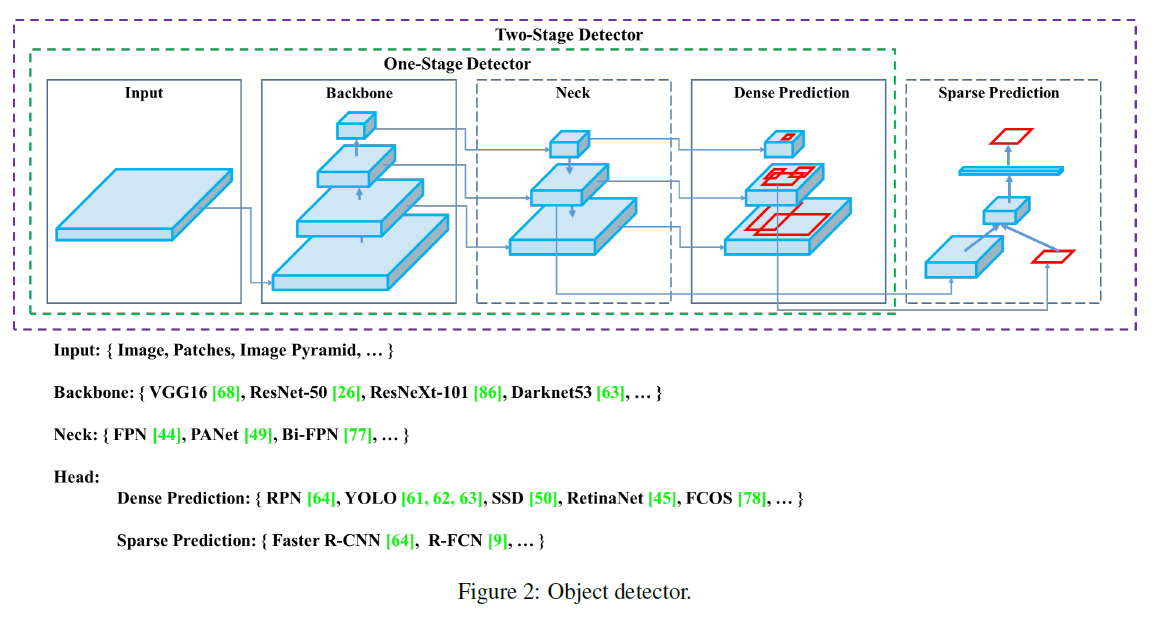
최신의 detector들은 일반적으로 2(backbone, head)개 부분으로 구성
1. backbone: ImageNet을 이용하여 pre-trained됨
- GPU 플랫폼 상에서 동작하는 detector들이 사용하는 backbone들: VGG [68], ResNet [26], ResNeXt [86], DenseNet [30] 등
- CPU 플랫폼 상에서 동작하는 detector들이 사용하는 backbone들: SqueezeNet [31], MobileNet[28, 66, 27, 74], ShuffleNet [97, 53] 등
2. head: object에 대한 class와 bounding boxes를 예측하는데 사용
1) 대표적인 one-stage object detector들:
- anchor-based: YOLO [61, 62, 63], SSD [50], RetinaNet [45] 등
- anchor-free: CenterNet [13], CornerNet [37, 38], FCOS [78] 등
2) 대표적인 two-stage object detector들:
- anchor-based: R-CNN [19] 시리즈(fast R-CNN [18], faster R-CNN [64], R-FCN [9], Libra R-CNN [58]) 등
- anchor-free: RedPoints [87] 등
3. neck: 최근에 개발된 detector들은 backbone과 head 사이에 약간의 layers들을 삽입하였으며, 이러한 layers들은 보통 서로 다른 stages들로부터 온 feature maps들을 모으는데 사용
- 보통, 몇몇의 bottom-up paths와 top-down paths들로 구성되며 이러한 메커니즘을 구비한 Network는 아래와 같음
- Feature Pyramid Network (FPN) [44], Path Aggregation Network (PAN) [49], BiFPN [77], NAS-FPN [17] 등
4. others: object detection을 위해 새로운 backbone이나 새롭게 전체 model을 구축한 연구들
- 새로운 backbone: DetNet [43], DetNAS [7] 등
- 새롭게 전체 model을 구축: SpineNet [12], HitDetector [20] 등
일반적인 object detector의 구성 요소 및 종류(그림 2)

2.2. Bag of freebies
"bag of freebies"란?
- 보통의 object detector는 offline으로 training되므로, 연구자들은 이러한 이점을 활용하여 inference 비용을 늘리지 않고도 object detector의 정확도를 높일 수 있는 보다 나은 training 방법을 개발하는 것을 선호함
- training 전략만 바꾸거나 training에 소요되는 비용만 증가시키는 방법을 말함
1. data augmentation
입력 이미지의 가변성을 증가시켜, 고안된 object detection model이 다른 환경에서 얻은 이미지에 대해서도 보다 높은 강건함을 유지하는 것이 목적
1) 광학적, 기하학적 왜곡은 일반적으로 많이 사용되며, object detection task에 확실히 도움이 됨
- 광학적 왜곡을 통해, 이미지의 brightness, contrast, hue, saturation, noise 등을 조절
- 기하학적 왜곡을 위해, random scaling, cropping, flipping, rotating 등을 추가
- pixel-wise한 조정으로, 조정된 영역 내 원래 pixel 정보는 유지가 됨
2) object occlusion 문제를 시뮬레이션하는데 중점을 둔 연구들
- random erase [100], CutOut [11], hide-and-seek [69], grid mask [6]
- 이미지 내 사각형 영역을 random하게 선택하여 random하게 채우거나(random erase), 0의 값으로 보완함(CutOut)
- 이미지 내 여러 사각형 영역을 random하게 또는 고르게 선택하여 모두 0으로 바꿈(hide-and-seek, grid mask)
3) 여러 이미지를 함께 사용하는 방법을 이용한 연구들
- MixUp [92], CutMix [91]
- 두개의 이미지를 사용하여 서로 다른 coefficient ratios를 곱한 후 중첩시킨 다음, 이렇게 중첩된 ratios로 label을 조정함(MixUp)
- 잘라낸 이미지를 다른 이미지의 사각형 영역으로 덥고 mix area의 크기에 따라서 label을 조정함(CutMix)
4) GAN을 이용한 연구
- style transfer GAN [15]을 적용하여, CNN이 학습한 texture bias를 효과적으로 줄임
2. regularization
data augmentation의 2)와 유사한 개념을 feature map에 적용한 연구들
- DropOut [71], DropConnect [80], DropBlock [16]
3. imbalance sampling
데이터셋 내 semantic distribution에 bias가 있는 문제를 해결하고자 함
1) 서로 다른 class들간의 data imbalance 문제가 존재
- hard negative example mining [72], online hard example mining [67], focal loss [45]
- two-stage object detector에서는 hard negative example mining 또는 online hard example mining을 적용하여 해결
- one-stage object detector는 dense한 prediction architecture를 이용하므로, example mining 기법의 적용이 불가
- 다양한 classes들 사이에 존재하는 data imbalance 문제를 해결하기 위해 focal loss를 적용
2) 서로 다른 categories 사이 내 연관 정도의 관계를 one-hot hard representation으로는 표현하기 어려운 문제가 존재
- one-hot hard representation은 labeling할 때 자주 사용됨
- [73]에서는 training을 위해 hard label을 soft label로 변환하여 model을 보다 강건하게 만드는 label smoothing을 제안
- [33]에서는 보다 soft한 label을 얻는 것을 목적으로, label refinement network를 설계하기 위해 knowledge distillation의 개념을 도입
4. objective function(of bounding box(Bounding Box) regression)
기존 방식들
- 전통적인 object detector들은 보통 Mean Square Error (MSE)를 이용하여, center point 좌표와 BBox의 height 및 width(예: {x_center, y_center, w, h}) 또는 좌상단 point, 우하단 point(예: {x_top_left, y_top_left, x_bottom_right, y_bottom_right})를 직접적으로 regression함
- anchor-based 방법에서는, (예: {x_center_offset, y_center_offset, w_offset, h_offeset} 및 {x_top_left_offset, y_top_left_offset, x_bottom_right_offset, y_bottom_right_offset})와 같이 해당되는 offset을 추정함
- 그러나, BBox의 각 point에 대한 좌표값을 직접적으로 추정하려면 이러한 points들을 independent variables로 취급해야 하지만, 실제로는 object 자체에 대한 무결성이 고려되지는 않음
개선된 연구들
1) IoU loss [90]
- 예측된 BBox 영역과 ground truth BBox 영역의 coverage를 고려
- IoU loss 계산 process는 ground truth와의 IoU를 수행한 후 생성된 결과를 전체 code로 연결함으로써, BBox의 4개 좌표 points에 대한 계산을 trigger함
- IoU는 scale invariant한 표현이므로, 전통적인 방법으로 {x, y, w, h}의 l_1 또는 l_2 loss를 계산할 때 loss가 scale에 따라 증가되는 문제를 해결 가능
2) GIoU loss [65]
- coverage 영역 이외에도 object의 shape과 orientation를 포함시킴
- 예측된 BBox와 ground truth BBox를 동시에 cover할 수 있는 가장 작은 영역의 BBox를 찾은 후, 이러한 BBox의 분모(denominator)를 원래 IoU loss에서 사용했던 분모로 대체하도록 제안
3) DIoU loss [99], CIoU loss [99]
- DIoU loss: 부가적으로, object 중심의 거리를 고려
- CIoU loss: 겹침 영역, 중심 points 사이의 거리, aspect ratio 등을 동시에 고려. BBox regression 문제에 있어서 더 나은 수렴 속도와 정확도를 달성
2.3. Bag of Specials
"Bag of Specials"란?
- inference 비용을 약간만 증가시키면서도, object detection의 정확도를 크게 향상시키는 것을 말함
- plugin modules과 post-processing으로 구성
- plugin modules: 하나의 model 내 특정한 속성을 향상시키는 것(예: receptive field의 확장, attention mechanism 도입, feature integration capability 강화 등)
- post-processing: 모델의 예측 결과를 선별(screening)하는 방법
A. plugin modules
1. receptive field enhancement module
1) SPP [25]
- Spatial Pyramid Matching (SPM) [39]에서 유래
- SPM의 원래 방법은 feature map을 여러개의 d x d 크기(d={1, 2, 3, ... })의 동등한 block으로 분할한 후, spatial pyramid를 형성하여 bag-of-word 연산으로 features를 추출
- SPM을 CNN에 통합하고 bag-of-word 연산 대신 max-pooling 연산을 이용
- 1차원의 feature vector를 출력하므로, Fully Convolutional Network (FCN)에 적용 불가
- YOLOv3 [63]에서는 k x k(k={1, 5, 9, 13}) kernel size와 stride=1를 가진 max-pooling 출력을 concatenation하여 SPP module을 개선
- 위와 같은 설계 하에, 비교적 큰 k x k max-pooling으로 backbone feature의 receptive field를 효과적으로 증가시킬 수 있음
- SPP module의 개선된 버전을 추가함으로써, YOLOv3-608은 MS COCO object detection task에서 0.5%의 추가적인 계산 비용으로 AP_50을 2.7% 향상시킴
2) ASPP [5]
- ASPP moudule과 개선된 SPP module 사이의 연산 시 차이점은 주로 원래 k x k 크기의 kernel size에서 비롯됨
- 여러개의 3 x 3 kernel size에 대한 max-pooling의 stride는 1과 같고, dilated ratio는 k와 같으며, dilated convolution 연산 시 stride는 1과 같음
3) RFB [47]
- k x k kernel의 여러개 dilated convolutions을 사용하며, dilated ratio는 k와 같으며, stride는 1과 같으므로 ASPP보다 포괄적인 spatial coverage를 얻을 수 있음
- MS COCO에 대해 SSD의 AP_50을 5.7% 증가시키는데, 단지 7%의 추가적인 inference 시간만 소요
2. attention module
object detection에서 사용되는 attention model은 크게 channel-wise attention과 point-wise attention으로 나뉨
1) Squeeze-and-Excitation (SE) [29]
- 대표적인 channel-wise attention model
- ImageNet을 이용한 image classification task에서, 계산 비용을 2%만 늘리는 노력으로도 ResNet50의 top-1 accuracy 성능을 1% 향상시킬 수 있지만, 일반적으로 GPU 상에서 inference 시간이 약 10% 증가함
- 따라서, 모바일 장치에서 사용하는 것이 더 적합
2) Spatial Attention Module (SAM) [85]
- 대표적인 point-wise attention model
- 0.1%의 추가적인 계산만으로도, ImageNet을 이용한 image classification task에서 ResNet50-SE의 top-1 accuracy 성능을 0.5% 향상시킬 수 있음
- 무엇보다도 GPU 상에서 inference 속도에 영향을 주지 않음
3. feature integration
초기 연구들
- low-level의 물리적인 feature를 high-level의 semantic feature로 통합하기 위해 skip connection [51] 또는 hyper-column [22]을 사용
FPN 이후 연구들
- multi-scale의 예측 방법들이 대중화되면서, 서로 다른 feature pyramid를 통합하는 많은 경량 module들이 제안됨
- 1) SFAM [98]: multi-scale의 concatenated feature maps 상에서 channel-wise level의 re-weighting을 수행하기 위해 SE module을 사용
- 2) ASFF [48]: point-wise level의 re-weighting을 위해 softmax를 사용한 후 서로 다른 scale들의 feature map들을 추가함
- 3) BiFPN [77]: scale-wise level의 re-weighting을 수행한 후 서로 다른 scale들의 feature map들을 추가하기 위해 multi-input의 weighted residual connections이 제안됨
4. activation function
좋은 activation function은 gradient를 효율적으로 전파하는 동시에, 너무 많은 계산 비용을 야기하면 안됨
ReLU[56]
- 전통적인 tanh 및 sigmoid activation function에서 흔히 발생하는 gradient vanish 문제를 상당부분 해결
ReLU 이후의 연구들
- LReLU [54], PReLU [24], ReLU6 [28], Scaled Exponential Linear Unit (SELU) [35], Swish [59], hard-Swish [27], Mish [55]
- 역시, gradient vanish 문제를 해결하기 위해 제안
- LReLU 및 PReLU: ReLU의 출력이 0보다 작을 경우 gradient가 0이 되는 문제를 해결하고자 함
- ReLU6, hard-Swish: 특히, quantization networks를 고려하여 고안
- SELU: neural network를 self-normalizing하기 위한 목적으로 제안
- Swish, Mish: continuously differentiable한 activation function이라는 점이 주목해야 할 사항
B. post-processing
deep learning 기반 object detection 시 일반적으로 사용되는 post-processing 기법은 NMS(Non-Maximum Suppression)임
- 동일한 object를 잘못 예측한 BBoxes를 filtering하고 response가 높은 후보 BBoxes만 유지하는데 사용
- NMS가 개선을 시도하는 방식은 objective function을 최적화하는 방법과 일치함
R-CNN [19]에서 사용한 NMS
- 원래 제안된 NMS의 경우 context information를 고려하지 않음
- R-CNN에서는 classification confidence score를 reference로 추가하고 confidence score의 순서에 따라 높은 score에서 낮은 score 순으로 greedy NMS를 수행
R-CNN 이후의 연구들
- soft NMS [1]: object의 occlusion으로 인해, greedy NMS에서는 confidence score가 IoU score와 함께 degradation될 수 있다는 문제를 고려
- DIoU NMS [99]: soft NMS에 기초하여, BBox screening process에 center point 거리에 대한 정보를 추가
위의 post-processing 방법들은 모두 capture된 image feature를 직접적으로 참고하고 있지 않기 때문에, 이후의 anchor-free 기법의 개발에서는 post-processing이 더 이상 필요하지 않음
3. Methodology
BFLOP 보다는 병렬 계산을 위해 생산 시스템 및 최적화 관점에서 빠르게 동작하는 neural network를 개발하는 것이 목표이며, 실시간 neural network을 위한 2개의 options을 제시
- GPU의 경우 convolutional layers 내 group의 수가 작은(1-8) CSPResNeXt50 / CSPDarknet53 등을 이용
- VPU의 경우 grouped-convolution은 사용하지만, Squeeze-and-excitement (SE) blocks은 사용하지 않음. 특히 EfficientNet-lite / MixNet [76] / GhostNet [21] / MobileNetV3 등의 모델들을 포함함
3.1. Selection of architecture
목적 1: network의 입력 해상도, convolutional layer의 개수, parameter 개수(filter size^2 * filters * channel / groups), layer의 출력 개수(filters) 가운데서 최적의 balance를 발견하는 것이 목적
- 본 논문의 수많은 연구 결과에 따르면 ILSVRC2012 (ImageNet) 데이터셋 [10]을 이용한 object classification에서는 CSPResNext50이 CSPDarknet53보다 우수한 성능을 보유
- 하지만, MS COCO 데이터셋 [46]을 이용한 objec detection에서는 CSPDarknet53이 CSPResNext50보다 우수한 성능을 보유
목적 2: receptive field를 늘릴 수 있는 additional blocks과 서로 다른 detector levels을 위한 서로 다른 backbone levels로부터 parameter aggregation을 위한 최상의 기법을 선택하는 것임
- 예: FPN, PAN, ASFF, BiFPN
classification을 위한 reference model이 detector에도 항상 최적은 아니며, classification과 달리 detector에는 아래와 같은 내용들이 필요
- 더 큰 입력 network 크기(해상도): 작은 크기를 갖는 다수 objects들의 검출을 위해 필요
- 더 많은 layers 수: 증가된 입력 network의 크기를 cover할 수 있는 더 높은 receptive field가 필요
- 더 많은 paparameters량: 한장의 이미지에서 서로 다른 크기를 갖는 다수의 objects들을 검출하기 위해, 모델은 더 많은 capacity가 필요
가정하여 말하면, receptive field 크기가 더 크며(보다 많은 개수의 3 x 3 convolutional layers를 가진) parameters 개수가 더 많은 model을 backbone으로 선택해야 한다고 가정할 수 있음
- 표 1은 CSPResNeXt50, CSPDarknet53, and EfficientNetB3 등에 대한 정보를 나타냄(빨강색 사각형이 최종적으로 사용된 backbone을 나타냄)

- CSPResNext50: 단지 16개의 3 x 3 convolutional layers와 425 x 425 크기의 receptive field와 20.6 M의 parameters를 가짐
- CSPDarknet53: 29개의 3 x 3 convolutional layers와 725 x 725 크기의 receptive field와 27.6 M의 parameters를 가짐
- 위와 같은 이론적 근거는 수많은 실험을 통해 CSPDarknet53 neural network가 detector를 위한 2개의 backbone 중에 최적의 model임을 보여줌
크기가 다른 receptive field의 영향은 아래와 같이 요약 가능
- object의 크기가 커지면 -> 전체 object를 보다 많이 볼 수 있음
- network의 크기가 커지면 -> object 주변의 context를 보다 많이 볼 수 있음
- network의 크기가 초과되면 -> image point와 최종 activation 사이의 연결 개수가 증가함
본 연구에서는 CSPDarknet53에 SPP block을 추가
- receptive field를 상당히 늘릴 수 있음
- 가장 중요한 context features를 분리할 수 있음
- network의 동작 속도를 거의 줄이지 않음
서로 다른 detector levels을 위한 서로 다른 backbone levels로부터 parameter를 aggregation하는 기법으로 PANet을 이용(참고: YOLOv3에서는 FPN을 이용)
최종적으로 선택된 기법들
- backbone
- CSPDarknet53
- neck
- addtional blocks: SPP
- path-aggregation blocks: PANet
- head
- YOLOv3(anchor-based)
Cross-GPU Batch Normalization (CGBN 또는 SyncBN) 또는 고가의 특수 장비 등을 사용하지 않으므로, GTX 1080Ti 또는 RTX 2080Ti 등의 기존에 사용하던 GPU를 이용하여 누구나 최신의 결과를 재연 가능
3.2. Selection of BoF and BoS
object detection의 훈련을 개선하기 위해 CNN은 보통 아래의 기법들을 사용(취소선은 미리 제외된 Candidates)
1) Selected BoF Candidates
- Bounding box regression loss: MSE, IoU, GIoU, CIoU, DIoU
- Data augmentation: CutOut, MixUp, CutMix
- Regularization method:
DropOut,DropPath [36],Spatial DropOut [79], DropBlock- DropBlock의 저자들이 YOLOv4를 이용하여 다른 방법들과 비교했을 때 우수한 성능을 보인다는 것을 입증했으므로, DropBlock을 주저없이 적용
2) Selected BoS Candidates
- Activations: ReLU, leaky-ReLU,
parametric-ReLU,ReLU6,SELU, Swish, Mish- PReLU와 SELU는 훈련이 많이 어려우므로 제외
- ReLU6는 특별히 quantization network을 위해 고안되었으므로 제외
- Normalization of the network activations by their mean and variance: Batch Normalization (BN) [32],
Cross-GPU Batch Normalization (CGBN 또는 SyncBN) [93], Filter Response Normalization (FRN) [70], Cross-Iteration Batch Normalization (CBN) [89]- 하나의 GPU만을 이용한 훈련 전략에 중점을 두고 있으므로, syncBN은 제외
- Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, Cross stage partial connections (CSP)
3.3. Additional improvements
제안한 detector를 하나의 GPU를 이용한 training 시 보다 적합하게 만들기 위해, 아래와 같이 추가적인 설계 및 개선을 수행
- Mosaic과 Self-Adversarial Training (SAT) 등의 새로운 data augmentation 기법을 도입
- genetic algorithms을 적용하여 최적의 hyper-parameters를 선택
- 효율적인 training과 detection을 위해 존재하는 기법들을 제안한 detector에 적합하도록 수정
- modified SAM, modified PAN, Cross mini-Batch Normalization (CmBN)
1) BoF: 새롭게 도입한 data augmentation 기법들
- Mosaic(그림3)
- CutMix는 단지 2개의 입력 이미지들만 mix하는데 반해, Mosaic은 4개의 training 이미지들을 1개로 mix함
- 이를 통해 normal한 context 외부의 object들도 detection 할 수 있음
- 추가로, batch normalization은 각 layer 상에서 서로 다른 4개의 이미지들에 대한 activation 통계(statistic)를 계산 가능
- 따라서, 큰 크기의 mini-batch에 대한 필요성을 상당히 줄일 수 있음

- Self-Adversarial Training (SAT)
- 2단계의 forward 및 backward 단계로 동작
- 1단계: neural network는 network의 weight 대신에 원본 이미지를 변경
- 이런 식으로 neural network는 자체적으로 adversarial attack을 수행하여, 이미지에 원하는 object가 없다는 속임수를 만들도록 원본 이미지를 변경함
- 2단계: neural network은 변경된 이미지에서 정상적인 방식으로 object를 detection하도록 훈련됨.
2) BoS: Cross mini-Batch Normalization (CmBN)
CBN의 변경된 version으로서, 단일 batch 내에서 mini-batches 사이에 대한 통계를 수집함(그림 4)

3) BoS: modified SAM, modified PAN
- SAM을 spatial-wise attention에서 point-wise attention으로 변경(그림 5)
- PAN의 shortcut connection을 concatenation으로 교체(그림 6)

3.4. YOLOv4
YOLOv4의 구성 요소 및 사용한 기법들 정리
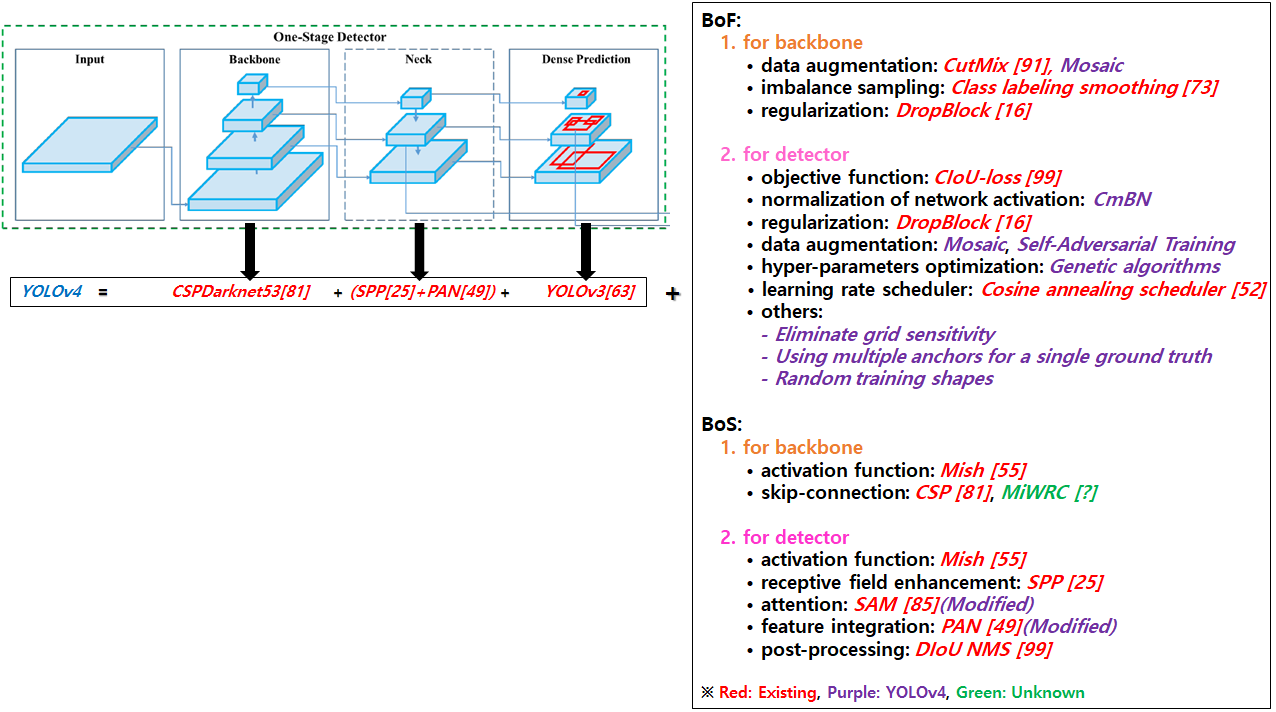
- CSP and CSPDarknet53 [81]: Chien-Yao Wang, Hong-Yuan Mark Liao, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh, and I-Hau Yeh. CSPNet: A new backbone that can enhance learning capability of cnn. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR Workshop), 2020. 2, 7
- SPP [25]: Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 37(9):1904–1916, 2015. 2, 4, 7
- PAN [49]: Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8759–8768, 2018. 1, 2, 7
- YOLOv3 [63]: Joseph Redmon and Ali Farhadi. YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018. 2, 4, 7, 11
- CutMix [91]: Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. CutMix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 6023–6032, 2019.3
- Class labeling smoothing [73]: Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), pages 2818–2826, 2016. 3
- DropBlock [16]: Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V Le. DropBlock: A regularization method for convolutional networks. In Advances in Neural Information Processing Systems (NIPS), pages 10727–10737, 2018. 3
- CIoU-loss and DIoU NMS [99]: Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, and Dongwei Ren. Distance-IoU Loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020. 3, 4
- Cosine annealing scheduler [52]: Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016. 7
- Mish [55]: Diganta Misra. Mish: A self regularized nonmonotonic neural activation function. arXiv preprint arXiv:1908.08681, 2019. 4
- SAM [85]: Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), pages 3–19, 2018. 1, 2, 4
4. Experiments
- A. image classification: ImageNet(ILSVRC 2012 val) 데이터셋을 이용하여, 서로 다른 training 개선 기법들이 classifier의 정확도에 주는 영향에 대해 테스트
- B. object detection: MS COCO (test-dev 2017) 데이터셋을 이용하여, 서로 다른 training 개선 기법들이 detector의 정확도에 주는 영향에 대해 테스트
4.1. Experimental setup
A. ImageNet을 이용한 image classification 실험
- 모든 실험은 1080 Ti 또는 2080 Ti GPU를 이용하여 훈련
- default hyper-parameters:
- training steps: 8,000,000
- batch size: 128
- mini-batch size: 32
- initial learning rate: 0.1 / polynomial decay learning rate scheduling 전략 적용
- warm-up steps: 1000
- momentum: 0.9
- weight decay: 0.005
- BoS 관련 실험:
- 모두 동일한 hyper-parameter를 기본 설정으로 이용
- LReLU, Swish, Mish 등의 activation function들이 주는 영향에 대해 비교
- BoF 관련 실험:
- 부가적으로 50 %의 training steps을 추가
- MixUp, CutMix, Mosaic, Bluring data augmentation, label smoothing regularization 기법들을 검증
B. MS COCO를 이용한 object detection 실험
- hyper-parameter 탐색 실험에 genetic algorithm을 사용하는 것을 제외하고는 모든 실험에서 기본 설정을 이용
- 훈련에 하나의 GPU만 사용하는 것을 고려하였기 때문에, 여러개의 GPU를 이용하여 최적화하는 syncBN 등의 기법은 사용하지 않음
- default hyper-parameters:
- training steps: 500,500
- initial learning rate: 0.01 / step decay learning rate scheduling 전략 적용 / 400,000 steps과 450,000 steps에서 각각 0.1을 곱함
- momentum: 0.9
- weight decay: 0.0005
- batch size: 64 / 하나의 GPU로 multi-scale training을 고려
- mini-batch size: 8 또는 4 / 아키텍처 및 GPU 메모리 제한에 따라 결정
- genetic algorithm을 이용한 hyper-parameter 탐색 실험
- GIoU loss를 이용하여 YOLOv3-SPP를 훈련하는데 genetic algorithm을 사용 / min-val 5k sets에 대해 300 epochs을 탐색
- 채택된 parameters:
- learning rate: 0.00261
- momentum: 0.949
- IoU threshold: 0.213 / ground truth 할당용
- loss normalizer: 0.07
- BoF 관련 실험:
- grid sensitivity elimination / mosaic data augmentation / IoU threshold / genetic algorithm / class label smoothing / cross mini-batch normalization / self-adversarial training / cosine annealing scheduler / dynamic mini-batch size / DropBlock / Optimized Anchors / 서로 다른 종류의 IoU losses
- BoS 관련 실험:
- Mish / SPP / SAM / RFB / BiFPN / Gaussian YOLO [8]
4.2. Influence of different features on Classifier training
classifier를 훈련 시 서로 다른 features들이 주는 영향에 대해서 실험하였으며, 특히 아래의 features들을 고려함.
- Class label smoothing / 그림 7과 같은 서로 다른 종류의 data augmentation 기법(bilateral blurring, MixUp, CutMix, Mosaic) / 서로 다른 종류의 activation function들(Leaky-ReLU(by default), Swish, Mish)

결과
표 2: CSPResNeXt-50를 backbone으로 이용했을 때 BoF와 Mish가 classifier의 정확도에 주는 영향

- CutMix 및 Mosaic data augmentation / Class label smoothing / Mish activation 등의 features들을 적용하였을 때 정확도가 개선됨
표 3: CSPDarknet-53(YOLOv4의 backbone)를 backbone으로 이용했을 때 BoF와 Mish가 classifier의 정확도에 주는 영향

- CSPResNeXt-50을 이용한 실험을 통해, 결과적으로 CSPDarknet-53은 CutMix 및 Mosaic data augmentation / Class label smoothing 등을 포함함
- 추가적으로 Mish activation을 상호 보완을 위한 option으로 사용함
4.3. Influence of different features on Detector training
A. BoF의 다양한 features들이 Detector 훈련에 주는 영향
표 4와 같이 서로 다른 BoF(BoF-detector)가 detector 훈련 정확도에 주는 영향을 보기 위해 추가적인 연구를 수행
FPS에 영향을 주지 않으면서도 detector의 정확도를 높이는 다양한 features들에 대한 연구를 통해 BoF list를 크게 확장함
- S: Eliminate grid sensitivity the equation
- 식 "b_x = sigmoid(t_x)+c_x, b_y = sigmoid(t_y)+c_y"는 YOLOv3에서 object의 좌표를 평가하는데 사용되므로 c_x 또는 cx+1에 접근하는 b_x 값에는 매우 높은 t_x 절대값이 필요함(c_x, c_y: 항상 0 또는 자연수)
- sigmoid에 1.0을 초과하는 factor를 곱하여 이러한 문제를 해결하므로 object가 검출되지 않는 grid의 영향을 제거
- M: Mosaic data augmentation
- 훈련 동안에 단일 이미지 대신 4개의 image mosaic을 사용
- IT: IoU threshold
- IoU (truth, anchor) > IoU threshold 인 경우에는 단일 ground truth에 대해 multiple anchors를 사용
- GA: Genetic algorithms
- 전체 시간 중 처음 10% 기간 동안 network 학습 시 최적의 hyperparameters 선택을 위해 genetic algorithms을 적용
- LS: Class label smoothing
- sigmoid activation을 이용하여 class label smoothing을 수행
- CBN: CmBN
- 단일 mini-batch 내에서 통계를 수집하는게 아니라, 전체 batch 내에서 통계 수집을 위해 Cross mini-Batch Normalization을 이용
- CA: Cosine annealing scheduler
- sinusoid training 동안 learning rate를 변경하는 Cosine annealing scheduler를 적용
- DM: Dynamic mini-batch size
- Random training shapes을 이용하여 작은 해상도를 training 하는 중에는 mini-batch 크기를 자동으로 늘림
- OA: Optimized Anchors
- 512x512 크기의 network 해상도를 이용한 training 시 최적화된 anchors를 사용
- GIoU, CIoU, DIoU, MSE
- bounded된 box에 대해 regression 시 서로 다른 종류의 loss 알고리즘들을 사용
단일 ground truth
Cosine annealing scheduler
표 4: CSPResNeXt50-PANet-SPP을 detector로 이용했을 때 서로 다른 BoF에 대한 Ablation 결과
1) loss를 MSE로 고정시킨 후 다양한 BoF에 대한 실험 결과(OA는 후보군에서 제외)

- M(Mosaic data augmentation) / GA(Genetic algorithms) / CBN(Cross mini-Batch Normalization) / CA(Cosine annealing scheduler) 등은 포함하는 것이 성능 향상에 도움이 됨
2) loss를 GIoU, DIoU, CIoU 등으로 변화시키면서 S, M, IT, GA, OA 등의 BoF에 대한 실험 결과(LS, CBN, CA, DM은 후보군에서 제외)

- S(liminate grid sensitivity the equation) / M(Mosaic data augmentation) / IT(IoU threshold) / GA(Genetic algorithms) 등을 함께 적용하고 loss를 CIoU를 사용하는 것이 성능 향상에 도움이 됨
3) loss를 CIoU를 이용하며, S, M, IT, GA 등의 BOF를 사용할 때 OA의 적용 유무에 따른 실험 결과(LS, CBN, CA, DM은 후보군에서 제외)
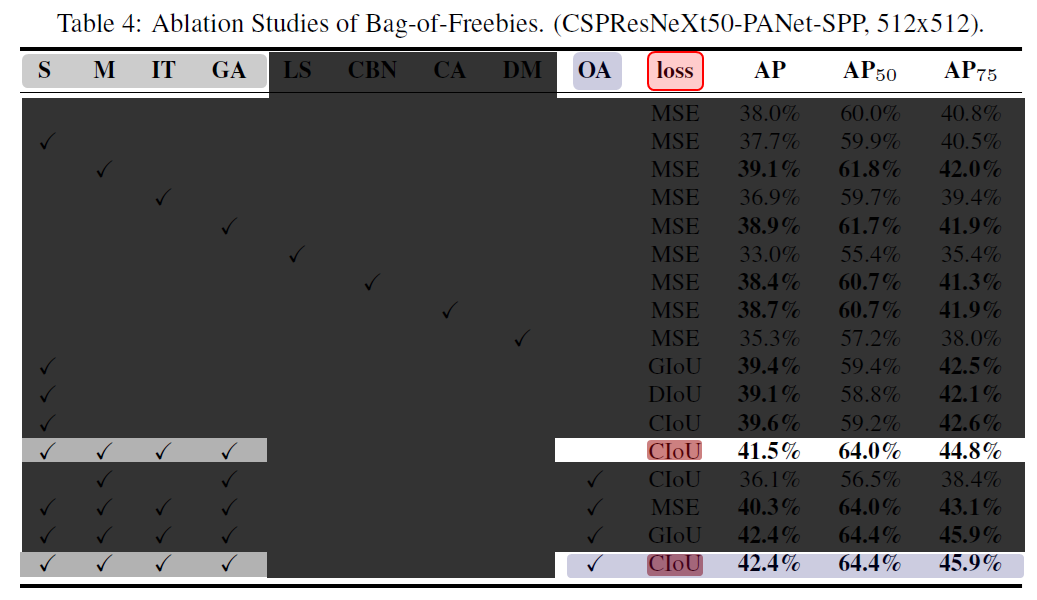
- OA(Optimized Anchors)를 적용하는 것이 성능 향상에 도움이 됨
4) S, M, IT, GA, OA 등의 BOF를 사용하며, loss를 MSE, GIoU, CIoU 등으로 변화시킬 때의 실험 결과(LS, CBN, CA, DM은 후보군에서 제외)
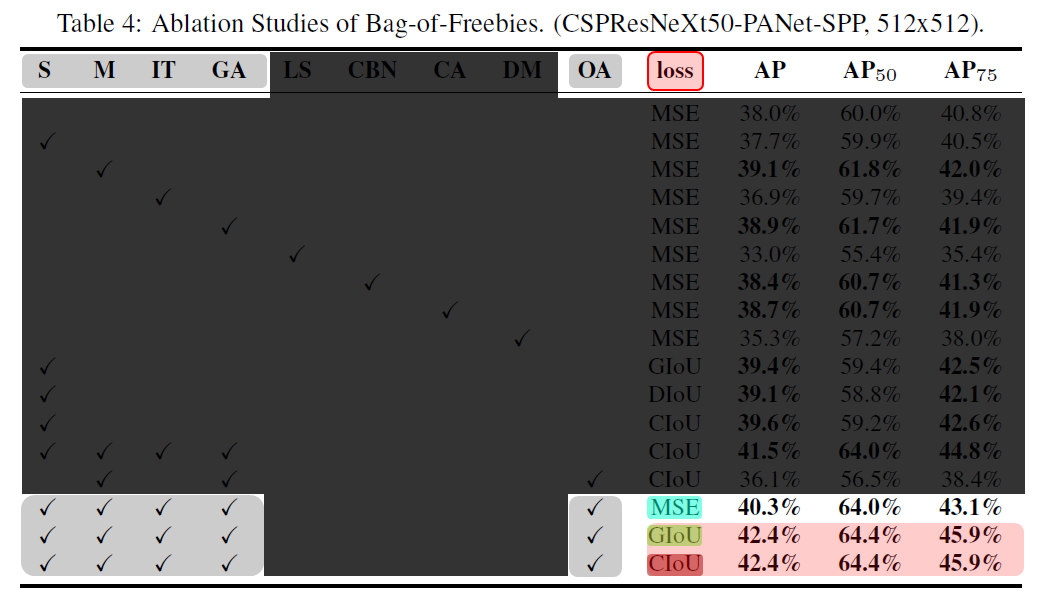
- GIoU와 CIoU loss를 적용하는 것이 성능 향상에 도움이 되며, 동일한 결과를 보임
B. BoS의 다양한 features들이 Detector 훈련에 주는 영향
표 5와 같이 서로 다른 BoS(BoS-detector)가 detector 훈련 정확도에 주는 영향을 보기 위해 추가적인 연구를 수행

- 실험에 사용된 backbone / BoS features들: CSPResNXt50 / PAN, RFB, SAM, Gaussian YOLO (G), ASFF
- SPP, PAN, SAM을 함께 사용한 경우 가장 우수한 성능을 보임
4.4. Influence of different backbones and pretrained weightings on Detector training
표 6과 같이 서로 다른 backbone model들이 detector의 정확도에 주는 영향을 보기 위해 더 많은 연구를 진행
가장 우수한 classification 정확도를 보이는 model이 detector의 정확도 관점에서도 가장 우수한 것은 아님을 발견
표 6: detector 훈련을 위해 서로 다른 classifier로 pre-trained된 weight를 사용한 경우(다른 모든 훈련 parameters들은 모든 모델이 유사)
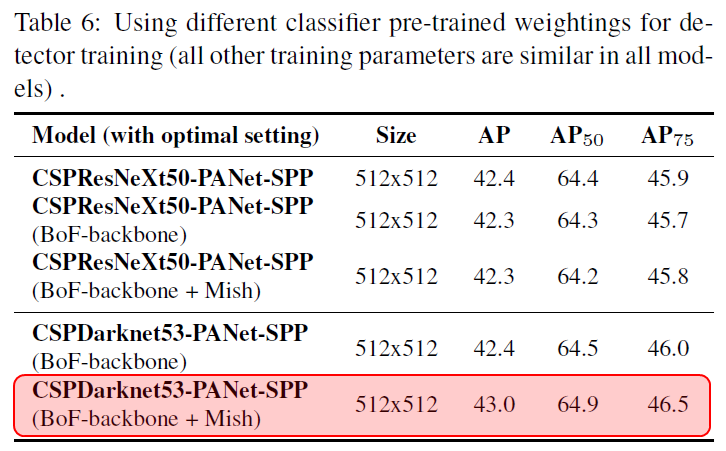
- 1) 서로 다른 features들을 이용하여 훈련된 CSPResNeXt50 model이 CSPDarknet53 model보다 classification 정확도가 높지만, object detection 정확도는 CSPDarknet53 model이 더 높음
- 2) 이전 실험을 통해 CSPResNeXt-50의 classifier 훈련에 BoF와 Mish를 사용하면 classification 정확도가 향상되는 것을 확인했지만, 이렇게 pre-trained된 weight를 detector에 적용하면 정확도가 떨어짐
- 그러나 CSPDarknet53의 classifier 훈련에 BoF와 Mish를 사용한 경우는 classification과 pre-trained된 weight를 detector에 적용한 경우 모두에서 정확도가 향상되므로, CSPDarknet53이 CSPResNeXt50보다 detector에 적합한 backbone이라고 할 수 있음
다양한 개선으로 인해 CSPDarknet53 model이 detector의 정확도를 향상시킬 수 있는 더 많은 능력이 있음을 확인함
4.5. Influence of different mini-batch size on Detector training
마지막으로 서로 다른 mini-batch size를 이용하여 훈련된 model들에 대한 결과를 분석
표 7: detector 훈련 시 서로 다른 mini-batch size를 사용한 경우

- CSPResNeXt50-PANet-SPP와 CSPDarknet53-PANet-SPP 모두, mini-batch size를 8에서 4로 줄이면서 BoF와 BoS training 전략을 추가한 경우나 그렇지 않은 경우 둘 다 성능에 거의 영향을 주지 않음
이는 BoF와 BoS를 도입한 후 training에 더 이상 값비싼 GPU가 필요하지 않다는 것이며 즉, 누구나 기존의 GPU를 가지고 성능이 우수한 detector를 training할 수 있게 됨
5. Results
그림 8은 다른 최신의 object detectors들과의 비교 결과를 나타내고 있음
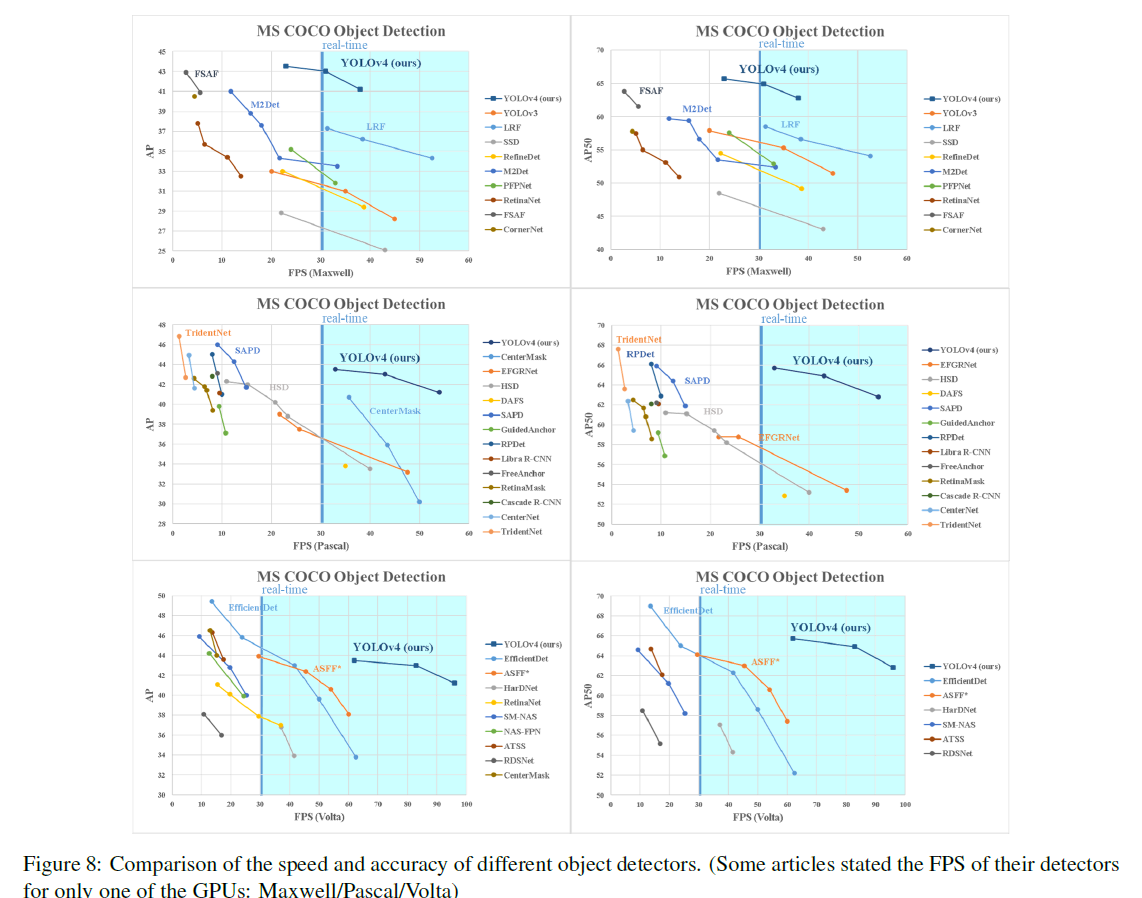
- inference 시간 검증을 위해 서로 다른 기법들은 서로 다른 아키텍처의 GPU를 이용하므로, 일반적으로 채택된 Maxwell, Pascal, Volta 아키텍처의 GPU를 사용하여 다른 최신 기법들과 비교
- YOLOv4는 파레토 최적(Pareto optimality) 곡선에 위치하며, 속도 및 정확성 측면에서 가장 빠르고 정확한 detector임
표 8: Maxwell GPU(GTX Titan X(Maxwell) 또는 Tesla M40 GPU)를 사용한 frame rate 비교 결과

표 9: Pascal GPU(Titan X(Pascal), Titan Xp, GTX 1080 Ti 또는 Tesla P100 GPU)를 사용한 frame rate 비교 결과

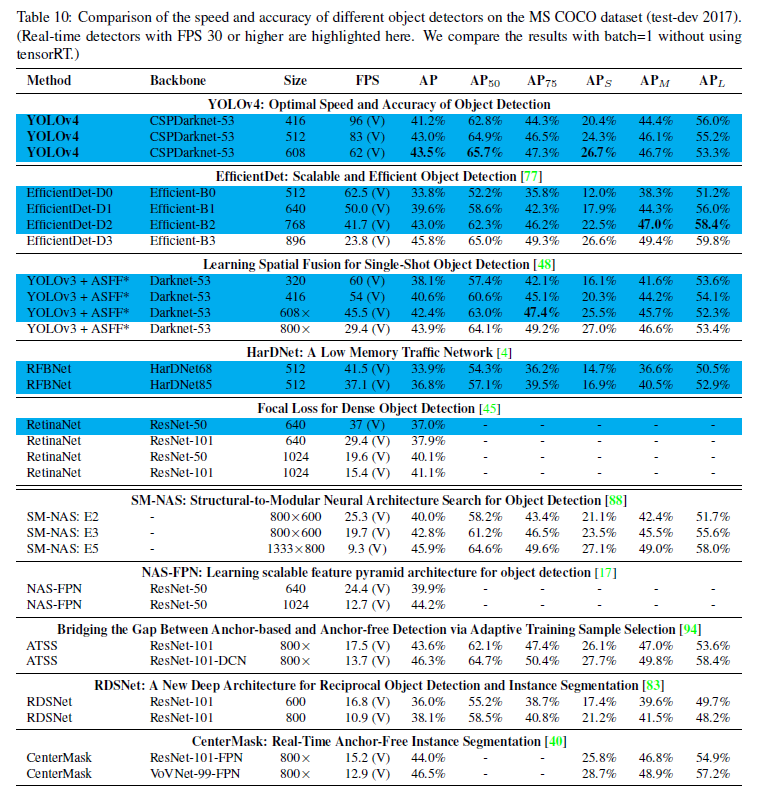
표 10: Volta GPU(Titan Volta 또는 Tesla V100 GPU)를 사용한 frame rate 비교 결과
6. Conclusions
- 사용 가능한 모든 대안의 detectors들보다 빠르고(FPS) 정확한(MS COCO AP50 ... 95, AP50) 최신의 detector를 제안
- 제안한 detector는 8~16 GB의 VRAM으로 기존의 GPU에서 training 및 사용이 가능하므로, 광범위한 적용이 가능
- one-stage anchor-based detectors의 원래 개념의 실행 가능성을 입증
- classifier와 detector 모두의 정확도 개선을 위해 많은 features들을 검증하여 선택
- 이러한 features들은 향 후 연구 개발을 위한 모범 사례(best-practice)로 사용 가능
7. Acknowledgements
Mosaic data augmentation, genetic algorithms을 이용한 hyper-parameters 선택, YOLOv3의 grid sensitivity problem(github.com/ultralytics/yolov3) 문제 해결을 위해 아이디어를 제공한 Glenn Jocher에게 감사함
참고 사항
YOLOv4의 구성 요소와 사용 기법에 대한 보다 상세한 내용은 아래 파일 참고(첨부 파일)
- YOLOv4_Optimal Speed and Accuracy of Object Detection_리뷰.pptx 파일

부터

까지 살펴보면 됨

