link: arxiv.org/pdf/2011.13534.pdf
Abstract
- 문서는 법률, 금융, 기술 등의 여러 분야에서 많은 비지니스의 핵심적 역할을 하며, 문서를 자동으로 이해하는 것은 여러 새로운 비지니스의 길을 열어줌.
- 자연어 처리 및 컴퓨터 비전 분야는 딥러닝의 발전을 통해 상당한 진전을 이루었고 현대의 문서를 이해하는 시스템에 도입이 되기 시작함.
- 본 논문에서는 영어로 작성된 문서 이해를 위한 다양한 기술들을 검토하고 이 분야를 연구하는 연구자들에게 출발점 역할을 하기 위해 현존하는 방법론들을 통합함.
1 Introduction
인간은 정보를 기록하고 보존하기 위해 문서를 작성하며, 정보 운반 수단으로써 문서는 다양한 소비자들을 고려하여 다양한 정보들의 집합을 나타내기 위해 다양한 레이아웃을 사용함.
- 본 논문에서는 영어로 작성된 문서를 이해하는 문제를 다루고 있으며, 여기서 문서 이해는 문서 페이지에 포함된 텍스트 및 그림에서 정보를 읽고, 해석하고, 추출하는 자동화된 프로세스를 의미함.
- 본 논문에에서는 기계 학습을 다루는 실무자 관점에서 원래 사람이 소비하도록 작성된 문서를 자동으로 이해하는 모델을 만드는 방법을 다룸.
- 문서를 이해하는 모델은 문서에서 문서 내 특정 페이지를 유용한 부분(예: 특정 표나 속성에 해당하는 영역)으로 분할하며, 이를 위해 문서 레이아웃 분석 시 일정 수준에서 광학 문자 인식(OCR, Mori et al., 1999)을 많이 사용함.
- 이러한 모델들은 이러한 정보들을 사용하여 어떤 영역이나 바운딩 박스가 주소에 해당되는지 등의 문서의 전반적인 내용을 이해함.
- 본 논문은 보다 세부적인 수준에서의 문서 이해를 위한 측면에 초점을 두고 이러한 task에 많이 사용되는 기법들에 대해 논의를 함.
- 본 논문은 현대의 문서 이해를 위해 존재하는 접근 방식들을 요약하고 현재의 추세와 한계점을 강조하는데 목적을 두고 있음.
2장에서는 최신의 NLP 및 문서 이해를 위한 몇가지 일반적인 주제에 대해 논의하고 end-to-end 방식의 자동화된 문서 이해 시스템 구축을 위한 틀을 제공함. 3장에서는 text detection(3.1) 및 transcription(3.2)를 모두 포함하는 OCR를 위한 최상의 방법들을 살펴봄. 4장에서는 문서 이해 문제에 대한 보다 넓은 관점에서 문서 레이아웃 분석(예: 각 페이지에서 관련된 정보를 찾는 문제)을 위한 다양한 접근 방식들을 제시함. 5장에서는 정보 추출을 위한 대중적인 접근법들에 대해 논의함.
2 Document Processing & Understanding
문서 처리는 역사적으로 handcrafted된 rule 기반의 알고리즘들(Lebourgeois et al., 1992; Ha et al., 1995; Amin and Shiu, 2001)을 포함하고 있지만, 딥러닝의 광범위한 성공을 활용하여(Collobert and Weston, 2008; Krizhevsky et al., 2012; Sutskever et al., 2014), 컴퓨터 비전 및 자연어 처리에 기반한 기법들이 주목을 받게 됨.
- 객체 검출 및 영상 분할의 발전(Redmon et al., 2016; Lin et al., 2017)은 시스템이 다양한 task에서 인간 수준에 가까운 성능을 보이도록 만들었으며, 결과적으로 이러한 방법들은 자연어 처리 및 음성 등을 포함하는 다양한 다른 분야에도 적용이 됨(Gehring et al., 2017; Wu et al., 2018; Subramani and Rao, 2020).
- 문서는 시각 정보를 전달하는 매체로서 읽혀지고 보여져야 하기 때문에 많은 실무자들은 컴퓨터 비전 기술을 text detection(3.1 참고) 및 instance segmenation(4.1 참고)을 위해 사용함(Long et al., 2018; Katti et al., 2018).
ELMo 및 BERT와 같이 대규모로 pre-trained된 언어 모델의 광범위한 성공과 인기는 문서 이해를 딥러닝 기반 모델을 사용하는 쪽으로 전환시킴(Peters et al., 2018; Devlin et al., 2019).
- 이러한 모델들은 다양한 task들에 대해 fine-tunning이 가능하며, 자연어 task에 대한 pretraining을 위한 사실상의 표준으로 word vectors를 대체함.
- 하지만, recurrent neural network 기반 및 transformer 기반(Vaswani et al., 2017)의 언어 모델은 긴 시퀀스(Cho et al., 2014a; Subramani et al., 2019; Subramani and Suresh, 2020)에 대해 우수한 성능을 보이지 못함.
- 비지니스 문서 내 text가 매우 조밀하며 길어질 수 있다는 점을 고려했을 때 모델 아키텍처의 수정은 필수적임.
- 가장 간단한 접근 방식은 pretrained된 언어 모델을 바로 사용할 수 있도록 문서를 512개 token의 더 작은 sequence로 줄이는 것임(Xie et al., 2019; Joshi et al., 2019).
- 최근에 설득력을 얻은 또 다른 접근 방식은 transformer 기반 언어 모델의 self-attention component의 복잡성을 줄이는 것에 기반하고 있음(Child et al., 2019; Beltagy et al., 2020; Katharopoulos et al., 2020; Kitaev et al., 2020; Choromanski et al., 2020).
- 관련 문헌에 존재하는 효과적이고 최신적인 end-to-end 방식의 문서 이해 시스템들은 모두 문서 내 내용을 읽고 이해하기 위해 다수의 deep neural network를 통합하는 방식을 사용함.
문서는 기계가 아닌 사람을 위해 만들어졌기 때문에 실무자들은 자연어 처리 뿐만 아니라 컴퓨터 비전을 통합된 솔루션으로 결합해야 함. 특정한 use case에 대해서는 사용된 정확한 기술이 나타나는 반면, 완전한 end-to-end 시스템은 다음을 사용하게 됨.
- 1) 컴퓨터 비전 기반의 문서 레이아웃 분석 모듈: 이 모듈은 각각의 문서 페이지를 개별적인 컨텐츠 영역으로 분할함. 이 모델은 관련된 영역과 무관한 영역을 설명할 뿐만 아니라 식별된 컨텐츠 유형을 분류하는 역할도 함.
- 2) Optical Character Recognition(OCR) 모델: 문서 내 작성된 모든 text를 찾아서 충실하게 전사(transcription)하는 것을 목적으로 함. 컴퓨터 비전과 자연어 처리 사이의 경계를 넓히면서 OCR 모델은 문서 레이아웃 분석을 직접적으로 사용하거나 독립적인 방식으로 문제를 해결할 수 있음.
- 3) 정보 추출 모델: OCR 또는 문서 레이아웃 분석의 출력을 이용하여 문서에서 전달되는 정보 간의 관계를 이해하고 식별함. 보통 특정 도메인과 작업에 특화된 이러한 모델들은 문서를 기계가 읽을 수 있도록 만드는데 필요한 구조를 제공하여 문서 이해를 위한 유용성을 제공함.
다음 장부터는 end-to-end 문서 이해 솔루션을 구성하는 이러한 개념을 확장하여 나타낼 예정임.
3 Optical Character Recognition
OCR은 주로 text detection과 text transcription의 2개의 구성 요소로 되어 있음. 일반적으로 이러한 2개의 구성 요소는 개별적이며, 각 task 별로 서로 다른 모델들을 적용함. 이러한 구성 요소들 각각에 대한 최신의 기법들에 대해 논의할 예정이며, 서로 다른 일반적인 OCR 시스템에서 문서가 어떻게 처리되는지에 대해 살펴볼 예정임. 상세한 내용은 아래 그림 1을 참고하길 바람.
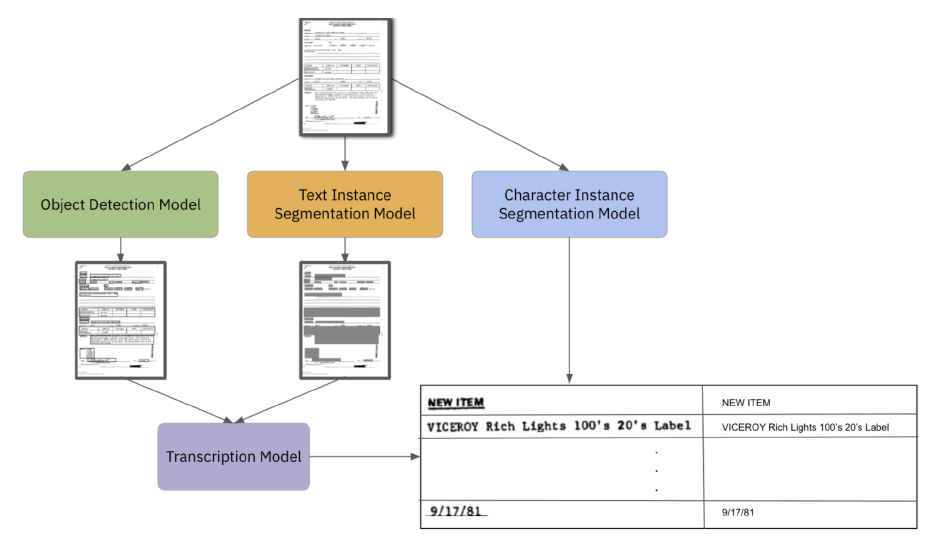
그림 1: 일반적인 OCR 처리에 대한 설명
- 왼쪽 경로: object detection 모델을 통과하여 bounding boxes를 출력하고, transcription 모델을 통과하여 각각의 bounding boxes 내 text를 전사하게 됨.
- 가운데 경로: objects는 일반적인 text instance segmentation 모델을 통과하여 text가 포함된 경우 픽셀이 검은색으로 칠해지며, text transcription 모델을 통과하여 instance segmentation이 식별한 text 영역을 전사하게 됨.
- 오른쪽 경로: character별 instance segmentation 모델을 통과하여 픽셀에 해당하는 문자를 출력하게 됨.
모든 경로는 동일한 구조화된 출력을 생성하게 되며, 이 문서는 FUNSD (Jaume et al., 2019)에서 가져옴.
3.1 Text Detection
text detection은 페이지나 이미지 내 나타난 text를 찾는 task이며, 보통 입력 이미지는 3차원의 tensor(C x H x W, C: red, green, blue에 대한 채널의 개수, H: 이미지 높이, W: 이미지 너비)로 표현이 됨.
- text detection은 다양한 모양과 방향을 가진 text가 종종 왜곡되어 나타나기 때문에 도전적인 문제임.
- 연구자들이 text detection 문제를 다루는 방법은 크게 2가지의 영상을 취함:
- 1) text detection task: text 주변의 bounding boxes 좌표의 출력을 학습시킴.
- 2) instance segmentation task: text를 가진 픽셀은 표시되고 없는 픽셀은 표시되지 않는 mask를 학습시킴.
3.1.1 Text Detection as Object Detection
- 전통적으로 text detection은 characters를 검출하기 위해 hand-crafting features를 사용하는 방식으로 연구됨(Matas et al., 2004; Lowe, 2004).
- 딥러닝, 특히 object detection 및 semantic segmentation의 발전으로 text detection을 다루는 연구 방향에 변화가 생김.
- 실무자들은 전통적인 컴퓨터 비전에서 나온 우수한 object detectors들인 Single-Shot MultiBox Detector(SSD, Liu et al., 2016)와 Faster R-CNN(Ren et al., 2015) 등을 활용하여 text detector를 효율적으로 구축함.
- text에 대해 regression 기반의 detector를 적용한 처음 논문 중 하나는 TextBoxes(Liao et al., 2016, 2018a)임.
- object detector를 text에 적합하도록 SSD에 종횡비가 긴 default boxes를 추가함.
- 몇몇 논문들은 regression 기반 모델들이 방향에 대처할 수 있도록 위의 연구에 기반하여 수행됨.
- Deep Matching Prior Network (DMPNet) 및 Rotation-Sensitive Regression Detector(RRD) (Liu and Jin, 2017; Liao et al., 2018b).
- 다른 논문들도 문제에 대해 유사한 접근 방식을 취하고 있지만 자연 이미지보다는 text에 맞춰 조정된 자체적인 네트워크를 개발함.
- Tian et al. (2016)는 수평 방향의 text에 대한 정확도를 개선하기 위해 Connectionist Text Proposal Network 내 수직 방향의 anchor 메커니즘을 사용하여 convolutional networks 와 recurrent networks를 결합시킴.
object detection 모델은 보통 intersection over union (IoU) metric과 F1 score를 사용하여 평가가 됨.
- 이러한 metric은 후보 bounding box와 ground truth bounding box가 교차(intersection)되어 겹치는 정도를 후보 bounding box와 ground truth bounding box가 결합(union)되어 차지하는 총 공간으로 나눈 값으로 계산됨.
- 그 다음 IOU 임계값 T를 선택하여 어떤 예측된 boxes가 true positives로 계산되는지 결정( IOU >= T)하며, 나머지는 false positives로 분류함. 모델이 검출에 실패한 boxes들은 false negatives로 분류함.
- 이러한 정의를 사용하여 F1 score는 object detection 모델을 평가하기 위해 계산됨.
3.1.2 Text Detection as Instance Segmentation
문서 내 text detection은 고유한 도전적인 요소들이 있음.
- text는 보통 조밀하며, 문서는 자연 이미지보다 훨씬 더 많은 text를 포함하고 있으므로 이러한 밀도 문제를 대처하기 위해 text detection은 ultra-dense한 instance segmentation task로 제기될 수 있음.
- instance segmentation은 이미지 내 각 픽셀을 미리 정의된 특정한 카테고리로 분류하는 task임.
- segmentation 기반 text detector들은 text 영역의 식별을 위해 픽셀 수준으로 동작하며, 이러한 픽셀 단위 예측은 종종 통합된 프레임워크 안에서 text 영역, characters, 그리고 인접한 characters 간의 관계에 대한 확률을 추정하는데 사용됨.
- 실무자들은 text를 검출하기 위해 FCN (Fully Convolutional Networks)과 같은 유명한 segmentation 기법들을 사용(Long et al., 2015)하며 특히 text가 잘못 정렬되었거나 왜곡된 경우를 위해 object detection 모델들을 개선시킴.
- 몇몇 논문들은 이러한 segmenation 기초에 기반하여, segmentation 출력으로부터 직접 경계 영역을 추출하여 word 경계 영역을 추출함(Yao et al., 2016; He et al., 2017a; Deng et al., 2018).
- TextSnake(Long et al., 2018)는 FCN에서 text 영역, 중심선, text 방향, 후보 반경 등을 예측함으로써 이러한 연구를 더욱 더 확장시킴. 그 다음에 이러한 특징들은 striding 알고리즘과 결합하여 중앙 축 점(central axis points)을 추출하며, text instance를 재구성함.
3.2 Word-level versus character-level
위에서 인용된 대부분의 논문은 word 또는 word의 line을 직접적으로 검출하려 하지만, 몇몇 논문들에서는 character가 text line 또는 word 보다 모호함이 적기 때문에 일반적인 text detection보다 character-level의 detection이 보다 쉬운 문제라고 주장함.
- CRAFT(Baek et al., 2019)는 FCN 모델을 사용하여 각 character에 대한 2차원의 가우시안 히트맵을 출력함. 그 다음에 서로 가까운 character들은 character들의 집합을 캡슐화 할 수 있는 가장 작은 영역을 가진 회전된 직사각형으로 함께 그룹화됨.
- 보다 최근에 Ye et al. (2020)는 Region Proposal Networks (RPN)을 사용하여 획득한 global, word-level, character-level 의 특징들을 결합함으로써 우수한 성능을 보임.
위에서 설명한 대부분의 모델들은 주로 text scene을 detection하기 위해 개발되었지만, 왜곡된 text와 같이 어려운 경우를 처리하기 위해 문서 내 text detection에도 쉽게 적응할 수 있음. 자연 이미지보다 문서의 왜곡이 적을 것으로 예상하지만, 제대로 스캔되지 않은 문서나 특정한 글꼴이 있는 문서는 여전히 이러한 문제를 일으킬 수 있음.
3.3 Text Transcription
text transcription은 이미지에 나타난 text를 전사하는 task를 말하며, 입력 이미지는 종종 character, word 또는 word sequence에 해당하는 부분이 crop되며 C x H` x W` 의 차원을 가짐.
- text transcription 모델은 이렇게 crop된 이미지를 수집하고 미리 정의된 vocabulary V에 속하는 token sequence를 출력하는 법을 학습하며, V는 종종 character들의 집합에 해당함.
- 예를 들어 숫자 인식의 경우 가장 직관적인 접근에 해당됨(Goodfellow et al., 2013). 그렇지 않은 경우 V는 word-level의 언어 모델링 문제와 유사하게 word들의 집합에 해당될 수도 있음(Jaderberg et al., 2014).
- 두 경우 모두 문제는 vocabulary V의 크기와 동일한 클래스 수를 갖는 다중 클래스 분류 문제로 여겨질 수 있음.
word-level의 text transcription 모델은 다중 클래스 분류 문제의 클래스 수가 character-level 보다 훨씬 더 많기 때문에 더 많은 데이터를 필요로 함.
- 한편으로는 character 대신에 word를 예측하면 작은 오자(잘못된 글자)를 만들 확률이 줄어듬(예: "elephant" 와 같은 단어에서 "a"를 "o"로 대체하는 경우).
- 반면 word-level의 vocabulary로 자신을 제한한다는 것은 이 vocabulary의 일부가 아닌 단어들은 전사할 수 없다는 것을 의미함.
- 이러한 문제는 character-level에서는 character의 수가 제한되어 있기 때문에 존재하지 않게 됨.
- 문서의 언어를 아는 한, 가능한 모든 character들을 포함하는 vocabulary를 구축하는 것은 간단한 일임.
- subword 단위는 word 및 character-level 모두에 존재하는 문제를 완화하기 때문에 실행 가능한 대안임(Sennrich et al., 2016).
최근 학계의 연구는 recurrent neural networks, 특히 convolutional image의 feature extractor 위에 LSTM 또는 GRU unit이 있는 recurrent 모델을 사용하는 방향으로 이동함(Hochreiter and Schmidhuber, 1997; Cho et al., 2014b; Wang and Hu, 2017).
- token 전사를 위해 2개의 서로 다른 decoding 메커니즘이 종종 사용됨.
- 1) 조건부 언어 모델을 사용한 decoding과 똑같게 cross entropy loss를 적용한 attention 기반의 sequence decoder를 사용하여 standard한 greedy decoding이나 beam search를 하는 것임(Bahdanau et al., 2014). 때로는 이미지의 방향이 잘못되거나 정렬되지 않아 standard한 sequence attention의 효과가 떨어지기도 함. 이러한 문제를 극복하기 위해 He et al.(2018)는 attention 정렬을 사용하여 characters의 공간적인(spatial) 정보를 직접적으로 encoding한 반면에 Shi et al. (2016)는 공간적인 attention 메커니즘을 직접적으로 사용함.
- 2) connectionist temporal classification (CTC) loss(Graves et al., 2006)를 사용하며, 이는 sequence 내 반복되는 characters를 잘 출력하여 모델링하는 음성 분야에서의 일반적인 loss function임.
대다수의 text transcription 모델은 text와 음성 모두에 대한 sequence 모델링의 발전을 가져와 사용하며, 때론 약간의 조정만으로도 이러한 발전을 잘 활용할 수 있음. 결과적으로 실무자들은 문서 이해 task의 다른 구성 요소와 관련된 이러한 측면들을 직접적으로 다루지는 않음.
3.4 End-to-end models
end-to-end 접근은 text detection과 text transcription을 결합하여 이 두가지 요소들을 함께 개선시킴(Li et al., 2017). 예를 들어 만약 text의 예측된 확률이 매우 낮다면 검출된 box가 전체 word를 제대로 캡처하지 못했거나 text가 아닌 것을 캡처했다는 것을 의미하며, end-to-end 접근은 이러한 경우에 매우 효과적임.
- 이렇게 두가지 방법을 결합하는 것은 상당히 일반적이며 Fast Oriented Text Spotting(FOTS, Liu et al., 2018)과 Explicit Alignment 및 Attention을 사용하는 TextSpotter(He et al., 2018) 모두 이러한 모델들을 순차적으로 결합하여 end-to-end 방식으로 훈련을 시킴.
- 이러한 접근들은 text detection과 recognition 모두에 shared된 convolution을 특징으로 사용하며, text의 복잡한 방향을 처리하기 위한 방법을 구현함.
- Feng et al. (2019)은 관심 영역의 왜곡 보정에 특화된 differentiable한 관심 영역 slide operator를 활용하여, 왜곡된 text를 잘 처리할 수 있는 end-to-end 모델인 TextDragon을 도입함.
- Mask TextSpotter(Liao et al., 2020)는 bounding boxes에 대한 region proposal networks를 text 및 character segmentation과 결합하는 또 다른 end-to-end 모델임.
이러한 최근의 연구들은 오류를 줄이는데 있어서 end-to-end OCR 솔루션의 위력을 보여줌. 하지만 text detection 및 text recognition 모델을 별도로 사용하게 되면 보다 많은 유연성을 제공하게 됨.
- 2개의 모델을 개별적으로 훈련할 수 있음. 전체 OCR 모듈의 훈련을 위해 작은 데이터셋만 이용 가능하지만 많은 text recognition 데이터에 쉽게 접근할 수 있는 경우, 이러한 많은 양의 데이터를 recognition 모델의 훈련을 위해 활용하는 것이 타당함.
- 또한, 2개의 개별적인 모델을 사용하면 2개의 개별적인 metric을 쉽게 계산할 수 있으며, 어디서 병목 현상이 발생하는지에 대해 보다 완벽하게 이해를 할 수 있게 됨.
따라서 2개의 모델을 개별적으로 이용하여 결합하는 접근과 end-to-end 방식을 이용한 접근 모두 적용이 가능함. 어느쪽이 더 나은지의 여부는 이용 가능한 데이터와 달성하려는 목표에 따라 달라짐.
3.5 Datasets for Text Detection & Transcription
- 1) 대부분의 문헌들에서는 문서 내 text detection 보다는 장면 내 text detection를 다루고 있으며, 이러한 데이터셋에 대한 결과를 보고하고 있음. 예: ICDAR (Karatzas et al., 2013, 2015), Total-Text (Chung and Chan, 2017), CTW1500 (Yuliang et al., 2017), SynthText (Gupta et al., 2016)
- 2) FUNSD: Jaume et al. (2019)가 제안하였으며, text detection, transcription, document understanding을 위한 데이터셋으로 31k의 word level의 bounding boxes로 구성된 199개의 annotated된 양식을 포함하고 있음.
- 3) document understanding을 위한 또 다른 데이터셋은 ICDAR 2019 Robust Reading Challenge on Scanned Receipts OCR and Information Extraction (SROIE)에서 제공함.
- 1000개의 스캔된 영수증 이미지, text detection 및 transcription을 위한 line-level의 annotation, Key Information Extraction을 위한 labels 등을 포함하고 있음.
- 웹 사이트에는 이러한 문제를 해결하기 위해 제안된 솔루션들에 대한 순위가 포함되어 있으며, 대회 종료 후에도 여전히 솔루션들이 게시되기 때문에, 가장 최근의 기법들을 추적할 수 있는 좋은 방법임.
4 Document Layout Analysis
문서 레이아웃 분석은 하나의 페이지 그림 또는 스캔된 이미지 상에서 관심 영역의 위치를 찾아 분류하는 처리를 말함. 보통 대부분의 접근 방식은 페이지 분할 또는 논리적 구조(logical structural) 분석으로 정제될 수 있음(Binmakhashen and Mahmoud, 2019; Okun et al., 1999).
- 1) 페이지 분할 기법은 외관(appearance)에 초점을 두고 visual cue를 사용하여 페이지를 별개의 영역으로 분할하며, 보통 텍스트(text), 그림(figures), 이미지, 표(table) 등이 해당됨.
- 2) 대조적으로, 논리적 구조 분석은 이러한 영역들에 대해 더 세분화된(finer-grained) semantic classifications 즉, 단락(paragraph)에 해당하는 텍스트 영역을 식별하고 이를 캡션(caption) 또는 문서 제목과 구별하는데 초점을 두고 있음.
문서 레이아웃 분석과 관련된 연구들은 학계 및 업계에서 오랫동안 연구되었음(현대의 문서들에 대한 레이아웃 분석 측면을 정의한 최초의 ISO 표준은 40년 전에 작성되었음: ISO 8613-1:1989).
- 최초의 선구적인 연구인 휴리스틱 접근법(Lebourgeois et al., 1992; Okun et al., 1999; Liang et al., 1997)을 시작으로 multi-stage의 고전적인 기계 학습 시스템(Qin et al., 2018; Wei et al., 2013; Eskenazi et al., 2017)에 이르기까지 문서 레이아웃 분석과 관련된 연구들의 진화는 이제는 end-to-end가 가능한 다른 기법들에 의해 지배되고 있음(Yang et al., 2017; Binmakhashen and Mahmoud, 2019; Ares Oliveira et al., 2018; Agarwal et al., 2020; Monnier, 2020; Pramanik et al., 2020).
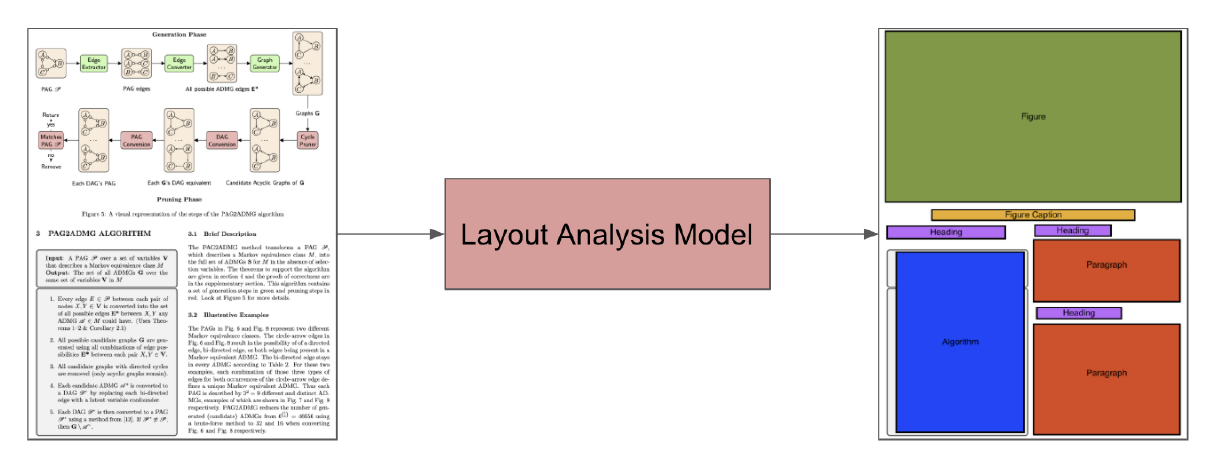
그림 2: 문서는 일반적인 레이아웃 분석 모델로 전달되며, 다음의 클래스들에 해당하는 레이아웃 분할 mask 결과를 갖음: 그림(녹색), 그림 캡션(주황색), 제목(보라색), 단락(빨간색), 알고리즘(파란색). 이 문서는 허락을 받고 복사됨(Subramani, 2016).
4.1 Instance Segmentation for Layout Analysis
비지니스 문서의 레이아웃 분석 문제에 적용될 경우, instance segmentation 기법은 픽셀 마다 레이블을 예측하여, 관심 영역을 분류함. 이러한 기법은 페이지 분할과 같은 좀 덜 세분화된(courser-grained) task나 논리적 구조 분석처럼 좀 더 구체적인 task에 유연하며 쉽게 적응될 수 있음.
- Yang et al. (2017)은 unsupervised 방식으로 pretraining된 network를 통합한 encoder-decoder 아키텍처에서 text 및 시각적 특징들을 함께 결합하는 end-to-end의 neural network를 제시함.
- 이 방법은 추론 동안에, pooling layers의 downsampling cascade를 이용하여 시각적 정보를 encoding하며 이는 decoding을 위한 대칭적인 upsampling cascade에 전달됨. 각각의 cascade level에 대해 생성된 encoding은 각자의 decoding block으로 직접 전달되어 downsampling 및 upsampling된 representations을 연결시킴(concatenating).
- 이러한 아키텍처는 encoding 및 decoding 과정 동안 다양한 level의 해상도에 대한 시각적 특징 정보를 고려하며(Burt and Adelson, 1983), 최종 decoding layer의 경우 localized된 text embedding이 계산된 시각적 representation과 함께 제공되어짐.
이러한 U-Net에서 영감을 받은 encoding-decoding 아키텍처는 문서 레이아웃 분석을 위한 여러 다른 접근 방식으로 채택되어짐(Ronneberger et al., 2015).
- Ares Oliveira et al. (2018)의 방법과 이후에 부가적인 text embedding을 통해 확장된 Barman et al. (2020)의 방법은 큰 크기의 필터를 가진 convolution maxpooling layers를 ResNet bottleneck (He et al., 2015)을 통해 문서 이미지를 전달하는데 사용함. 그 다음에 representation은 bilinear upsampling layers와 더 작은 크기의 1x1 및 3x3 convolution layers에 의해 처리되며, 두 연구는 각각 여러 유럽 언어의 역사적 문서와 신문에 대한 레이아웃 분석을 수행함.
- Lee et al. (2019)는 U-Net 아키텍처 패턴을 학습가능한 multiplication layers와 결합하였으며, 이러한 layer 타입은 network의 convolution feature maps에서 co-occurrence texture 특징들을 추출하는데 특화되어 있음. 이는 표와 같은 주기적으로 반복되는 정보가 있는 영역을 찾는데 효과적임.
4.2 Addressing Data Scarcity and Alternative Approaches
레이아웃 분석을 위한 고품질의 훈련 데이터를 얻는 것은 기계적인 정확도와 문서 내용에 대한 이해가 모두 필요한 노동 집약적인 task임. 새로운 도메인에 대한 문서 레이아웃의 annotation이 어렵기 때문에, 문서 레이아웃 분석 시스템의 일반화 및 성능을 향상시키기 위해 label이 없는 데이터의 구조를 활용하거나 잘 정의된 rule set을 사용하여 합성된 label이 있는 문서를 생성하는 몇 가지 접근 방식이 있음.
- BERT 및 RoBERTa와 같이 Masked된 언어 모델은 여러 downstream NLP tasks들에 대해 실험적으로 효율적인 성능을 보여줌(Devlin et al., 2019; Liu et al., 2019b).
- BERT 및 RoBERTa의 pretraining 전략으로부터 영감을 얻어, Xu et al. (2020)는 입력 token을 무작위로 mask하고 masked된 token을 예측하기 위해 모델을 사용하는 Masked Visual-Language Model을 정의함. BERT와 다르게 이들의 방법은 token에 대한 2-D positional embedding을 제공하며, 이를 통해 모델이 text 요소 사이의 의미(semantic)와 공간(spatial) 관계를 결합할 수 있도록 해줌.
- 4.1장에서 언급한 바와 같이, Yang et al. (2017)은 더 넓은 instance segmentation 기반 network에 보조(auxiliary) 문서 이미지 재구성 task를 도입함. 훈련 중에 이러한 보조 모듈은 별도의 upsampling decoder를 사용하여 skip connections의 도움 없이, encoded된 representation으로부터 원래의 픽셀 값을 예측함.
pretraining을 통해 실무자들이 label이 없는 문서에 대해 더 많은 가치를 얻을 수 있지만, 이러한 기술만으로는 데이터 부족 문제를 효과적으로 극복하기 어려움. 많은 비지니스 문서나 학술 문서가 내용과 페이지 별 구성 모두에서 반복되는 패턴을 가지고 있다는 직관에 따라, pretraining과 같은 루틴에 적합한 데이터를 제공하기 위해 label이 있는 합성 데이터를 만드는 여러 접근 방법들이 등장함(Zhong et al., 2019b).
- Monnier(2020)는 새로운 label이 있는 문서들을 합성하는 3단계 방법을 제안함.
- 1) 약 200개의 알려진 문서 배경 set에서 무작위로 문서 배경을 선택하여 문서를 생성함.
- 2) grid 기반의 레이아웃 기법을 이용하여 개별 문서의 요소별 내용과 해당되는 크기를 모두 정의함.
- 3) Gaussian blur 및 random image crops과 같은 corruptions을 적용하며, 이러한 모듈은 rule 기반의 합성 문서 생성을 위한 접근으로써, 레이아웃 분석 모델의 pretraining을 보다 강건하게 만들 수 있는 이기종(heterogeneous)의 데이터셋을 생성하게 됨.
이기종의 문서 set을 생성하기 위한 rule을 정의하는 대신에, 몇 가지 합성 절차는 data augmentation 기법들로부터 단서를 얻음.
- Capobianco와 Marinai(2017) 및 Journet (2017) 등은 기존의 label이 있는 문서 set을 이용하여, 원본 이미지에 deformations과 perturbations을 적용한 범용적인 툴킷을 만들었음.
- 중요한 것은 학습 데이터에 대한 이러한 변경 사항은 원래 의미에 대한 내용을 보존하는 동시에, 보이지 않는 데이터에 대한 추론 시 설명되어야 하는 현실적인 error에 모델 훈련을 노출시켜 균형을 맞춰야 한다는 것임.
4.3 Datasets for Layout Analysis
최근에는, 문서 레이아웃 분석 문제를 특별히 겨냥한 데이터셋이 많이 만들어지고 있음.
- 1) The International Conference on Document Analysis and Recognition (ICDAR): 매년 열리는 대회에서 여러가지 데이터셋을 만들었으며, 가장 최근인 2017년과 2019년에는 문서 레이아웃 분석과 기타 문서 처리 task들을 위한 훌륭한 기준이 되는(gold-standard) 데이터를 제공함(Gao et al., 2017; Clausner et al., 2019; Huang et al., 2019; Gao et al., 2019).
- 2) DocBank: 좀 더 큰 측면에 해당하는 50만개의 문서 페이지 모음으로써, 문서 레이아웃 분석 시스템을 훈련하고 평가하는데 적합한 token-level의 annotation이 포함되어 있음(Li et al., 2020). 저자들은 weak supervision (Hoffmann et al., 2011)을 이용하여 데이터셋을 구성하였으며, 이는 알려진 PDF의 LaTeX 소스에서 가져온 데이터를 매칭시켜 annotation을 생성함.
- 3) PubLayNet: Zhong et al. (2019b)은 PubMed Central™에서 백만개 이상의 PDF에 대한 XML 컨텐츠 표현을 자동으로 매칭시켜 약 36만개의 문서 이미지를 만듬.
- 4) PubTabNet: Zhong et al. (2019a)은 전체 문서에 대한 레이아웃은 아니지만, PubMed Central에서도 데이터셋을 만들었으며, 이는 컨텐츠에 대한 HTML 표현과 함께 56만 8천개의 표 이미지로 구성되어 있음.
5 Information Extraction
문서 이해를 위한 정보 추출의 목적은 다양한 레이아웃을 갖는 문서를 가져와서 구조화된 포맷으로 정보를 추출하는 것임.
- 예를 들어, 품목 이름, 수량, 가격 등을 식별하기 위한 영수증 이해와 key-value 쌍을 식별하기 위한 양식(form) 이해 등이 포함될 수 있음. 사람에 의한 문서 내 정보 추출은 페이지에 대해 단순히 text를 읽는 것을 넘어서게 되는데, 이는 완벽한 이해를 위해서는 페이지 레이아웃을 알아야 하는 경우가 많기 때문임.
- 이와 같이 최근의 성능 향상은 다양한 방법으로 text의 구조적, 시각적 정보를 추가적으로 encoding하여, 문서에 대한 text encoding 전략을 확장함으로써 이루어짐.
5.1 2D Positional Embeddings
정보를 추출 할 때 문맥적, 공간적 위치를 동시에 인식하는 모델을 만들기 위해, 2D bounding boxes의 속성을 embedding하고 이들을 text embedding과 병합함으로써, 현재 개체명 인식(NER, named entity recognition) 기법을 증강하여 다중 시퀀스를 태킹(multiple sequence tagging)하는 접근법이 제안됨.
- Xu et al. (2020)는 2개의 서로 다른 embedding table을 이용하여 bounding box를 정의하고, masked된 언어 모델을 pretrain하는 x, y 좌표 쌍을 embedding함. pretraining 동안에, text는 무작위로 masking 되지만, 2D 위치의 embedding은 유지가 됨.
- 이 모델은 downstream task 상에서 fine-tunning 하거나, 위치 encoding 기법들과 같은 sin 및 cos 함수를 사용하여 bounding box 좌표를 embedding 할 수도 있음(Vaswani et al., 2017; Hwang et al., 2020).
- line이나 sequence number와 같은 다른 feature들도 포함될 수 있으며(Hwang et al., 2019), 이러한 시나리오에서 문서는 각각의 개별적인 token에 하나의 line number를 할당할 수 있도록 전처리 됨. 그 다음에 각 token은 왼쪽에서 오른쪽으로 정렬되고 sequential position이 지정되어짐. 최종적으로 line과 sequential position 모두 embedding이 됨.
이러한 전략이 성공적이긴 했지만, 문서가 고르지 않은 표면에서 스캔되어 구부러진 text로 이어질 경우 line number나 bounding box 좌표에만 의존하는 것은 잘못된 결과를 만들 수 있음.
- 또한, bounding box 기반 embedding은 인쇄 강조(bold, italics) 및 로고와 같은 이미지 등에 대해 중요한 시각적 정보를 놓치게 됨.
- 이를 극복하기 위해, Faster R-CNN 모델을 사용하여 관심 token에 해당하는 crop 이미지를 embedding하여 2D positional embedding과 결합된 token image embedding을 만들 수 있음(Xu et al., 2020).
5.2 Image Embeddings
문서에 대한 정보 추출은 컴퓨터 비전 과제로도 비춰질 수 있으며, 여기서 모델의 목표는 정보를 semantic하게 분할하거나 관심 영역에 대한 bounding boxes를 regression하는 것임.
- 이러한 전략은 문서의 2D 레이아웃을 보존하는데 도움을 주며, 모델이 2D correlation을 활용할 수 있도록 해줌.
- 이론적으로 문서 이미지에 대해 엄격하게 학습할 수 있지만, text 정보를 이미지에 직접 embedding하면, 모델이 2D text 관계를 이해하는 task를 단순화 할 수 있음.
- 이러한 경우, encoding 함수가 제안된 textual level(예: character, token, word)에 적용되어 개별적인 embedding 벡터를 생성하게 됨. 이러한 벡터는 embedding된 text에 해당되는 bounding box를 구성하는 각각의 픽셀로 transpose되며, 최종적으로는 W x H x D(W: 너비, H: 높이, D: embedding 차원)의 이미지를 생성하게 됨.
- 제안된 변형들은 다음과 같음.
- 1) CharGrid: one-hot encoding을 이용하여 characters를 이미지에 embedding시킴(Katti et al., 2018).
- 2) WordGrid: word2vec 또는 FastText를 이용하여 개별 word들을 embedding시킴(Kerroumi et al., 2020).
- 3) BERTgrid: BERT를 task에 특화된 문서에 fine-tunning시키고, 문맥적인 word-piece 벡터를 얻는데 사용됨(Denk and Reisswig, 2019)
- 4) C+BERTgrid: 문맥-특화(context-specific)와 character 벡터를 결합시킴(Denk and Reisswig, 2019).
- gird 기법들과 비교했을 때, C+BERTgrid는 OCR 오류에 대한 어느 정도의 탄성(resiliency)과 결합 되어진 문맥화된(contextualized) word 벡터로 인해 가장 우수한 성능을 보임.
- Zhao et al. (2019)은 text embedding을 이미지에 직접적으로 적용하는 대안적인 접근 방식을 제시함. 이미지 위에 grid가 투영되고 mapping 함수를 이용하여 각각의 token을 grid 내 고유한 cell에 할당시킴. 그 다음에 모델은 grid 내 각각의 cell을 class에 할당하는 방법을 학습시킴. 이 방법은 grid 시스템으로 인해 차원을 크게 줄이면서도 대부분 2D의 공간적인 관계를 유지시킴.
5.3 Documents as Graphs
문서 상의 구조화되지 않은 text는 graph network로 나타낼 수 있으며, 여기서 graph의 노드는 서로 다른 text segment를 나타내게 됨. 만약 2개의 노드가 서로 cardinally adjacent 하다면 하나의 에지로 연결되어 word 간의 관계를 직접적으로 모델링 할 수 있음(Qian et al., 2019).
- BiLSTM과 같은 encoder는 text segment를 노드로 encoding함(Qian et al., 2019).
- 에지는 binary adjacency matrix 또는 보다 풍부한(richer) matrix로 표현될 수 있으며, segment 간의 거리 또는 소스 및 타겟 노드의 모양(shape)과 같은 추가적인 시각적 정보를 encoding함(Liu et al., 2019a).
- 그 다음에 graph convolutional network를 dilated convolutions(Yu and Koltun, 2015)과 유사한 방식으로 서로 다른 receptive fields에 적용하여 local 및 global 정보를 모두 학습시킬 수 있도록 함(Qian et al., 2019).
- 이후에는, representation이 sequence를 tagging하는 decoder로 전달되며, 문서는 방향성 그래프(directed graph)와 공간 의존성(spatial dependency) parser로 표현될 수 있음(Hwang et al., 2020).
이러한 표현상에서, 노드는 textual segments로 표시되지만, 노드의 유형을 나타내는 필드 노드는 각각의 DAG를 초기화하는데 사용됨. 추가로, 2개의 에지가 정의됨.
- 1. 동일한 카테고리에 속하는 segment를 함께 그룹화하는 에지(STORENAME-> Peet 's-> Coffee, 필드 노드 뒤에 매장 이름을 나타내는 두 개의 노드).
- 2. 서로 다른 그룹 간의 관계를 연결하는 에지(Peet’s-> 94107, 우편 번호).
추가적인 2D positional embedding을 이용한 transformer는 text를 공간적으로 encoding하는데 사용됨. 이 후 task는 각각의 edge 유형에 대해 relationship matrix를 예측하는 것이 되며, 이 방법은 임의로 deep한 계층을 표현할 수 있으며, 복잡한 문서 레이아웃에 적용이 가능함.
5.4 Tables
표 형식의 데이터 추출은 다양한 양식과 복잡한 계층 구조로 인해서, 정보 추출 시 어려운 측면이 있음. 표 데이터셋은 일반적으로 수행해야 할 여러가지 task들이 있음(Shahab et al., 2010; Göbel et al., 2013; Gao et al., 2019; Zhong et al., 2019a).
- 1) 첫번째 task는 문서 내 표들을 포함하는 bounding box의 위치를 찾는 표를 검출(table detection)하는 것임.
- 2) 다음 task는 행, 열, 셀 정보를 공통된 형식으로 추출하는 표 구조를 인식하는 것임. 이는 표 인식으로 한단계 더 나아가 표 자체 내에서 셀을 분류하여, 구조적인 정보뿐만 아니라 내용을 모두 이해해야 함(Zhong et al., 2019a).
표를 적절하게 추출하고 이해하기 위해서는 text적인 특징과 시각적인 특징 모두 동등하게 중요하므로, 이러한 task를 수행하기 위한 다양한 방법들이 제안되었음.
- (Dong et al., 2019a)은 table detection과 구조 인식(structure recognition)을 동시에 수행하는 접근인 TableSense를 제안하였으며 3 단계의 접근을 사용함: 1) 셀 특징화(cell featurization), 2) convolutional model을 이용한 obejct detection, 3) 불확실성 기반의 active learning 샘플링 메커니즘.
- table detection을 위해 TableSense에서 제안한 아키텍처는 YOLO-v3나 Mask R-CNN((Redmon and Farhadi, 2018; He et al., 2017b)과 같은 전통적인 컴퓨터 비전 기법들 대비 훨씬 더 우수한 성능을 보여줌.
- 이러한 접근은 스프레드시트에서는 잘 동작하지 않기 때문에, Dong et al. (2019b)은 이전 연구를 확장하여, table 영역, 스프레드시트의 구조적 구성 요소, 셀 타입 등을 동시에 함께 학습하기 위한 multitask의 프레임워크를 제안함.
- 복잡한 table을 단일의 표준 양식으로 편평하게(flatten) 하기 위해 언어 모델을 사용하여 table cell의 의미적인 내용을 학습하는 부가적인 단계를 추가함.
- Wang et al. (2020)은 구조가 결정된 후 table 내 포함된 내용을 이해하는데 초점을 둔 TUTA를 제안함. tree 기반의 transformer를 사용하여 table 이해를 위한 언어 모델 pretraining에 대해 3가지의 새로운 목표를 제시함.
- pretraining에 도입된 목표는 모델이 token, cell, table level에서 table을 이해하는데 도움이 되도록 고안되었음.
- 모델이 예측해야 할 table cell에 따라 token의 비율을 masking하고, 모델의 위치를 기반으로 header string을 예측하기 위해 모델의 특정 cell header를 무작위로 masking하였으며, 어떤 문맥적 요소가 table과 긍정적으로 연관되었는지를 식별하기 위해 모델과 연관되거나 연관되지 않은 table 제목 또는 설명 등과 같은 문맥(context)을 table에 제공함.
- transformer 아키텍처는 cell의 다른 cell에 대한 계층적 거리에 기반한 항목(items)으로 attention 연결을 제한시킴으로써, attention으로부터의 교란(distractions)을 줄이도록 변경됨.
- fine-tuning TUTA는 세포 유형 분류를 위한 다중 데이터셋에 대해 최신의 성능을 보여줌.
6 Conclusion
- 문서 이해는 업계에서 hot한 주제이며, 엄청난 금전적 가치를 가지고 있음. 대부분의 문서는 개인 계약, 송장, 기록 등과 같은 사적인 데이터임. 따라서, 공개적으로 사용 가능한 데이터셋은 구하기 어렵고 다른 응용 분야와 관련하여 학계는 초점을 두고 있지 않음.
- 문서 이해를 다루기 위한 방법론에 대한 학술적 문헌들은 이미지 분류 및 번역과 같이 공개적으로 사용 가능한 데이터가 풍부한 영역에 비해서 유사하게 드문편임. 하지만, 문서 이해를 위한 가장 효과적인 접근 방식은 deep neural network 모델링의 최근 발전을 활용하는 것임.
- end-to-end 문서 이해는 레이아웃 분석, 광학 문자 인식, 도메인 특화 정보 추출 등을 수행하는 통합된 시스템을 만듦으로써, 달성 가능함.
- 본 논문에서는 문서 이해를 연구하고자 하는 학자와 실무자 모두에게 도약점이 되기 위해 문헌에 존재하는 방법론을 통합하고 구성하려 시도하였음.
'Computer Vision > Optical Character Recognition' 카테고리의 다른 글
| [논문 읽기/2020] Text Detection and Recognition in the Wild: A Review (1) | 2021.05.03 |
|---|
