Abstract
원격 탐사 영상에서 객체 검출(object detection)은 상당한 연구가 진행되었음에도 불구하고, 데이터셋과 딥러닝 기반 기법들에 대한 서베이는 부족한 상황
- 존재하는 데이터셋은 여러면에서 충분하지 못함: 이미지 개수, 카테고리가 적음, 다양성, 변화 등
컴퓨터 비전, 지구 관측 분야에 있어서 딥러닝 기반의 객체 검출과 관련된 포괄적인 리뷰를 수행
DIOR(DetectIon in Optical Remote sensing images) 데이터셋을 제안
- 23,463개의 이미지, 192,472개의 인스턴스, 20개의 객체 클래스들로 구성
- 1) 객체 클래스, 객체 인스턴스 개수, 전체 이미지 개수 등에서 대규모임.
- 2) 큰 범위의 객체 크기 및 공간 해상도 변화, 클래스 간, 클래스 내의 다양성 존재
- 3) 다양한 이미지 조건, 날씨, 계절, 영상 품질 등을 고려하여 취득
- 4) 클래스 간의 유사도가 높고, 클래스 내의 다양성이 높음
몇몇 SOTA 알고리즘들에 대해서 DIOR 데이터셋을 이용하여 성능 평가를 수행함
1. Introduction
과거 몇년 동안 원격 탐사 영상을 이용한 객체 검출은 많은 발전을 이룩하였으며, 최근 딥러닝 기반 접근들은 자연 연상에서 우수한 성능들을 보임. 자연 영상을 이용한 딥러닝 기반 객체 검출을 원격 탐사 이미지를 이용한 객체 검출로 전이하는 것은 어려운 일임.
원격 탐사 영상과 자연 영상은 상당한 차이점이 존재
- 아래 그림처럼, 원격 탐사 영상은 객체들의 지붕 정보를 캡처하나 자연 영상은 객체의 프로필 정보를 캡처

지구 관측 분야에서 NWPU VHR‐10, UCAS‐AOD,, COWC, DOTA 등의 데이터셋을 이용한 객체 검출이 수행되었지만, 만족스러운 성능을 보이지 못하고 있음.
- 서베이 논문들도 충분하지 못하고, 공개된 데이터셋들도 abstract에서 본것처럼 여러 단점들이 있으며, 제안한 데이터셋의 예는 아래와 같음.

논문의 기여
- 1) 객체 검출 발전과 관련된 딥러닝 기반의 포괄적인 서베이를 수행
- 2) 대규모의 벤치마크 데이터셋을 만듬
- 3) 제안한 DIOR 데이터셋을 이용하여 성능 평가를 수행
2. Review on Object Detection in Computer Vision Community
CNN 기반 딥러닝 모델을 이용하여 이미지 분류 및 객체 검출을 위한 다양한 연구들이 컴퓨터 비전 분야에서 수행되었음. 자연 영상 데이터셋들을 이용한 다양한 객체 검출 연구들에 대해서 살펴봄.
2.1 Object Detection Datasets of Natural Scene Images
1) PASCAL VOC Dataset
- VOC 2007과 VOC 2012가 있으며, 20개의 객체 클래스는 동일하고 이미지 개수만 다름.
- VOC 2007은 전체 9963개의 이미지가 있으며, 5011개의 훈련 이미지, 4952개의 테스트 이미지로 구성되어 있음.
- VOC 2012는 훈련 이미지는 11540개, 테스트 이미지는 10991개로 구성
2) MSCOCO Dataset
- 80개의 객체 클래스에 대해 200,000 장 이상의 이미지들로 구성되어 있음.
- 훈련 이미지는 80,000개, 검증 이미지는 40,000개, 테스트 이미지는 80,000개로 구성
3) ImageNet Object Detection Dataset
- 200개의 객체 클래스에 대해 500,000 장 이상의 이미지들로 구성되어 있음.
- 훈련 이미지는 456,567개, 검증 이미지는 20,121개, 테스트 이미지는 40,152개로 구성
2.2 Deep Learning Based Object Detection Methods in Computer Vision Community
최근 수많은 딥러닝 기반 객체 검출 기법들이 제안되었으며, 상당한 성능 개선을 달성함. 딥러닝 기반 객체 검출 기법은 region proposal의 생성 여부에 따라 크게 2개(region proposal 기반 기법, regression 기반 기법)의 기법들로 나뉨.
2.2.1 Region Proposal‐based Methods
크게 2가지 단계로 구성됨
- 단계 1: 객체를 포함할 가능성이 있는 후보 region proposal set을 생성하는 단계
- 단계 2: 단계 1로부터 취득한 후보 region proposal들을 객체 클래스 또는 배경으로 분류한 후 바운딩 박스의 좌표를 파인 튜닝하는 단계
발전 순서 및 주요 내용
1) R‐CNN
객체 검출을 위한 풍부한 특징 정보를 생성하기 위해 CNN 모델을 적용한 대표적 연구로서, 이전 연구들과 비교했을 때 상당한 성능 향상을 보임.
- 단계 1: 후보 객체를 탐색하기 위해 Selective Search를 이용하여 입력 이미지를 스캔한 후 약 2000개의 region proposal을 생성함.
- 단계 2: 생성된 region proposal은 고정된 크기(예: 224 x 224)로 리사이징 되고, 각 region proposal에 대해 deep한 특징들을 PASCAL VOC 데이터셋을 이용하여 파인 튜닝된 CNN 모델을 사용하여 추출함.
- 단계 3: 각각의 region proposal에 대한 특징들은 해당 region proposal이 객체 또는 배경인지에 대한 label를 달기 위해 class에 specific한 SVM에 넘겨지고, 만약 객체가 존재한다면 객체의 위치를 정제하기 위해 linear regressor가 사용됨.
2) SPPnet 및 Fast R-CNN
R-CNN은 풍부한 region proposal에 대해 반복적인 계산을 하므로 비효율적임. 더 나은 검출 효율성 및 정확성을 달성하기 위해, SPPnet 및 Faster R-CNN과 같은 방법이 제안됨.
- 모든 region proposal에 대한 CNN 특징 추출 시 발생되는 계산 load를 공유함.
- Fast R-CNN는 RoI layer를, SPPnet은 SPP(spatial pyramid pooling) layer를 이용하여 전체 이미지에 대해 특징 추출을 수행함.
- 여기서 CNN 모델은 전체 이미지에 대해서 수천번이 아닌 단한번만 동작 되기 때문에 R-CNN 보다 적은 계산이 필요함.
3) Faster R-CNN
SPPnet 및 Fast R-CNN이 R-CNN보다 속도는 빠르지만, EdgeBox나 selective search와 같이 hand‐engineering된 proposal detector를 이용하여 region proposal을 미리 생성해야 하는 필요성이 있음. 하지만, 이러한 메커니즘은 전체 검출 프로세스에 있어서 심각한 bottleneck을 갖게 되며 이러한 문제점을 fix시키기 위해 Faster R-CNN이 제안됨. region proposal을 생성 하기 위해 속도가 느린 selective search을 이용하는 대신에, 속도가 빠른 모듈을 적용하며 크게 2개의 모듈로 구성됨.
- 첫번째 모듈: region proposal을 생성하기 위한 fully convolutional network 형태의 region proposal network(RPN)
- 두번째 모듈: 첫번째 모듈을 통해 생성된 proposal들을 분류하기 위한 Fast R‐CNN object detector
핵심 아이디어: RPN과 Fast R-CNN detector에 대해 동일한 convolutional layers를 fully connected layers까지 공유하는 것에 있음.
- 이런 방식을 이용하여, 이미지는 region proposals과 이에 해당하는 features들을 생성하기 위해 CNN을 한번만 통과하면 됨.
- convolutional layers를 공유하므로, 매우 deep한 CNN 모델을 이용하여 전통적인 방식보다 고품질의 region proposals을 생성할 수 있음.
4) Mask R-CNN, R-FCN, Light Head R‐CNN, R‐FCN‐3000
Faster R-CNN의 성능 향상을 위한 확장 연구들
4.1) Mask R-CNN
- Faster R‐CNN을 기반으로 함.
- bounding box 검출을 위해 기존 branch와 병렬로 객체 mask를 예측하기 위한 추가적인 branch를 추가함.
- 따라서 정확한 객체 인식 및 각 객체 instance에 대한 고품질의 segmentation mask 생성이 동시에 가능함.
4.2) R-FCN(region‐based fully convolutional network)
- Faster R‐CNN의 객체 검출 속도를 빠르게 하기 위해 제안된 방법임.
- position‐sensitive RoI pooling layer를 사용하여 마지막 convolutional layer의 출력을 aggregate하고 각 RoI에 대한 점수를 생성함.
- 전체 이미지에 대해 거의 모든 계산 load를 공유하므로, region 마다 sub-network를 계산하여 연산량이 많은 Faster R-CNN보다 2.5~20배 빠름.
4.3) Light Head R‐CNN
- R-FCN의 검출 속도 향상을 위해서 제안됨.
- detection network의 head를 가능한한 light하게 만듬.
4.4) R-FCN-3000
- 3000개의 object class에 대해, 대규모 실시간 객체 검출을 가능하게 하는 방법이 제안됨.
- 서로 다른 object class에 대한 localization을 수행하기 위해 shared된 filter를 학습하는데 사용되는 R-FCN을 수정시킨 접근법임.
5) feature pyramid network(FPN)
- CNN 내부에 feature pyramids를 구축
- Faster R‐CNN 및 Mask R‐CNN 프레임워크를 사용한 객체 검출용 generic feature extractor로서 상당한 개선을 보임.
6) path aggregation network(PANet)
- bottom-up path augmentation을 통해 lower layers의 정확한 localization 정보를 전체 feature hierarchy로 boosting 시킬 수 있는 방법이 제안됨.
- bottom‐up path augmentation은 lower layers와 topmost feature 사이의 정보 경로를 상당히 단축시키는 역할을 함.
7) Scale Normalization for Image Pyramids(SNIP) 및 SNIP with Efficient Resampling(SNIPER)
객체 검출을 위한 진보되고 효과적인 data augmentation 기법들이며, 상당한 scale 변화가 있는 상황에서, 객체 검출 및 인식을 위한 다양한 기법들의 상세한 분석을 제공함. SNIP와 SNIPER은 일반성이 있으므로, Faster R‐CNN, Mask R‐CNN, R‐FCN, deformable R‐FCN 등의 여러 detector에 광범위하게 적용이 가능함.
7.1) SNIP
- 훈련 및 검출 단계에서 모두 image pyramid를 구축하고 image scale에 대한 function으로써 서로 다른 크기의 객체에 대한 gradient를 선택적으로 back‐propagates시키는 새로운 훈련 패러다임을 제안함.
- 훈련 중에 scale‐variation을 줄이면서도 훈련 샘플을 줄이지 않기 때문에, 상당한 이점을 얻을 수 있음.
7.2) SNIPER
- image 내 내용에 따라 image pyramid 내 여러 scale로부터 훈련 샘플들을 적응적으로 생성하는 효율적인 multi‐scale 훈련 전략을 사용함.
- 동일한 조건하에, SNIP보다 훈련 중에 처리되는 픽셀수를 3배나 줄이면서 성능은 유지시킴.
2.2.2 Regression‐based Methods
객체 instance 예측을 위해 one‐stage object detectors를 사용하는 방법으로서, regression 문제로 detection을 단순화시킴. 후보 region proposal을 생성하고 그 후 feature resampling하는 단계가 필요 없으므로, region proposal‐based methods들과 비교했을 때 훨씬 더 단순하고 더욱 더 효율적임.
발전 순서 및 주요 내용
1) OverFeat
- sliding‐window 패러다임을 이용하여, deep networks을 기반으로 한 최초의 regression 기반 object detector임.
2) You Only Look Once(YOLO)
대표적인 regression 기반 객체 검출 기법임. 한번의 평가를 통해 전체 이미지로부터 bounding boxes와 클래스 확률을 직접적으로 예측하기 위해 단일 CNN backbone을 적용
- 입력 이미지가 주어졌을 때, S x S 크기의 grid로 나눔.
- 객체의 중심이 grid cell에 들어가면, 해당 grid가 해당 객체의 검출을 담당하게 됨.
- 각 grid cell은 confidence scores와 클래스 확률 C와 함께 bounding boxes B를 예측함.
- 객체 검출을 단일 regression 문제로 재구성함으로써, 실시간 객체 검출이 가능함.
- 작은 크기의 객체를 정확하게 localization하는데 있어서는 어려움을 겪음.
3) Single Shot multibox Detector(SSD)
속도 및 정확도의 개선을 위해서 제안된 방법임.
- bounding boxes의 출력 공간은 feature map의 위치마다 다른 scale과 종횡비를 갖는 default boxes의 set으로 분리(discretized)가 됨.
- 예측 단계에서는 각각의 default box 내 각 object class의 존재를 나타내는 confidence scores들이 SSD 모델에 기반하여 생성되고 object shape을 좀 더 매칭시키기 위해 box를 조정하게 됨.
- object의 크기에 대한 variations 문제를 다루기 위해서, 여러 feature map에서 얻은 예측을 서로 다른 해상도와 결합시킴.
- default boxes 메커니즘과 multi‐scale의 feature maps을 도입함으로써, YOLO보다 작은 객체를 찾아 검출하는 성능이 향상됨.
4) RetinaNet detector
정확도를 상당히 향상시킨 방법임.
- feature pyramid network에 전통적인 cross‐entropy loss를 새롭게 제안한 Focal loss로 교체시켜 적용함.
5) YOLOv2
detector의 효율성을 유지하면서도 객체 검출의 정확도를 향상시킨 방법임. 원래 YOLO 대비 다양한 개선이 이루어짐.
- dropout을 사용하지 않고 over‐fitting을 방지하기 위해, 모든 convolutional layers에 batch normalization을 추가시킴.
- 작은 크기의 객체를 검출하기 위해 입력 이미지의 해상도를 고해상도로 조정함(원래 YOLO: 224 x 224 → YOLOv2: 448 x 448).
- 원래 YOLO에서 사용했던 fully‐connected layers를 제거하고, SSD와 유사하게 anchor boxes를 기반으로 bounding boxes를 예측함.
6) YOLOv3
YOLOv2, SSD, RetinaNet 등과 성능은 유사하면서 속도를 빠르게 한 방법임. YOLOv2의 메커니즘을 준수함. Darketnet‐53과 multi‐scale의 feature maps 도입을 통해, YOLO나 YOLOv2 대비 작은 크기의 객체 검출 정확도가 향상되었으며, 속도가 개선되는 결과를 보임.
- dimension clusters를 anchor boxes로 사용하여, bounding boxes를 예측함.
- 각각의 bounding box에 대한 object score를 출력하기 위해, softmax classifier 대신 독립적인 logistic classifiers를 적용함.
- FPN과 유사한 개념을 사용하기 위해, 3개의 서로 다른 scale로부터 추출된 features를 통해 bounding boxes를 예측함.
- 특징 추출을 위해 Darketnet‐53이라는 새로운 backbone을 사용함: 53개의 convolutional layers를 갖는 newfangled residual network임.
7) CornerNet
단일 CNN을 이용하여, object의 bounding boxes를 corners 쌍(pairs, 예: 좌상단 코너 및 우하단 코너)으로 검출하는 새롭고 효과적인 객체 검출 패러다임임.
- object를 쌍이 있는(paired) corners로 검출함으로써, regression‐based object detectors들에서 널리 사용되는 anchor boxes set의 설계에 대한 필요성을 제거시킴.
- 네트워크가 corners를 보다 잘 찾는데 도움이 되도록 corner pooling이라고 불리는 새로운 형태의 pooling layer를 도입함.
region proposal‐based 객체 검출 기법과 regression‐based 객체 검출 기법의 비교
- 정확성: region proposal‐based 객체 검출 기법 > regression‐based 객체 검출 기법
- 속도: regression‐based 객체 검출 기법 > region proposal‐based 객체 검출 기법
다양한 종류의 CNN 아키텍처
- 객체 검출 task에서 CNN 프레임워크는 결정적인 역할을 함.
- 다양한 객체 검출 프레임워크에서 사용되는 network backbones 역할을 수행함.
- 대표적인 CNN 모델 아키텍처의 발전 순서: AlexNet(2012) → ZFNet(2014) → VGGNet(2015) → GoogLeNet(2015) → Inception series(2015, 2016, 2017) → ResNet(2016) → DenseNet(2017) → SENet(2018)
- 딥러닝 기반 객체 검출의 성능 향상을 위한 연구 주제들: feature 개선, contextual information 융합, object deformations 모델링 등
3. Review on Object Detection in Earth Observation Community
지구 관측 분야에서 다양한 geospatial objects를 검출하기 위한 연구들은 오랫동안 수행됨. 원격 탐사 영상에서 객체 검출을 위한 포괄적인 리뷰 논문이 있지만, 딥러닝 기반은 다루고 있지 않으므로, 딥러닝 기반 객체 검출에 대한 리뷰를 수행함.
3.1 Object Detection Datasets of Optical Remote Sensing Images
다양한 종류의 객체 검출용 지구 관측 이미지 데이터셋과 DIOR 데이터셋에 대한 설명
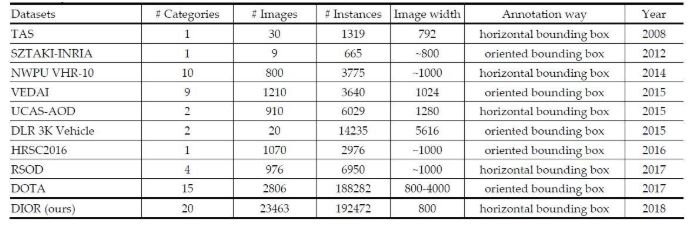
1) TAS
- 항공 영상에서 차량 검출을 목적으로 함.
- 전체 30개의 이미지가 있으며, 수동으로 annotated한 임의의 방향을 가진 차량 1319개가 있음.
- 비교적 저해상도이며, 건물 및 나무들로 인해 많은 그림자들이 존재함.
2) SZTAKI‐INRIA
- 다양한 종류의 건물들을 검출하기 위한 벤치마킹용 데이터셋임.
- 수동으로 annotated한 oriented bounding boxes의 665개 빌딩으로 구성
- 9개의 원격 탐사 이미지들로 구성되어 있으며, 영국, 헝가리, 프랑스, 독일 등의 국가들에서 수집함.
- 모두 Red, Green, Blue의 3개 채널을 가지고 있음.
- 헝가리에서 취득한 영상 2개만 항공 영상이고, 나머지는 7개는 QuickBird, IKONOS, Google Earth 등의 위성 영상임.
3) NWPU VHR‐10
- 10개의 geospatial objects들로 구성(비행기: 757개, 야구장: 390개, 농구코트: 159개, 다리: 124개, 항구: 224개, 육상 경기장: 163개, 배: 302개, 저장 탱크: 655개, 테니스 코트: 524개, 자동차: 477개)
- 715개의 RGB 이미지(Google Earth로부터 수집, 공간 해상도: 0.5~2m)와 85개의 pan‐sharpened color 적외선 이미지(공간 해상도: 0.08m, Vaihingen data로부터 취득)로 구성
- 3775개의 object instance를 가지고 있으며, 수동으로 annotated한 horizontal bounding boxes를 가지고 있음.
- 지구 관측 분야에서 널리 사용되고 있는 데이터셋임.
4) VEDAI
- 항공 영상에서 여러 class에 대한 운송수단(vehicle) 검출을 위해 만들어진 데이터셋
- 3640개의 운송수단 instance와 9개의 class들로 구성(보트, 자동차, 캠핑카, 비행기, 픽업차량, 트랙터, 트럭, 승합차, 기타)
- 2012년 봄에 Utah AGRC에서 취득한 1024 x 1024 크기의 항공 영상 1210개로 구성되어 있으며, 공간 해상도는 12.5cm임.
- 각각의 이미지는 4개의 비압축 컬러 채널을 가지고 있음(3개의 RGB 컬러 채널 + 1개의 근적외선 채널)
5) UCAS‐AOD
- 비행기(600개의 이미지, 3210개의 비행기 포함) 및 운송수단(310개의 이미지, 2819개의 운송수단 포함) 검출을 위해 고안된 데이터셋임.
- 객체의 방향이 고르게 분포될 수 있도록 모든 이미지들을 신중하게 선택되어짐.
6) DLR 3K Vehicle
- 운송수단 검출을 목적으로 고안된 약간의 다른 특성을 갖는 데이터셋임.
- 독일에서 취득되었으며, DLR 3K 카메라 시스템(준실시간 항공 디지털 모니터링 시스템)을 사용하여 지상으로부터 1000 미터 높이에서 취득함.
- 5616 × 3744 크기의 항공 이미지 20개로 구성되어 있으며, 수동으로 annotated한 oriented bounding boxes의 14235개 운송수단을 포함하고 있음.
7) HRSC2016
- 배 검출을 위해 Google Earth로부터 수집된 1070개의 이미지로 구성되어 있으며, 2976개의 배를 포함하고 있음.
- 이미지 크기의 범위는 300 × 300 ~ 1500 × 900 를 가지며, 대부분 1000 × 600 크기를 가짐.
- 회전, scale, 위치, 모양, appearance 등이 다양한 변량을 갖도록 수집되어짐.
8) RSOD
- Google Earth와 Tianditu로부터 다운로드 받은 976개의 이미지로 구성되어 있으며, 공간 해상도의 범위는 0.3m~3m를 가짐.
- 6950개의 object instance를 갖고 있으며, 4개의 object class가 있음(기름 탱크 1586개, 비행기 4993개, 고가도로 180개, 운동장 191개)
9) DOTA
- 새로운 대규모의 geospatial object 검출 데이터셋으로서 15개의 object 카테고리로 구성되어 있음(야구장, 농구코트, 다리, 항구, 헬리콥터, 육상 경기장, 대형 운송수단, 비행기, 배, 소형 운송수단, 축구장, 저장 탱크, 수영장, 테니스 코트, 회전 교차로)
- 2806개의 항공 영상을 포함하고 있으며, 다중 해상도를 가지는 서로 다른 센서 및 플랫폼으로부터 취득됨.
- oriented bounding box를 가지는 188,282개의 object instances가 annotation되어 있으며, 이미지 크기의 범위는 800 x 800 ~ 4000 x 4000 을 가짐.
- 각각의 이미지는 여러개의 object들을 포함하고 있으며, scale, 방향, 모양 등이 다양함.
- 현재까지 가장 challenging한 데이터셋이라고 할 수 있음.
3.2 Deep Learning Based Object Detection Methods in Earth Observation Community
컴퓨터 비전 분야에서 딥러닝 기반 객체 검출의 상당한 발전은 원격 탐사 영상에서의 객체 검출에도 많은 영향을 줌. 자연 영상에서의 객체 검출과 달리, 지구 관측 분야에서 multi‐class의 객체 검출은 region proposal‐based 기법들을 이용한 연구가 지배적임. 따라서, region proposal‐based 기법이냐 regression‐based 기법이냐를 따로 구별할 필요가 없음.
1) region proposal‐based 객체 검출에 기반한 연구들
1.1) R-CNN에 기반한 연구들
자연 영상에서 객체 검출 시 R-CNN의 우수한 성능으로 인해, 원격 탐사 영상에서도 다양한 geospatial object 검출 시 R-CNN 파이프라인을 채택하는 연구들이 많아짐.
관련 연구들 목록
- [1] Learning rotation‐invariant convolutional neural networks for object detection in VHR optical remote sensing images
- [2] Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks
- [3] Detection of seals in remote sensing images using features extracted from deep convolutional neural networks
- [4] Convolutional Neural Network Based Automatic Object Detection on Aerial Images
- [5] Learning Rotation‐Invariant and Fisher Discriminative Convolutional Neural Networks for Object Detection
[1]에서는 multi‐class의 geospatial object 검출을 위해 R-CNN 프레임워크에서 rotation‐invariant CNN(RICNN) 모델을 학습하는 방법을 제안함. RICNN은 AlexNet과 같은 기성(off‐the‐shelf) CNN 모델에 새로운 rotation‐invariant layer를 추가시킴.
[2]에서는 고해상도 지구 관측 이미지에서 geospatial objects를 정확히 찾기 위해서, R-CNN프레임워크에 기반한 unsupervised score‐based bounding box regression(USB‐BBR)을 제안함.
[5]에서는 최신의 객체 검출 성능을 향상시키기 위해, CNN feature에 rotation‐invariant regularizer와 Fisher discrimination regularizer를 도입하여 rotation‐invariant와 Fisher discriminative CNN(RIFD‐CNN) 모델을 훈련시키는 새로운 방법을 제안함.
단점
- R-CNN에 기반한 연구들이 우수한 성능을 보였지만, 객체 검출 시스템에서 실행 시간의 대부분을 차지하는 human‐designed object proposal 생성 기법에 의존하기 때문에 여전히 많은 시간이 소요됨.
- hand‐engineered low‐level features에 기반하여 생성된 region proposal의 품질은 좋지 않기 때문에 객체 검출 성능이 저하됨.
1.2) Faster R-CNN에 기반한 연구들
검출 정확도 및 속도를 보다 향상시키기 위해서 Faster R-CNN 프레임워크를 확장시킨 연구들이 수행되어짐.
관련 연구들 목록
- [1] Toward fast and accurate vehicle detection in aerial images using coupled region‐based convolutional neural networks
- [2] Geospatial Object Detection in High Resolution Satellite Images Based on Multi-Scale Convolutional Neural Network
- [3] An Efficient and Robust Integrated Geospatial Object Detection Framework for High Spatial Resolution Remote Sensing Imagery
- [4] Rotation‐Insensitive and Context‐Augmented Object Detection in Remote Sensing Images
- [5] Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining
- [6] Deformable ConvNet with Aspect Ratio Constrained NMS for Object Detection in Remote Sensing Imagery
- [7] Aircraft detection in remote sensing images based on a deep residual network and Super‐Vector coding
- [8] M‐FCN: Effective Fully Convolutional Network‐Based Airplane Detection Framework
- [9] Ship detection in optical remote sensing images based on deep convolutional neural networks
- [10] Multi‐class geospatial object detection based on a position‐sensitive balancing framework for high spatial resolution remote sensing imagery
[4]에서는 Faster R‐CNN 프레임워크에 기반하여 기존의 RPN에 multi‐angle anchors를 도입함으로써 rotation‐insensitive RPN을 제안함. geospatial object의 회전 변화 문제를 효율적으로 다루고자 함. 추가로, appearance의 모호함 문제를 다루기 위해 local 및 contextual 특성을 학습할 수 있도록 double‐channel feature combination network를 고안함.
[5]에서는 차량 검출을 목표로, 차량과 유사한 region을 찾기 위해 hyper region proposal network(HRPN)을 제안하고, 검출 정확도의 개선을 위해 hard negative mining을 사용함.
[6]에서는 객체의 기하학적 변화를 모델링하기 위해 deformable CNN을 제안함. 잘못된 region proposals이 증가하는 것을 줄이기 위해 종횡비 제약이 적용된 non‐maximum suppression을 개발함.
[10]에서는 생성된 region proposal의 품질을 향상시키기 위해 position‐sensitive balancing(PSB) 기법을 활용함. image classification에 있어서 translation‐invariance와 object detection에 있어서 translation‐variance 사이의 딜레마를 다루기 위해 residual network에 기반한 fully convolutional network(FCN)를 도입함.
2) 다른 딥러닝 기반 기법들을 이용한 연구들
R‐CNN 및 Faster R‐CNN 및 이들의 변종들과 같은 region proposal‐based 기법들이 상당한 성능 향상을 보였지만, 다른 딥러닝 기반의 기법을 적용하는 연구들도 진행이 됨.
관련 연구들 목록
- [1] Fully Convolutional Network With Task Partitioning for Inshore Ship Detection in Optical Remote Sensing Images
- [2] Rotation‐Invariant Object Detection in High‐Resolution Satellite Imagery Using Superpixel‐Based Deep Hough Forests
- [3] Ship Detection in Spaceborne Optical Image With SVD Networks
[2]에서는 geospatial objects를 검출하기 위해 회전에 불변하는 기법을 제안함. 단계 1에서는 local patches를 생성하기 위해 super‐pixel segmentation 전략을 적용함. 단계 2에서는 local patches에 대한 고수준의 feature representation을 구성하기 위해 deep Boltzmann machines을 적용함. 단계 3에서는 객체의 중심을 찾기 위해 회전 불변에 voting 하도록 multi‐scale Hough forests의 set이 구축됨.
[3]에서는 배 검출을 목적으로 함. 배와 유사한 region을 얻기 위해 singular value decompensation network를 사용하고, 배 후보군들에 대한 검증을 위해 feature pooling 연산과 linear SVM classifier를 적용함.
이러한 검출 프레임워크들은 비록 흥미롭긴 하지만, 여전히 훈련이 느리며 다루기 힘든 단점이 존재함.
3) regression‐based 객체 검출에 기반한 연구들
자연 영상에서 실시간 객체 검출을 위한 regression-based 기법들을 원격 탐사 영상에서도 적용하려는 연구들이 시도되고 있음.
관련 연구들 목록
- [1] Arbitrary‐Oriented Vehicle Detection in Aerial Imagery with Single Convolutional Neural Networks
- [2] Learning a Rotation Invariant Detector with Rotatable Bounding Box
- [3] Arbitrary‐Oriented Ship Detection Framework in Optical Remote‐Sensing Images
[1]에서는 SSD와 유사한 아이디어를 사용하여, regression‐based object detector를 운송 수단을 검출하는데 적용함. feature map 위치마다 서로 다른 scale의 default boxes set을 적용하여 detection bounding boxes를 생성함. 각각의 default box에 대해 offsets이 객체 모양에 좀 더 fit될 수 있도록 예측되어짐.
[2]에서는 전통적인 bounding box를 rotatable bounding box (RBox)로 대체하여 SSD 프레임워크에 넣음. 객체의 방향 각도를 추정할 수 있으므로 회전에 불변할 수 있게 됨.
[3]에서는 임의의 방향을 가진 배를 검출하는 프레임워크를 제안함. YOLOv2를 기본적인 네트워크로 사용하여, rotated 및 oriented bounding boxes를 직접적으로 예측함.
4) 성능 향상을 위한 추가 기법 연구들
hard example mining 적용
- [1] Arbitrary‐Oriented Vehicle Detection in Aerial Imagery with Single Convolutional Neural Networks
- [2] Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining
multi‐feature fusion 적용
transfer learning 적용
non‐maximum suppression 적용
- [1] Deformable ConvNet with Aspect Ratio Constrained NMS for Object Detection in Remote Sensing Imagery
비록 딥러닝 기반의 기법들이 지구 관측 분야에서 객체 검출 시 상당한 성능 향상을 가져왔지만, 이러한 기법들은 대부분 자연 영상에서 사용했던 기법들(R-CNN, Faster R-CNN, SSD 등)을 전이한 것임.
초기에도 언급했지만, 지구 관측 영상과 자연 영상은 회전 정도, scale 변화, 복잡하고 어지러운 배경 등의 상당한 차이점이 존재하며, 성능 개선을 위한 연구가 여전히 더 필요함.
4. Proposed DIOR Dataset
지구 관측 분야용 객체 검출 데이터셋의 제작은 많은 발전이 있었지만 여전히 아래와 같은 이유로 단점들이 있음. 이미지 개수의 부족, 객체 카테고리의 규모가 작음, 이미지의 다양성 및 객체의 변량이 불충분함.
이러한 같은 단점들을 극복하기 위해 DIOR 데이터셋이 제안되었으며, 사이트(http://www.escience.cn/people/gongcheng/DIOR.html)에서 공용으로 이용 가능함.
4.1 Object Class Selection
지구 관측 분야와 관련된 모든 데이터셋을 조사하여, 가장 많이 사용되는 10개의 object class를 우선적으로 선정함. 추가로 실제 어플리케이션에서 중요한 역할을 할 수 있는 class들을 10개 더 선정함. 총 20개의 object class는 아래와 같음.
- 비행기, 공항, 야구장, 농구코트, 다리, 굴뚝, 댐, 고속도로 휴게소, 고속도로 요금소, 항구, 골프장, 육상 경기장, 고가도로, 배, 스타디움, 저장 탱크, 테니스 코트, 기차역, 운송수단, 풍차
4.2 Characteristics of Our Proposed DIOR Dataset
지구 관측 분야와 관련된 객체 검출용 데이터셋 중에 가장 크며, 다양성을 갖고 있고, 공용으로 이용 가능함. LabelMe를 이용하여 annotation 수행하였으며, horizontal bounding box 타입을 가짐.
클래스 당 object instance 개수는 아래와 같음.
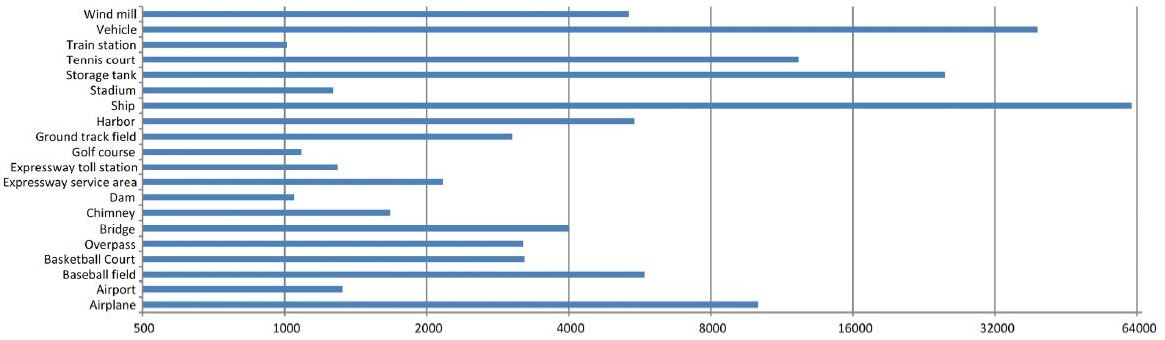
객체 크기의 다양성은 실세계 task에서 많은 도움이 되며 아래 그림과 같이 작은 크기의 객체와 큰 크기의 객체 사이의 균형을 잘 맞춤.
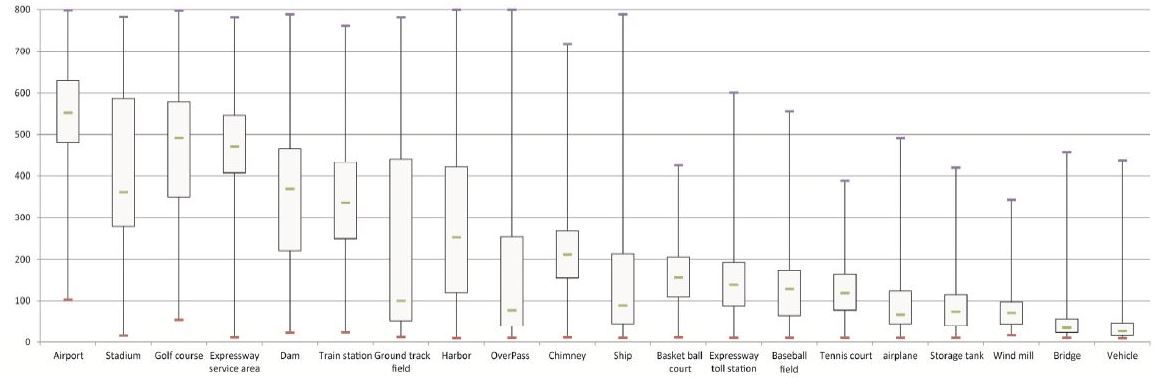
서로 다른 카테고리에 대해 객체 크기가 상당한 차이를 갖고 있는 경우, detector가 작은 크기의 객체와 큰 크기의 객체를 동시에 유연하게 다뤄야 하기 때문에 도전적인 detection task라고 할 수 있음.
기존 객체 검출용 데이터셋과의 차별적인 4가지 특징은 아래와 같음.
1) 대규모
- 이미지 개수(23,463개)
- 객체 instance 개수(192,472개)
- 객체 카테고리 개수(20개)
- 이미지 크기(800 x 800)
- 공간 해상도(0.5m~30m)
- Google Earth를 통해서 수집
- 현존하는 가장 큰 규모의 데이터셋임.
2) 이미지 변화의 풍부함
- 23,463개의 이미지를 갖고 있으며 80개 이상의 지역에서 수집됨.
- 날씨, 계절, 시점, 이동, 조명, 배경, 객체 pose, appearance, occlusion 등을 고려하여 풍부한 변화를 갖도록 수집됨.
3) 큰 범위의 객체 크기 변화
- 센서의 공간 해상도뿐만 아니라 class 사이의 크기 변화(예: 항공모함 vs 자동차), class 내 크기 변화(예: 항공모함 vs 돛단배) 등으로 인해 geospatial objects는 공간적인 크기 변화를 갖게 되는 특징이 있음.
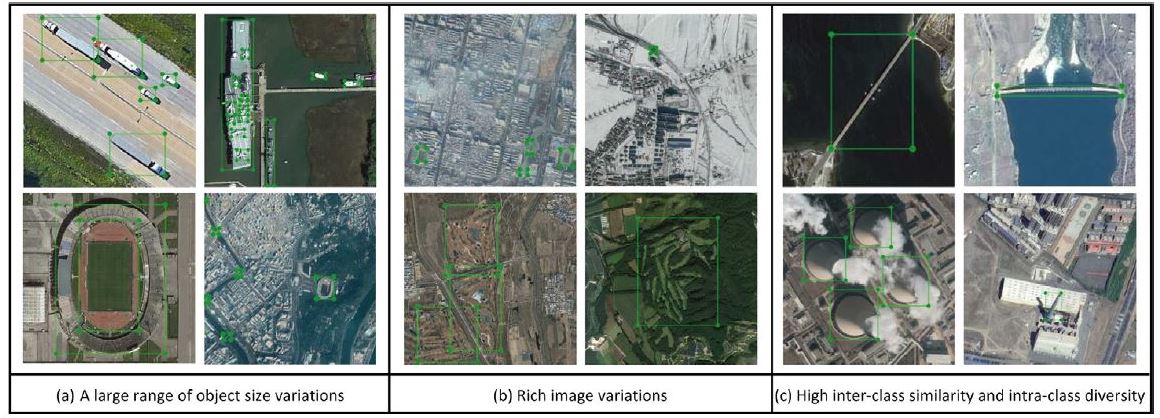
- 다양한 크기의 객체 instance를 갖도록 수집되었어짐. 아래 그림 (a)의 "운송수단"과 "배" instance는 서로 다른 크기를 갖고 있으며, 서로 다른 공간 해상도로 인해 "스타디움" instance의 객체 크기도 서로 다름.
4) class 간(inter‐class)의 높은 유사도 및 class 내(intra‐class)의 높은 다양성
- class 간의 유사도를 높이고, class 간의 다양성을 높여서 도전적인 데이터셋을 만듬.
- class 간의 유사도를 높이기 위해, "다리" vs "고가도로", "다리" vs "댐", "육상경기장" vs "스타디움", "테니스 코트" vs "농구 코트" 등의 의미가 겹치는 fine‐grained object classes를 추가시킴.
- class 간의 다양성을 높이기 위해, 이미지 수집 시 다양한 객체 색상, 모양, scale 등의 요소를 고려함. 아래 그림 (c)의 "굴뚝" instance는 다른 모양을 가지고 있으며, "댐"과 "다리" instance는 매우 유사한 모양을 가지고 있음.
5. Benchmarking Representative Methods
향 후 연구를 위한 최신의 overview 제공을 위해 딥러닝 기반 객체 검출 기법들에 대해 제안한 DIOR 데이터셋을 이용하여 벤치마킹을 수행함.
5.1 Experimental Setup
훈련-검증 및 테스트 데이터의 분포를 맞추기 위해 전체 데이터셋의 50%를 훈련-검증 데이터(11,725개)로, 나머지를 테스트 데이터(11,738개)로 랜덤하게 선택하여 나눔. bounding box와 ground truth가 50% 이상 겹쳐진 경우에만 true positive로, 그렇지 않은 경우에는 false positive로 간주함. 하드웨어는 single Intel core i7 CPU, memory 64 GB, NVIDIA Titan X GPU 를 이용함. 아래 표는 데이터셋의 구성을 나타냄.
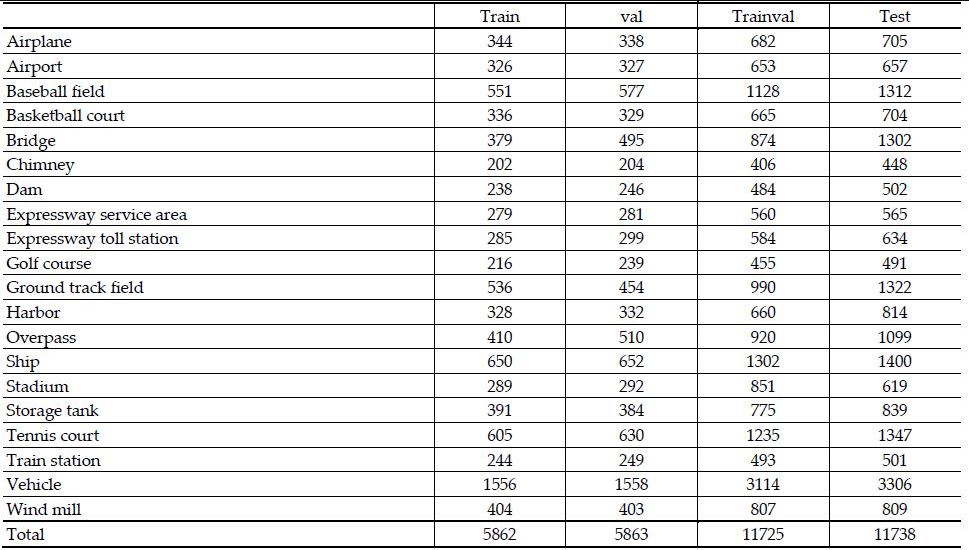
자연 영상 및 지구 관측 분야에서 사용되었던 딥러닝 기반 객체 검출 기법 12개를 이용하여 실험을 수행함. 공정함을 위해 논문의 실험에서 사용된 세팅들을 동일하게 설정함. average precision(AP)와 mean AP를 성능 평가를 위한 측정 방식으로 이용함.
region proposal based 기법들
- 1) R‐CNN
- 2) RICNN(with R‐CNN framework)
- 3) RICAOD
- 4) Faster R‐CNN
- 5) RIFD‐CNN(with Faster R‐CNN framework)
- 6) Faster R‐CNN with FPN
- 7) Mask R‐CNN with FPN
- 8) PANet
regression based 기법들
backbone 네트워크
- VGG16: 1), 2), 3), 4), 5), 10)
- Darknet‐53: 9)
- ResNet‐50 및 ResNet‐101: 6), 7), 8), 11)
- Hourglass‐104: 12)
5.2 Experimental Results
12개의 기법들에 대한 실험 결과는 아래와 같으며, 각 object 카테고리에서 AP가 가장 높은 경우 볼드체로 나타냄.
object 카테고리별 AP가 가장 높은 기법들
- 비행기: 9) YOLOv3(72.2)
- 공항: 12) CornerNet(84.2)
- 야구장: 5) RIFD‐CNN(with Faster R‐CNN framework)(79.9)
- 농구코트: 11) RetinaNet(backbone 네트워크: ResNet-101)(85.0)
- 다리: 12) CornerNet(46.4)
- 굴뚝: 12) CornerNet(75.3)
- 댐: 12) CornerNet(64.3)
- 고속도로 휴게소: 12) CornerNet(81.6)
- 고속도로 요금소: 12) CornerNet(76.3)
- 골프장: 12) CornerNet(79.5)
- 육상 경기장: 12) CornerNet(79.5)
- 항구: 5) RIFD‐CNN(with Faster R‐CNN framework)(51.2)
- 고가도로: 12) CornerNet(60.6)
- 배: 9) YOLOv3(87.4)
- 스타디움: 5) RIFD‐CNN(with Faster R‐CNN framework)(73.6)
- 저장 탱크: 9) YOLOv3(68.7)
- 테니스 코트: 9) YOLOv3(87.3)
- 기차역: 7) Mask R‐CNN with FPN(backbone 네트워크: ResNet-101)(62.3)
- 운송수단: 9) YOLOv3(48.3)
- 풍차: 8) PANet(backbone 네트워크: ResNet-50)(86.7)
mAP가 높은 기법들
- 11) RetinaNet(backbone 네트워크: ResNet-101)(66.1)
- 8) PANet(backbone 네트워크: ResNet-101)(66.1)
결과 분석
- (1) backbone 네트워크가 깊어질수록 네트워크의 representation capability가 강해지며, 더 높은 검출 정확도를 얻을 수 있음. backbone 네트워크에 대한 성능 평가는 "ResNet‐101=Hourglass‐104 > ResNet50=Darknet‐53 > VGG16" 와 같음. backbone 네트워크를 ResNet-101을 이용한 11) RetinaNet과 8) PANet이 가장 높은 mAP(66.1)를 얻음.
- (2) CNN은 forward propagation를 통해 자연스럽게 feature pyramid를 형성하므로, feature pyramid networks를 구성하기 위해 FPN과 PANet 같이 CNN의 고유한 pyramidal hierarchy를 활용하는 것은 검출 정확도를 크게 향상시킬 수 있음. 기본적인 Faster R‐CNN 이나 Mask R‐CNN 시스템에 FPN을 사용함으로써, 다양한 범위의 scale를 갖는 객체를 검출하는데 상당한 도움이 됨. 위와 같은 이유로, RetinaNet 이나 PANet 등과 같으 최신의 detector들은 FPN을 기본적인 building block으로 사용하고 있음.
- (3) YOLOv3의 경우 작은 크기의 object instance(예: 운송수단, 저장 탱크, 배)를 검출하는데 있어서 다른 기법들보다 좀 더 높은 검출 정확도를 보임. 특히 배 class에 대해서 다른 11개의 기법들보다 훨씬 더 우수한 성능(87.4)를 보임. 이는 backbone 네트워크 Darknet‐53이 객체 검출 task에 맞도록 고안되어 있으며, FPN처럼 3개의 서로 다른 scale로부터 좀 더 풍부한 feature를 추출할 수 있도록 새로운 multi‐scale prediction을 도입했기 때문으로 추측됨.
- (4) 배, 비행기, 농구 코트, 운송 수단, 다리 등의 object class에 대해서는 RIFD‐CNN, RICAOD, RICNN 등이 Faster R‐CNN 및 R‐CNN의 기본적인 접근 방식보다 우수한 검출 성능을 보임. 원격 탐사 영상에서 geospatial object의 회전 변화 문제를 다루기 위해 feature representations을 풍부하게 할 수 있도록 다른 전략들을 제안했기 때문임. RICAOD에서는 회전-둔감(rotation‐insensitive) region proposal network를 제안함. RICNN에서는 새로운 fully‐connected layer를 추가하여 회전-불변(rotation‐invariant) CNN을 제안함. RIFD‐CNN에서는 CNN 모델 아키텍처를 변경하지 않고, 회전-불변 및 Fisher discriminative CNN을 학습할 수 있도록 새로운 objective functions을 제안함.
- (5) CornerNet은 20개의 object class 중에 9개의 class에서 가장 우수한 성능을 보였으며, object를 한 쌍의 bounding box corners로 검출하는 것은 상당히 유망한 연구 방향임을 보여줌.
- 몇몇 object 카테고리에 대한 결과는 우수한 편이지만, 거의 모든 object 카테고리가 실질적인 개선을 필요로 함. 다리, 항구, 고가도로, 운송 수단 등에서는 검출 정확도가 매우 낮으며, 현존하는 방법들로는 만족스러운 결과를 얻기 힘듬. 이는 자연 영상 대비 이미지 품질이 낮고, 복잡하고 어지러운 배경을 갖고 있기 때문이며, 제안한 DIOR이 도전적인 데이터셋임을 나타냄.
성능 향상을 위한 향 후 연구 방향
- SNIP 및 SNIPER와 같은 새로운 훈련 전략을 기존의 여러 detector(Faster R‐CNN, Mask R‐CNN, R‐FCN, deformable R‐FCN 등)에 적용하면 좀 더 우수한 결과를 보일 수 있을 것이라 예상이 됨.
6. Conclusions
컴퓨터 비전 및 지구 관측 분야에서 사용되는 벤치마크 데이터셋과 최신의 딥러닝 기반 객체 검출 기법에 대한 발전에 대해 살펴봄. 대규모의 공개 데이터셋 DIOR을 제안하였으며, 지구 관측 분야에서 딥러닝 기반 객체 검출 기법을 위한 향 후 연구에 도움이 될 수 있음. 제안한 데이터셋을 이용하여 대표적인 객체 검출 기법들에 대한 성능 평가를 수행하였고, 실험 결과는 향 후 연구를 위한 유용한 성능 기준이 될 수 있음.

