link: arxiv.org/pdf/2006.04305.pdf
Abstract
- 자연 이미지에서 text를 detection하고 recognition 하는 것은 스포츠 비디오, 자율 주행, 산업 자동화 등의 다양한 분석에 적용되는 컴퓨터 비전 분야의 2가지 주요한 문제임.
- 이들은 여러 환경 조건에 따라 text가 어떻게 표현되고 영향을 받는지에 대한 요인인 일반적이면서도 어려운 문제에 직면을 함.
- 현재 최신의 scene detection과 recognition 기법들은 딥러닝 아키텍처의 관찰된 발전을 활용하였으며, 여러 해상도와 여러 방향성이 있는 text를 다룸에 있어서 벤치마크 데이터셋 상에서 우수한 성능을 보이는 것으로 보고가 됨.
- 하지만, 모델이 보이지 않는 데이터로 일반화 할 수 없으며, labeled된 data가 불충분하기 때문에, 자연 환경(wild) 이미지 내 text에 영향을 주는 몇가지 문제들이 여전히 남아 있음.
- 따라서 이 분야의 예전 조사 논문들과는 달리 본 논문에서는 다음과 같은 요소들을 목적으로 두고 있음.
- 1) scene detection 및 recognition과 관련된 최근 발전에 대한 리뷰를 제공할뿐만 아니라, 도전적인 케이스에 대해 선택된 방법들을 이용하여 pre-trained된 모델을 평가하고, 동일한 평가 기준을 적용하여 광범위한 실험을 수행한 결과를 나타냄.
- 2) 자연 환경 이미지 내 text를 detection하고 recognition함에 있어서, 몇몇의 존재하는 도전적 요소들에 대해서 확인을 함: in-plane 회전, 여러 방향과 해상도를 가진 text, 원근 왜곡, 조명 반사, 부분적 가려짐, 복잡한 폰트, 특수 문자 등
- 3) scene detection 및 recognition 시 여전히 겪게 되는 위의 도전적 요소들을 다루기 위해 이 분야의 향 후 잠재적인 연구 방향에 대한 통찰을 제시함.
1 Introduction
text는 의사소통에 필수적인 도구이며, 우리의 삶에 있어서 중요한 역할을 하고, 정보 전달 수단으로써 문서나 scene에 내장될 수 있음[1-3].
- text 식별은 다양한 컴퓨터 비전 기반 응용 분야의 주요한 building block으로 고려될 수 있음: 로보틱스[4, 5], 산업 자동화[6], 이미지 탐색[7, 8], 즉시 번역[9, 10], 자동차 보조 시스템[11], 비디오 스포츠 분석[12] 등
text 식별 영역은 크게 2가지 주요 카테고리로 분류됨.
- 1) 스캔된 인쇄 문서 내 text를 식별하는 것.
- 2) 일상 scene에서 캡처된 text를 식별하는 것.
- 예: 도시, 시골, 고속도로, 실내 및 실외에서 캡처된 보다 복잡한 모양의 text가 포함된 이미지로서 다양한 기하학적 왜곡, 조명 및 환경적인 조건들에 의해 영향을 받음.
- scene text 또는 text in the wild라고 칭함.
그림 1은 이러한 2가지 유형의 text 이미지들을 나타내고 있음. 스캔된 인쇄 문서 내 text를 식별하는 Optical Character Recognition (OCR)은 널리 사용되고 있으며[1, 13-15], 만족스러운 해상도를 가진 인쇄 문서를 읽음에 있어 우수한 성능을 보임; 하지만 이러한 전통적인 OCR 기법들은 자연 환경에서 캡처된 text를 검출하고 인식할 때 많은 복잡한 도전 요소에 직면하게 되며, 대부분의 경우에 있어서 실패를 하게 됨[1, 2, 16].

자연 환경에서 캡처된 이미지 내 text를 검출하고 인식함에 있어서 도전 요소들은 아래와 같이 분류할 수 있음.
- - text의 다양성: text는 색상, 폰트, 방향, 언어 등이 다양하게 존재함.
- - scene의 복잡성: 기호(signs), 벽돌, 심볼 등과 같이 text와 유사한 외관을 갖는 scene의 요소들이 있음.
- - 왜곡적 요인들: 모션 블러, 불충분한 카메라 해상도, 캡처 각도, 부분적인 가려짐[1-3] 등과 같은 여러 요인으로 인해 왜곡된 이미지에 대한 영향을 받음.
scene text detection 및 recognition의 도전 요소들을 다루기 위해 관련 문헌들에서는 다양한 기법들이 제안되었으며 2가지로 분류가 됨.
- 1) 고전적인 기계 학습 기반 접근[17-29]
- scene 이미지 내 text를 검출하거나 인식할 때 특징 추출 기법과 기계 학습 모델을 결합하는 것에 기반하고 있음[20, 57, 58].
- 비록 이러한 기법들이[57, 58] 수평 방향의 text를 검출하거나 인식하는데 우수한 성능을 보였지만[1, 3], 여러 방향성이 있거나 곡선 형태의 text를 가진 이미지를 처리할 때는 실패를 하게 됨[2, 3].
- 2) 딥러닝 기반 접근[30-56]
- 다양한 상황에서 캡처된 text에 대해 딥러닝 기반 접근은 text detection[33–40, 42, 43, 46, 47, 50, 59], text recognition[32, 52–56, 60–71], end-to-end 방식의 text detection 및 recognition[48–51]에서 효율성을 보임.
scene text detection 및 recognition과 관련된 초기의 조사 연구들[1, 72]은 딥러닝 시대 이전에 도입된 고전적인 기법들에 대해서 포괄적인 리뷰를 수행함. 반면, 보다 최근의 조사 연구들[2, 3, 73]은 딥러닝 시대의 scene text detection 및 recognition에서 발생한 발전에 더욱 초점을 두고 있음.
- 비록 이러한 2개의 그룹들이 고전적인 기법 및 딥러닝 기반 기법 모두에 있어서 만들어진 진보를 커버하고 있지만, 최근의 목격된 논문들에 대한 요약 및 결과를 보고하는데만 집중을 하고 있음.
기여
- 본 논문에서는 딥러닝 기반 기법들에 초점을 둔 scene text detection 및 recognition 관련 최근 발전에 대해서 리뷰할뿐만 아니라, 도전적인 벤치마크 데이터셋 상에서 최신의 기법들의 성능 평가를 위해 동일한 평가 방법론을 사용함으로써 관련 문헌들 사이에 존재하는 공백을 매꾸고자 함.
- 또한, 광범위한 실험을 수행한 후 결과 분석 및 토론을 통해서 기존 기법들의 단점에 대해서 연구를 하였음.
- 마지막으로 불리한 상황에서 scene text detection 및 recognition을 처리할 수 있는 더 나은 모델을 설계하도록 잠재적인 향 후 연구 방향 및 우수한 사례를 제안함.
2 Literature Review
과거 10년 동안, 연구자들은 자연 환경에서 캡처된 이미지 내 text를 읽기 위한 많은 기법들을 제안하였음[32, 36, 53, 58, 77].
- 이러한 기법들은 먼저 모든 가능한 text 영역에 대해 bounding boxes를 예측함으로써, 이미지 내 text의 영역을 찾은 후 모든 검출된 영역의 내용을 인식하게 됨.
- 따라서 이미지로부터 text를 해석하는 처리는 text dection 및 text recognition 등의 이후 2가지 task로 나뉘게 됨.
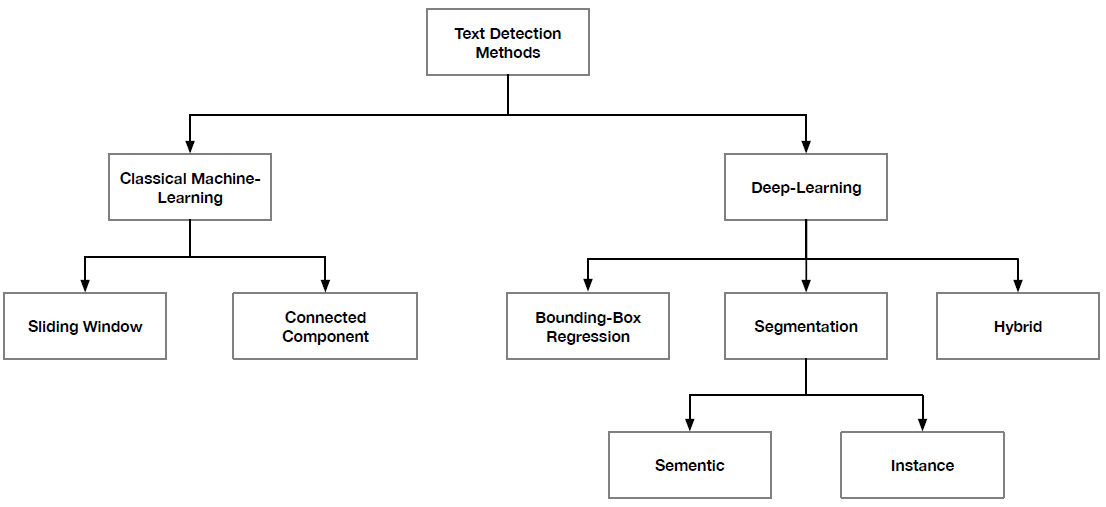
- 1) 그림 3에서 볼 수 있듯이 text detection은 이미지에서 text 영역을 검출하거나 위치를 찾는 것을 목적으로 함.
- 2) text recognition은 검출된 text 영역을 컴퓨터가 읽을 수 있고 편집 가능한 characters, words, text-line 등으로 변환하는 처리에만 초첨을 두고 있음.

이번 장에서는 text detection 및 text recognition을 위한 고전적인 알고리즘 및 최근의 알고리즘들에 대해 논의를 할 예정임.
2.1 Text Detection
그림 2에서 볼 수 있듯이, scene text detection 기법들은 고전적인 기계 학습 기반 접근[18, 20–22, 30, 58, 78–83] 및 딥러닝 기반 접근[33–40, 42, 43, 47, 50, 59]으로 나뉠 수 있으며 이번 장에서는 이러한 각각의 카테고리와 관련된 기법들 에 대해 리뷰를 할 예정임.
2.1.1 Classical Machine Learning-based Methods
이번 장에서는 scene text detection을 위한 전통적인 기법들에 대해서 요약을 하였으며, 이는 크게 슬라이딩 윈도우(sliding-window) 및 연결 성분(connected-component) 기반 접근의 2가지로 분류를 할 수 있음.
- 1) 슬라이딩 윈도우 기반 접근[17-22]
- 주어진 테스트 이미지는 특정한 크기의 슬라이딩 윈도우를 사용하여 가능한 모든 text의 위치와 스케일에 대해 스캔될 수 있도록 이미지 피라미드를 구축하는데 사용됨.
- 그 다음에 특정한 유형의 이미지 특징들(예: 평균 차(difference) 및 표준 편차[19], histogram of oriented gradients(HOG) [85]를 사용한 [20, 86, 87], 에지 영역[21])을 각각의 윈도우로부터 취득한 후 각각의 윈도우 내 text를 검출하기 위해 고전적인 분류기(random ferns [88]를 사용한 [20], decision trees [21], log-likelihood [18], likelihood ratio test [19] 등의 다중 약 분류기(multiple weak classifiers)를 이용한 adaptive boosting (AdaBoost) [89])를 이용하여 분류를 수행함.
- 예를 들어, Chen and Yuille [18]의 초기 연구에서는 intensity histograms, intensity gradients, gradient directions 등의 특징들을 테스트 이미지 내 각각의 슬라이딩 윈도우 위치에서 취득한 후 동일한 유형의 특징들을 사용하여 표현된 text에 대해 훈련된 몇개의 weak log-likelihood classifiers를 text 검출을 위해 AdaBoost 프레임워크를 사용한 strong classifier를 구축하는데 사용함.
- [20]에서는 HOG 특징들을 모든 슬라이딩 윈도우 위치에 대해 추출하고 Random Fern classifiers[90]를 다중 스케일의 character 검출을 위해 사용하였으며, 각각의 character를 분리하여 검출하기 위해 non-maximal suppression (NMS)[91]을 적용함.
- 하지만, 이러한 방법들[18, 20, 21]은 단지 수평 방향의 text를 검출하는데 적용이 가능하며, 임의의 text 방향을 가진 scene 이미지에 대해서는 낮은 검출 성능을 보임[92].
- 2) 연결 성분 기반 접근
- 전통적인 classifier(support vector machine (SVM) [78], Random Forest [82], nearest-neighbor [99] 등)를 이용하여 text 또는 non-text 클래스로 분류되어야 할 후보 성분들을 생성하기 위해 유사한 속성(color [23–27], texture[93], boundary [94–97], corner points [98] 등)을 가진 이미지 영역을 추출하는 것을 목표로 함.
- 이러한 기법들은 주어진 이미지에 대해 character를 검출한 후 추출된 character를 word[58, 78, 79] 또는 text-line[100]으로 결합시킴.
- 슬라이딩 윈도우 기반 기법들과 달리, 연결 성분 기반 기법들은 보다 효율적이고 강건하며, scene text detection에서 중요한 false positive rate를 낮게 제공함[73].
- Maximally stable extremal regions (MSER) [57] 및 stroke width transform (SWT) [58]은 2개의 주요한 대표적 연결 성분 기반 기법들로서 많은 후속의 text detection 연구들[30, 72, 78, 79, 82, 83, 97, 100–102]에 기초를 제공함.
- 한계점
- 위에서 언급된 고전적인 기법들은 모호한 character가 있는 영역을 쉽게 버리거나 검출 성능을 떨어뜨리는 다수의 오검출을 만드는 개별 character 또는 성분들을 검출하는 것을 목적으로 하고 있음[103].
- 게다가, 추 후 단계에 대해 쉽게 전이되는 에러를 야기시킬 수 있는 여러개의 복잡한 순차적 단계들을 필요로 함.
- 균일하지 못한 조명, 여러개의 연결된 character들을 가진 text 등이 있는 환경에서의 text 검출과 같이 어려운 상황에서는 검출에 실패를 하게 됨.
2.1.2 Deep Learning-based Methods
딥러닝[120]의 출현은 연구자들이 text 검출에 대해 접근하는 방식의 변화를 가져왔고 이 분야의 연구 범위를 훨씬 더 확대시킴.
- 딥러닝 기반의 기법들은 고전적인 기계 학습 기반 기법들 대비 많은 이점들(예: 빠르고 단순한 파이프라인[121], 다양한 종횡비를 갖는 text 검출[59], 합성 데이터에 대해 더 나은 훈련을 제공할 수 있는 능력[32])이 있기 때문에, 널리 사용되고 있음[38, 39, 106].
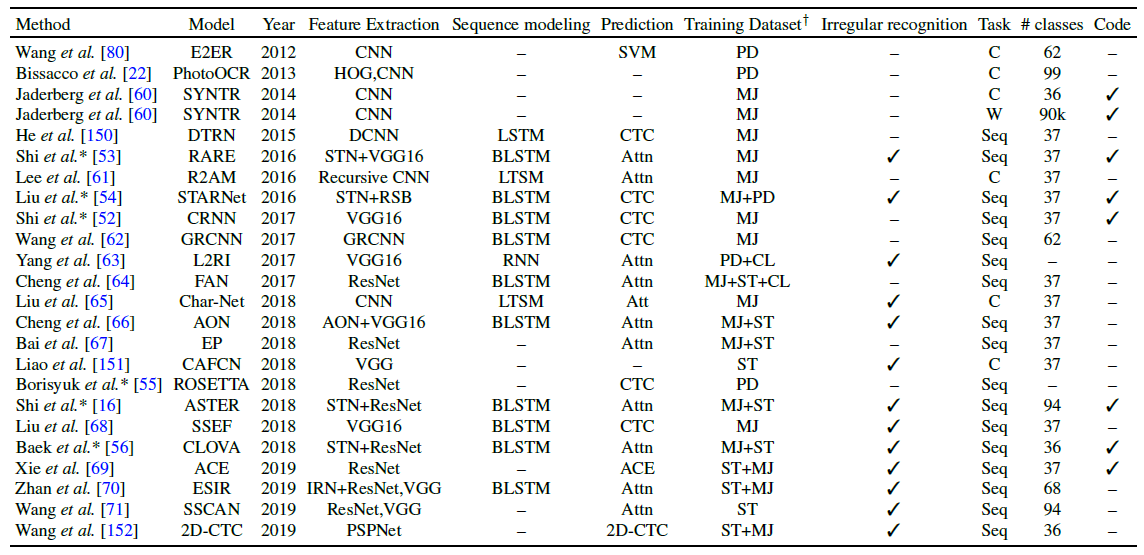
- 이번장에서는 딥러닝 기반의 text detection 기법들의 최근 발전에 대한 리뷰를 나타냈으며, 표 1에서는 현재 이 분야에서 사용되는 최신 기법들에 대한 비교를 요약하였음.


- 1) 초기의 딥러닝 기반 text detetection 기법들[30-33]
- 보통 여러 단계로 구성되어 있음.
- 예를 들어, Jaderberg et al. [33]는 text saliency map을 생성하기 위한 감독 학습 모델을 훈련사키기 위해 convolutional neural network (CNN)의 아키텍처를 확장한 후 필터링 및 NMS를 수행하여 여러 스케일에 대한 bounding boxes를 결합시킴.
- Huang et al. [30]은 최종적인 text detector의 precision을 향상시키기 위해, 고전적인 연결 성분 기반 접근과 딥러닝 기반 접근을 함께 사용함. 이 기법에서는 character 후보를 찾기 위해 높은 명암대비(contrast)를 갖는 region을 검출하는 detector인 MSER [57]을 입력 이미지에 적용한 후 이후에 최종적인 검출 결과를 얻는데 사용되는 confidence map을 생성함으로써, CNN 분류기는 non-text 후보를 필터링 하는데 사용되어짐.
- 이 후 [32]에서는 aggregate channel feature (ACF) detector[122]를 이용하여 text 후보를 생성하고 false-positive한 후보를 줄이는데 bounding box regression을 위한 CNN을 활용함.
- 한계점
- 이러한 초기의 딥러닝 기반 기법들[30, 31, 33]은 주로 character를 검출하는데 목적을 두고 있었기 때문에 복잡한 배경에 character들이 나타난 경우에는 하락된 성능을 보임(예: 배경의 요소들이 character의 외관과 유사한 경우 또는 character가 기하학적 변화(variations)에 영향을 받은 경우[39]).
- 2) 최근의 딥러닝 기반 text detection 기법들[34–38, 50, 59]
- object detection 파이프라인[114, 117, 118, 123, 124]에서 영감을 받았으며, 그림 2에서 볼 수 있듯이 bounding box regression 기반 접근, segmentation 기반 접근, hybrid 접근 등으로 크게 나눌 수 있음.
- 2-1) bounding box regression 기반 기법들[33-38]
- text를 object로 간주하고, 후보 bounding boxes를 직접적으로 예측하는 것을 목표로 함.
- 예를 들어, [36]의 TextBoxes는 종횡비의 상당한 변동을 처리하기 위해 길이가 긴 default anchors와 filter를 적용하여 single-shot descriptor (SSD) [118] 커널을 수정함.
- [59]에서 Shi et al는 공간적인 관계(spatial relationships)를 사용하거나 이웃하는 text segments들 사이의 예측 (predictions)을 연결함으로써 text를 보다 작은 segments로 분해하고 이들을 SegLink라 불리는 text instance로 연결하여 SSD[118]로부터 상속받은 아키텍처를 활용함. 이를 통해 SegLink는 큰 종횡비를 갖는 라틴어 및 비 라틴어 text로 이루어진 길이가 긴 line을 검출할 수 있게 됨.
- Connectionist Text Proposal Network (CTPN) [34]는 Faster-RCNN[117]의 수정된 버전으로써, 각각의 고정된 너비(fixed-width)를 갖는 proposal의 위치와 score를 동시에 예측하기 위해 anchor 메커니즘을 사용한 후 순차적인(sequential) proposal들을 recurrent neural network (RNN)로 연결시킴.
- Gupta et al. [125]는 YOLO network[123]에서 영감을 받은 fully convolutional regression network를 제안하였으며, 이미지 내 false-positive한 text를 줄이기 위해 random-forest classifier도 같이 활용함.
- 한계점
- 일반적인 object detection에서 영감을 받은 이러한 방법들[34, 36, 125]은 여러 방향성을 갖는 text를 처리하는데 실패 할 수 있으며, 방향성이 있는 text box를 만들기 위해 text components들을 text lines들로 그룹화하는데 더 많은 단계를 필요로 함.
- 이는 일반적인 object detection 문제와는 다르기 때문에, word 또는 text 영역을 검출하는 것은 더 큰 종횡비의 bounding boxes가 요구됨.
- scene text가 일반적으로 임의의 모양으로 나타난다는 것을 고려해봤을 때, 몇몇 연구들은 여러 방향성을 가진 text를 검출할 때 성능을 향상시키기 위한 시도들을 함[35, 37, 38, 59, 106].
- He et al. [106]는 text 영역의 모든 point들과 꼭지점(vertex) 좌표 사이의 오프셋을 계산하여 임의의 사각형(quadrilaterals) text를 생성하기 위해 direct regression 기반의 여러 방향성을 갖는 text detection을 제안함. 이 기법은 구성된 characters들을 식별하기 어렵고 스케일 및 원근 왜곡이 상당한 변화를 갖는 scene text의 사각형 경계 위치를 찾는데 특히 유용함.
- EAST[35]에서는, text 영역 검출을 위해 후보 모음(aggregation) 및 word 분할(partition) 단계의 사용 없이 FCN을 직접적으로 적용한 후 word 또는 line text를 검출하기 위해 NMS를 적용함. 이 기법은 text 영역 내 모든 point에 대해 회전된 boxes 또는 사각형 words 또는 text-lines을 예측함.
- Ma et al. [38]는 scene 이미지 내 임의의 방향을 가진 text를 검출하기 위해 Faster-RCNN[117] 기반의 Rotation Region Proposal Networks (RRPN)를 도입함.
- 이후, Liao et al. [37]는 network 구조와 훈련 process를 개선시켜 TextBoxes를 확장한 TextBoxes++을 제안하였으며, 임의의 방향을 가진 text를 검출하기 위해 text의 직사각형 bounding boxes를 사각형으로 대체시킴.
- 한계점
- bounding box 기반의 기법들[34, 35, 37, 38, 59, 106]은 단순한 아키텍처를 가지고 있지만, 복잡한 anchor 설계가 필요하고 훈련 중에 tunning이 어려우며 곡선이 있는 text를 검출하는데 실패할 수 있음.
- 2-2) segmentation 기반 기법들[39-45, 47]
- 2-2-1) semantic segmentation 기반
- text detection을 그림 4의 (a)와 같이 semantic segmentation 문제로 바라보며, 이미지 내 text 영역을 pixel level로 분류하는 것을 목표로 함.
- 이러한 기법들은 먼저 FCN[114]에 의해 생성된 segmentation map으로부터 text blocks들을 추출하고 후처리로 text의 bounding boxes들을 얻음.
- 예를 들어, Zhang et al. [39]은 text region의 salient map에 대한 예측 및 주어진 이미지 내 각각의 character들의 중심 예측을 위해 FCN을 채택함.
- Yao et al. [40]는 text/non-text 영역, character 클래스, 입력 이미지의 character 연결 방향 등의 3가지 종류의 score map을 만들기 위해 FCN을 변경함. 그 다음, segmentation map을 가진 word bounding boxes를 얻기 위해 word 분할 후처리 기법을 적용함.
- 한계점
- segmentation 기반 기법들[39, 40]이 회전되고 불규칙한 text에 대해 잘 동작하긴 하지만, 연결되는 경향이 있는 인접한 word instance들을 정확하게 분리하는데는 실패할 수도 있음.
- 연결된 이웃 characters들의 문제를 다루기 위한 접근들
- Pixellinks [43]는 text margin을 강조하여 각 pixel에 대한 8 방향성의 정보를 활용함.
- Lyu [44]는 positive-sensitive score map을 생성하기 위한 corner 검출 기법을 제안함.
- [42]에서는 text 영역 및 기하학적 속성을 함께 가진 center-line을 예측함으로써, text instance 검출을 위한 TextSnake를 제안함. 이 기법은 character level의 annotation이 필요 없으며, text instance의 정확한 모양과 영역적인 strike를 재구성 할 수 있음.
- [105]에서 영감을 받아, [46]에서는 character affinity map을 사용하여 검출된 characters들을 하나의 word로 연결시킨 후 weakly한 supervised 프레임워크를 character level의 detector를 훈련시키는데 사용함.
- 인접한 text instance를 더 잘 검출하기 위해, [113]에서는 여러 스케일을 가진 kernel과 서로 가까운 개별 text instance를 정확하게 찾기 위한 progressive scale expansion network (PSENet)를 도입함.
- 하지만 [46, 113]의 방법들은 훈련을 위해 많은 수의 이미지들이 필요하므로 run-time이 증가하고 리소스가 제한된 플랫폼에서는 어려움을 나타낼 수 있음.
- 2-2-2) instance segmentation 기반
- [47, 48, 127, 128]에서는 그림 4의 (b)와 같이, scene text detection을 instance segmentation 문제로 취급하였으며, 이들 중 다수는 scene text detection의 성능 개선을 위해 Mask R-CNN[124] 프레임워크를 적용하였고 이는 임의의 모양을 갖는 text instance를 검출하는데 유용함.
- 예를 들어, Mask R-CNN에 영감을 얻어, SPCNET [128]은 임의의 모양을 갖는 text를 검출하기 위해 text context 모듈을 사용하고 re-score 메커니즘을 사용하여 false positive한 검출을 supression시킴.
- 한계점
- [48, 127, 128]의 방법들은 아래의 경우에 대해 성능 저하가 발생할 수 있음.
- 첫째, 예측된 bounding box가 전체 text 이미지를 덮지 못하는 복잡한 배경에서 bounding box 처리의 error로 어려움을 겪을 수 있음.
- 둘째, text 경계에서 잘못 labeled된 많은 pixels들을 야기할 수 있는 배경 pixel로부터 text pixel을 분리하는 것을 목표로 함[47].
- 2-2-1) semantic segmentation 기반
- 2-3) Hybrid 기법들[103, 108, 109, 129]
- text의 score map을 예측하기 위해 segmentation 기반 접근을 사용하며, 동시에 regression을 통해 text의boundig boxes를 얻는 것을 목표로 함.
- 예를 들어, single-shot text detector (SSTD) [103]는 이미지 내 text 영역을 향상시키고 feature level에서 배경에 대한 간섭(interference)을 줄이기 위해 attention 메커니즘을 사용함.
- Liao는 [108]에서 방향성이 있는 scene text detection을 위해 convolutional filters를 능동적으로 회전시킴으로써 회전에 불변하는 features들을 최대한 활용하는 rotation-sensitive regression을 제안함.
- 하지만 이 방법은 scene images 내 존재하는 다른 모든 가능한 text 모양을 capture할 수 없음[46].
- Lyu는 [109]에서 text boxes 생성을 위해 text region의 corner points를 검출하고 그룹화하는 방법을 제안함.
- 이 방법은 긴 방향을 가진 text를 검출하고 상당한 종횡비의 변화를 다루는 것 외에도 단순한 후처리를 필요로 함.
- Liu는 [47]에서 text instance의 각 픽셀에 대해 0~1 사이의 범위를 갖는 soft pyramid level을 할당하고 획득한 2D soft mask를 3D 공간으로 재해석하는 pyramid mask text detector (PMTD)라 불리는 새로운 Mask RCNN 기반의 프레임워크를 제안함.
- 그 다음에 soft pyramid에 새로운 plane clustering 알고리즘을 사용하여 이 기법이 여러 최근 데이터셋들[75, 130, 131]에 대해 최신의 성능을 달성하는데 도움이 되도록 최적의 text box를 추론함.
- 하지만 PMTD 프레임워크는 여러 방향성을 갖는 text를 처리하기 위해 명시적으로 설계 되었기 때문에 곡선을 갖는 text 데이터셋[76, 132]에 대해서는 여전히 낮은 성능을 보임.

2.2 Text Recognition
scene text recognition task는 검출된 text 영역을 characters 또는 words로 변환하는 것을 목적으로 함.
- 대소문자를 구분하는 character classes는 보통 10자리의 숫자, 26개의 소문자, 26개의 대문자, 32개의 ASCII 문장 부호 및 문장의 끝 기호로 구성됨. 하지만 문헌에서 제안된 text recognition 모델들은 서로 다른 character classes들을 선택하여 사용하고 있으며, 이들에 대한 갯수는 표 3에 나와 있음.
- scene text image의 속성은 스캔된 문서의 속성과는 다르기 때문에, [133-138]과 같은 고전적인 OCR이나 필기체 인식 기법에 기반한 효율적인 text recognition 기법을 개발하는 것은 어려움. 1장에서 언급했듯이, 자연 환경에서 캡처된 이미지는 아래의 다양한 도전적인 상황들의 text를 포함하는 경향이 있음.
- 저해상도[77, 139], 심한 빛(lightning extreme)[77, 139], 환경적인 조건들[75, 126], 다른 폰트 수[75, 126, 140], 방향 각도[76, 140], 언어[131], 어휘(lexicons) [77, 139]
연구자들은 이러한 도전적인 문제들을 다루기 위해 서로 다른 기법들을 제안하였으며, 이는 크게 고전적인 기계 학습 기반[20, 28, 29, 77, 96, 135] 및 딥러닝 기반[32, 52–55, 55, 60–71]의 text recognition 기법들로 분류가 되며 본 장에서는 이들에 대해서 이야기 할 예정임.
2.2.1 Classical Machine Learning-based Methods
과거 20년동안 전통적인 scene text recognition 기법들[28, 29, 135]은 HOG[85]와 SIFT[141]과 같은 일반적인 image features를 SVM[142]나 k-nearest neighbors[143]와 같은 전통적인 기계 학습 분류기를 이용하여 학습시킨 후 잘못 분류된 characters들을 제거하기 위해 통계적 언어 모델(statistical language model) 또는 시각적 구조 예측(visual structure prediction)을 적용함[1, 92].
- bottm-up 접근: 대부분의 고전적인 기계 학습 기반 기법들은 분류된 characters들을 word로 연결시키는 bottom-up 접근을 따름.
- 예를 들어, [20, 77]에서는 각각의 sliding window로부터 HOG features를 추출하고 입력 word image의 characters들을 분류하기 위해 미리 학습된 nearest neighbor 또는 SVM 분류기를 적용함.
- Neumann과 Matas [96]는 text recognition을 위해 SVM 분류기와 함께 종횡비 및 hole 면적 비율을 포함하는 handcrafted feature set을 제안함. 하지만 이러한 방법[20, 22, 77, 96]은 handcrafted feature의 낮은 표현 능력이나 자연 환경 내 text를 처리할 수 없는 모델 구축으로 인해 효과적인 인식 정확도를 달성할 수 없음.
- top-down 접근: 다른 연구들은 개별적인 characters들을 검출하여 인식하기 보단 전체 입력 이미지로부터 직접적으로 word를 인식하는 top-down 접근을 채택함.
- 예를 들어, Almazan et al. [144]는 word 인식을 내용 기반 이미지 검색(content-based image retrieval) 문제로 취급하였으며, word 이미지 및 word label들을 유클리디안 공간으로 embedding한 후 embedding vectors들은 이미지 및 label들을 matching 하는데 사용함.
- 이러한 방법[144–146]을 사용할 때 야기되는 주요 문제점 중 하나는 word 사전 데이터셋 외부에 있는 입력 word 이미지를 인식하지 못한다는 것임.
2.2.2 Deep Learning-based Methods
deep neural network 아키텍처[114, 147–149]의 최근 발전과 함께 많은 연구자들은 자연 환경 내 text 인식의 도전적 요소를 다루기 위해 딥러닝 기반의 기법들을 제안함[22, 60, 80]. 표 3은 최근의 최신 딥러닝 기반 text recognition 기법들[16, 52–55, 61–71, 150–152] 중에 일부를 나타내고 있음.

- 예를 들어, Wang et al. [80]은 character recognition을 위해 CNN 기반의 특징 추출 프레임워크를 제안하였으며, 최종적인 word 예측을 위해 [153]에서 사용한 NMS 기법을 적용함.
- Bissacco et al. [22]은 character feature representation을 위해 fully connected network (FCN)를 활용한 후 character 인식을 위해 n-gram 접근을 사용함.
- 유사하게 [60]에서는 새로운 합성 text 데이터셋에 대해 훈련된 multiple softmax classifiers를 이용하여 deep CNN 프레임워크를 고안하였으며, word 이미지 내 character들은 이러한 독리적인 분류기를 이용하여 예측함.
- 이러한 초기의 deep CNN 기반 character recognition 기법들[22, 60, 80]은 복잡한 배경, 관계가 없는 기호, scene text 이미지 내 인접한 character 사이의 짧은 거리 때문에 각 character를 localizing 하는데 어려움을 겪을 수 있음.
word recognition을 위해 Jaderberg et al. [32]는 CNN 아키텍처를 활용하여 90k의 영단어 분류 task를 수행함.
- 비록 이 방법이 단지 개별적으로 character recognition을 하는 기법들[22. 60, 80]보다 더 나은 word 인식 성능을 보여주긴 했지만, 2개의 결점이 존재함. (1) 이 방법은 vocabulary에 없는 word를 인식할 수 없으며, (2) 긴 길이를 갖는 word 이미지의 deformation은 인식률에 영향을 주게 됨.
scene text가 일반적으로 character들의 sequence 형태로 나타난다는 것을 고려해봤을 때, 많은 최근 연구들[52–54, 64, 66–71, 150]은 모든 입력 sequence들을 가변 길이를 갖는 출력 sequence로 매핑(mapping)시킴.
- 음성 인식 문제로부터 영감을 얻어, 몇몇의 sequence 기반 text recognition 기법들[52, 54, 55, 61, 62, 68, 150]은 character sequence들의 예측을 위해 connectionist temporal classification (CTC) [156]를 사용함.
- 그림 5는 문헌에서 사용된 3가지의 주요 CTC 기반 text recognition 프레임워크를 나타내고 있음.
- 그림 5의 (a)에서 볼 수 있듯이 첫번째 카테고리[55, 157]에서는 CNN 모델(VGG [147], RCNN [149], ResNet [148] 등)은 CTC와 함께 사용이 됨.
- 예를 들어, [157]에서는 효과적으로 문맥 정보(contextual information)를 캡처하기 위해 text-line 이미지에 먼저 sliding window를 적용한 후 출력 word를 예측하는데 CTC 예측을 사용함.
- Rosetta [55]는 ResNet 모델을 backbone으로 적용하여 convolutional neural network에서 추출된 특징만을 사용하여 feature sequences를 예측함. 계산 복잡성을 줄였음에도 불구하고, 이러한 방법[55. 157]은 문맥 정보가 부족하며 낮은 인식 정확도를 보임.

문맥 정보의 보다 나은 추출을 위해, 몇몇 연구들[52, 62, 150]은 CTC와 결합된 RNN[63]을 사용하여 예측된 sequence와 target sequence 사이의 조건부 확률을 식별함(그림 5의 (b)).
- 예를 들어, [52]에서는 입력 이미지의 특징 추출을 위해 VGG[158]을 backbone으로 사용하고 문맥 정보를 추출하기 위해 bidirectional long-short-term-memory (BLSTM) [159]을 적용한 후 characters의 sequences를 식별하기 위해 CTC loss를 적용함.
- 추후에, Wang et al. [62]은 이전 모델 RCNN의 recurrent connections을 조절하기(modulate) 위해 gate를 사용하는 recurrent convolutional neural network (RCNN), 즉 gated RCNN(GRCNN)에 기반한 새로운 아키텍처를 제안함.
- 하지만 그림 6의 (a)에서 설명한 것처럼 이러한 기법들[52, 62, 150]은 character가 2차원(2D) 이미지 평면에 배열되어 있고, CTC 기반 기법들은 단지 1차원(1D)의 sequence to sequence 정렬만을 위해 설계 되었기 때문에 불규칙한(irregular) text[69]를 인식하기에는 불충분함. 따라서, 이러한 기법들은 2D 이미지 features를 1D features로 변환해야 하며, 이는 관련된 정보의 손실을 초래할 수 있음[152].
불규칙한 입력 text 이미지를 처리하고자, Liu et al. [54]는 text 왜곡을 해결하기 위해 spatial transform network (STN) [154]를 활용한 spatial-attention residue Network (STAR-Net)를 제안함.
- [54]에서는 그림 5의 (c)에서 표시된 residue convolutional blocks, BLSTM, CTC 프레임워크 내에서 STN의 사용이 다양한 왜곡 상황에서 scene text recognition을 수행할 수 있음을 보여줌.
최근에 Wang et al. [152]은 1D-CTC 기반 기법들의 한계를 극복하고자 2D-CTC 기법을 도입하였으며, 이 방법은 보다 정확한 인식을 만들기 위해 2D 확률 분포에 직접적으로 적용될 수 있음.
- 이를 위해 그림 6의 (b)에서 볼 수 있듯이 time step 옆에, 탐색 공간을 보다 잘 정렬하고 관련 features들에 대한 초점을 맞추기 위해 height dimension에 대해 모든 가능한 path를 고려하도록 path 검색을 위한 여분의 height dimension을 또한 추가시킴.

[160]에서 기계 번역을 위해 먼저 사용된 attention mechanism은 scene text recognition을 위해 또한 채택되었으며[16, 53, 54, 61, 63, 65, 66, 70], 여기서 implicit attention은 decoding 처리에 있어 deep features를 향상시키기 위해 자동적으로 학습되어짐. 그림 7은 문헌들에서 사용된 5개의 주요 attention 기반 text recognition 프레임워크를 나타내고 있음.
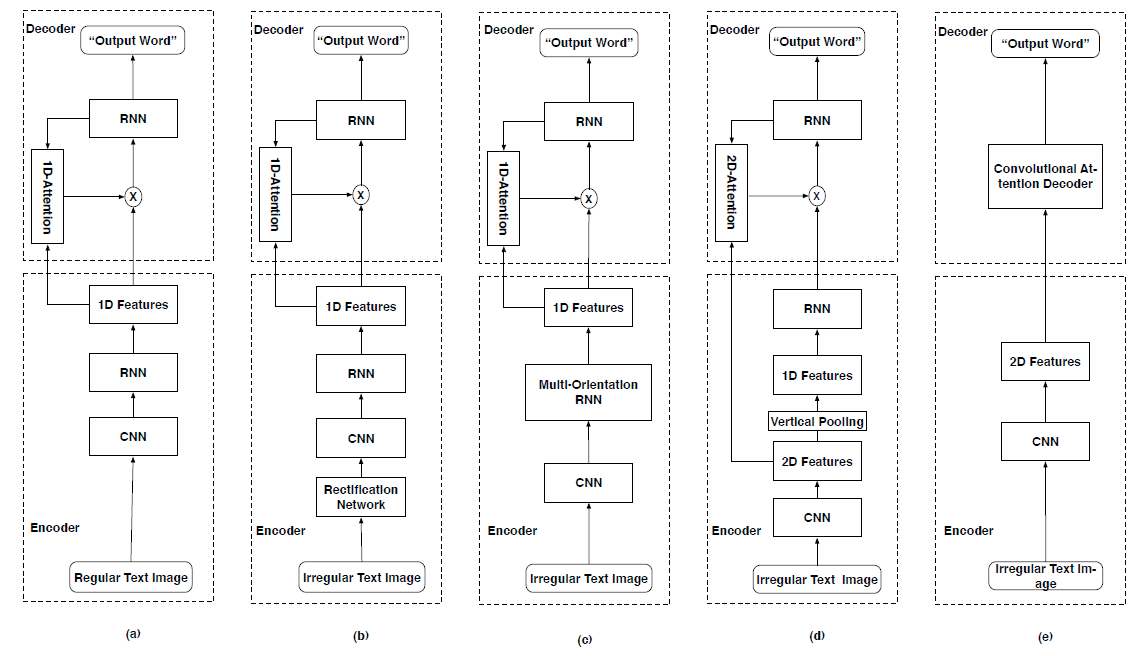
규칙적인(regular) text recognition을 위해, [61, 161, 162]에서는 그림 7의 (a)에서 볼 수 있듯이 기본적인 1D-attention 기반의 encoder 및 decoder 프레임워크가 text 이미지를 인식하는데 사용됨.
- 예를 들어, Lee와 Osindero [61]는 attention modeling을 이용한 recursive recurrent neural network(R2AM)을 제안하였으며, 여기서 보다 넓은 문맥 정보를 학습하기 위해 recursive CNN을 사용한 후 1D attention 기반 decoder를 sequence를 생성하는데 적용함.
- 하지만 불규칙한 text에 대해 R2AM을 직접 훈련시키는 것은 수평적인 character 배치로 인해서 어려움[163].
불규칙한 text를 다루는데 있어서 CTC 기반 인식 기법들과 유사하게 많은 attention 기반 기법들[16, 56, 65, 70, 166]은 그림 7의 (b)에서 볼 수 있듯이 왜곡된 text 이미지를 조정하기 위해 이미지 교정(rectification) 모듈을 사용함.
- 예를 들어, Shi et al. [16, 53]는 attention 기반 sequence와 STN 모듈을 결합하여 불규칙한 text(예: 곡선이거나 원근 왜곡)를 교정한 후 교정된 이미지 내 text를 RNN network로 인식하는 text 인식 시스템을 제안함.
- 하지만 인간이 설계한 기학적인 ground truth를 고려하지 않고 STN 기반 기법을 훈련시키는 것은 특히, 복잡한 임의의 방향을 갖거나 강한 곡선을 갖는 text 이미지에서는 어려움.
최근에 많은 기법들[65, 70, 166]은 불규칙한 text를 교정하기 위한 몇몇 기술들을 제안함.
- 예를 들어, 전체 word 이미지를 교정하는 대신에, Liu et al. [65]는 왜곡된 scene characters를 인식하기 위해 Character-Aware Neural Network (Char-Net)를 제안함. Char-Net은 word-level encoder, character-level encoder, LSTM 기반 decoder를 포함하고 있으며, STN과 다르게 단순한 local spatial transformer를 이용하여 개별 characters들을 검출하고 교정함.
- global STN에서는 쉽게 인식할 수 없던 보다 복잡한 형태의 왜곡된 text를 검출할 수 있지만, 이미지에 심하게 blur된 text가 포함된 경우 실패를 하게 됨.
- [70]에서는 반복적인 방법으로 원근 및 곡률(curvature) 왜곡을 바로잡기 위해 강건한 line-fitting transformation을 제안함. 이를 위해, thin plate spline (TPS) transformation을 이용한 반복적인 rectification network를 적용함으로써 곡선이 있는 이미지의 교정률을 높이고 인식 성능을 향상시킴.
- 하지만 이 방법의 가장 큰 단점은 여러 교정 단계로 인해서 계산 비용이 높다는 것임.
- Luo et al. [166]는 불규칙한 text 이미지 교정을 위한 새로운 multi-object rectified attention network (MORAN)와 decoder 내 attention 기반 network의 sensitivity 향상을 위한 fractional pickup 메커니즘 등의 text 인식 성능 향상을 위한 2개의 메커니즘을 제안함.
- 하지만 이 방법은 곡선의 각도가 너무 큰 복잡한 배경에서는 실패를 하게 됨.
방향성을 갖는 text 이미지를 처리하기 위해 Cheng et al. [66]은 4개 방향으로 이미지의 deep features를 추출한 후 설계된 filter gate를 적용하여 통합된 features들의 sequence를 생성하는 arbitrary orientation network (AON)를 제안함.
- 최종적으로 character sequence를 생성하기 위해 1D-attention 기반 decoder를 적용하였으며, 이 방법에 대한 전체적인 아키텍처는 그림 7의 (c)에서 볼 수 있음.
- 비록 AON은 word-level의 annotation를 이용하여 학습할 수 있지만, 이렇게 복잡한 4개 방향의 network를 사용하기 때문에 중복된 표현을 야기시킴.
attention 기반 기법들의 성능은 저품질의 이미지, 심하게 왜곡된 text와 같은 보다 도전적인 상황에서 저하될 수 있으며, 이러한 상황에 영향을 받은 text는 잘못된 정렬(misalignment) 및 attention 표류(drift) 문제를 야기할 수 있음[152].
- 이러한 문제의 심각성을 줄이기 위해, Cheng et al. [64]은 character 인식을 위한 attention network (AN)와 AN의 attention 조정을 위한 focusing network (FN)로 구성되는 focusing attention network (FAN)를 제안함.
- [64]에서 볼 수 있듯이, FAN은 자동으로 표류된(drifted) attention을 교정할 수 있기 때문에 규칙적인 text 인식 성능을 향상시킬 수 있음.
- 그림 7의 (d)에서 제시된 것처럼 몇몇 방법들[63, 151, 164]은 2D attention[167]을 사용하여 1D attention의 단점을 극복했음.
- 이러한 방법들은 decoding 동안에 2D 공간의 개별적인 character 특징에 초점을 두고 학습시키며, character-level [63] 또는 word-level [164]의 annotation을 이용하여 훈련할 수 있음.
- 예를 들어, Yang et al. [63]은 불규칙한 scene text의 인식을 향상시키기 위해 시각적 표현(visual representations)의 학습을 도모하도록 fully convolutional network (FCN)을 사용는 보조의(auxiliary) dense한 character detection task를 도입함.
- 이 후, Liao et al. [151]는 1D 공간 대신에 2D 공간에서 불규칙한 scene text 인식 문제를 모델링하는 Character Attention FCN (CA-FCN)이라고 불리는 프레임워크를 제안함.
- 이 network에서는 임의의 이미지 모양 내 여러 방향을 갖는 character들을 예측하는데 character attention module [168]을 사용함.
- 하지만, 이 프레임워크는 character-level의 annotation이 필요하며, end-to-end로 학습할 수 없음[48].
- 대조적으로 Li et al. [164]는 character-level의 annotation을 사용하지 않고도 학습을 위해 실제 데이터와 합성 데이터를 모두 활용할 수 있도록 word-level의 annotation을 사용하는 모델을 제안함.
- 하지만 2-layer의 RNN은 계산 병렬화를 배제하고 encoder 및 decoder 모두에 각각 채택되어 계산적인 부담이 크게 됨.
- 2D attention 기반 기술[63, 151, 164]의 계산 비용 문제를 다루기 위해, [165]와 [71]에서는 2D attention 기술의 RNN 단계를 제거한 대신 convolution-attention network [169]를 사용하였으며, 처리 속도를 가속화하는 완전 병렬 계산뿐만 아니라 불규칙한 text 인식을 할 수 있게 됨.
- 그림 7의 (e)는 이러한 attention 기반 카테고리의 일반적인 block diagram을 보여줌. 예를 들어, Wang et al. [71]은 단순하며 강건한 convolutional-attention network (SRACN)를 제안하였으며, convolutional attention network decoder를 2D CNN features에 직접적으로 적용함.
- SRACN은 입력 이미지를 sequence 형태의 표현으로 변환시킬 필요가 없으며, text 이미지를 character sequence로 직접적으로 매핑할 수 있음.
- 반면에 Wang et al. [165]은 scene text 인식 문제를 시공간(spatio-temporal) 예측 문제로 여기고 scene text 인식을 위한 focus attention convolution LSTM (FACLSTM) network를 제안함.
- [165]에서 볼 수 있듯이, FACLSTM은 text 인식에 보다 효율적이며, 특히 CUT80 [140] 및 SVT-P [170]와 같은 곡선이 있는 scene text 데이터셋에 효율적임.
- 그림 7의 (e)는 이러한 attention 기반 카테고리의 일반적인 block diagram을 보여줌. 예를 들어, Wang et al. [71]은 단순하며 강건한 convolutional-attention network (SRACN)를 제안하였으며, convolutional attention network decoder를 2D CNN features에 직접적으로 적용함.
3 Experimental Results
본 장에서는 다양한 도전 요소들을 포함하는 최근의 공용 데이터셋[75, 84, 126, 139, 140, 170, 171]에 대해 최신의 몇가지 scene text detection[35, 43, 46, 47, 110, 112, 113] 및 recognition[16, 52–56] 기법들을 이용하여 광범위한 평가를 수행함.
- scene text detection 또는 recognition 체계의 중요한 특성 중 하나는 일반화인데, 이는 한 데이터셋에서 훈련된 모델이 다른 데이터셋의 도전적인 text instance를 어떻게 검출하거나 인식할 수 있는지를 보여줌.
- 이러한 평가 전략은 특정 데이터셋에서 주로 훈련 및 평가되는데 사용되던 text detection 및 recognition 방법을 평가함에 있어 발생하는 격차를 해소하기 위한 시도이기 때문에, 고려 중인 방법들에 대한 일반화 능력을 평가하기 위해 본적 없는(unseen) 데이터셋에 대해 검출 및 인식 모델을 모두 비교하는 것을 제안함.
1) 평가를 위해 선택된 딥러닝 기반의 scene text detection 기법들
- PMTD[47](https://github.com/jjprincess/PMTD), CRAFT[46](https://github.com/clovaai/CRAFT-pytorch), EAST[35](https://github.com/argman/EAST), PAN[110](https://github.com/WenmuZhou/PAN.pytorch), MB[112](https://github.com/Yuliang-Liu/Box_Discretization_Network), PSENET[113](https://github.com/WenmuZhou/PSENet.pytorch), Pixellink[43](https://github.com/ZJULearning/pixel_link)
- 학습: 각 기법들에 대해 MB[112]를 제외하고는, 저자의 GitHub 페이지 내 ICDAR15 [75] 데이터셋 대해 학습된 해당 pre-trained 모델을 직접 사용함. 반면에 MB[112]에 대해서는 저자가 제공한 코드에 따라 ICDAR15를 이용하여 알고리즘을 훈련시킴.
- 평가: detector의 테스트를 위해 ICDAR13 [126], ICDAR15 [75], COCO-Text [172] 가 사용됨. 이러한 평가 전략은 편향된 평가를 피할 수 있으며, 해당 기법들의 일반화에 대한 평가를 할 수 있도록 해줌. 표 5는 이러한 데이터셋 각각에 대한 테스트 이미지의 수를 나타내고 있음.

2) 평가를 위해 선택된 딥러닝 기반의 scene text recognition 기법들
- CLOVA [56], ASTER [16], CRNN [52], ROSETTA [55], STAR-Net [54], RARE [53]
- 학습: 최근에는 SynthText (ST) [125] 및 MJSynth (MJ) [60]와 같은 합성 데이터셋이 인식 모델 구축을 위해 광범위하게 사용되고 있으므로, 이러한 합성 데이터셋을 이용했을 때 최신의 기법들에 대해 평가하는 것을 목적에 둠. 모든 인식 모델은 이러한 2개의 데이터셋을 조합시켜 훈련시킴.
- 평가: ICDAR03 [171], ICDAR13 [126], ICDAR15 [75], COCOText [172], II5k [139], CUT80 [140], SVT [77], SVT-P [170] 등의 데이터셋을 사용함. 표 5에서 볼 수 있듯이, 선택된 데이터셋에는 주로 규칙적이거나 수평 방향을 갖는 text 이미지 및 곡선이 있고, 회전되어 있고, 왜곡되어 있어 불규칙한 text로 불리는 다른 데이터셋들이 포함됨. 평가 동안에는 36개의 영.숫자 클래스들을 사용함(숫자 클래스 10개 + 영어 대문자(A-Z) 클래스 26개)
본 장의 나머지 3.1장에서는 각각의 활용된 데이터셋 내에 존재하는 도전 요소에 대한 요약을, 3.2장에서는 평가 metric에 대한 설명을, 3.3장에서는 text detection 기법들에 대한 정량적, 정성적 분석 및 논의를, 3.4장에서는 text recognition 기법들에 대한 정량적, 정성적 분석 및 논의를 할 예정임.
3.1 Datasets
scene text detection 및 recogntion을 위해 도입된 몇몇의 데이터셋들이 존재함[60, 75–77, 82, 125, 126, 131, 132, 137, 139, 140, 170, 172]. 이러한 데이터셋들은 크게 (1). 훈련을 주목적으로 하는 합성 데이터셋들[174, 60]과 (2). 검출 성능 및 평가 체계의 평가를 위해 광범위하게 사용되는 실세계 데이터셋들[75, 77, 82, 126, 132, 172]로 나뉨. 표 5는 최근의 text detection 및 recognition 데이터셋들 몇몇에 대한 비교를 나타내고 있으며, 본 장의 나머지에서는 이러한 데이터셋 각각에 대한 요약을 할 예정임.
3.1.1 MJSynth
- MJSynth [60] 데이터셋은 특히 scene text recognition을 위해 고안된 합성 데이터셋으로써, 그림 8의 (a)는 이러한 데이터셋의 몇몇 예를 나타내고 있음.
- 이 데이터셋에는 약 890 만개의 word-box를 가진 gray level의 합성 이미지를 포함하고 있으며, 이들은 Google 폰트와 ICDAR03 [171] 및 SVT [77] 데이터셋으로부터 생성됨.
- 해당 데이터셋 내 모든 이미지들은 word-level로 ground-truth가 annotation되어 있으며, 9만개의 일반적인 영어 word가 이러한 text 이미지들을 생성하는데 사용되어짐.
3.1.2 SynthText
- SynthText in the Wild 데이터셋[174]은 858,750개의 합성된 scene 이미지들과 7,266,866개의 word-instances 및 28,971,487개의 characters들을 포함하고 있음.
- 해당 데이터셋 내 text instances는 그림 8의 (b)와 같이 대부분은 여러 방향성이 있으며, text sequence 뿐만 아니라, word 및 character level의 회전된 bounding box들로 annotation되어 있음.
- 서로 다른 폰트, 크기, 방향, 색상으로 렌더링된 text를 자연 이미지와 섞어서 만들어졌으며, 원래 scene text detection [174]을 평가하기 위해 고안되었으며, 몇몇의 detection 파이프라인을 훈련시키는데 활용됨.
- 하지만, 최근의 많은 text 인식 기법들[16, 66, 69, 70, 152]은 또한, 인식 성능의 향상을 위해 해당 데이터셋의 crop된 word 이미지를 MJSynth [60] 데이터셋과 결합시킴.

3.1.3 ICDAR03
- ICDAR03 데이터셋[171]은 수평 방향의 카메라에서 캡처된 scene text 이미지를 포함하고 있으며, 최근의 text 인식 기법들에서 사용되고 있음.
- 훈련용 1,156개, 테스트용 110개의 text instance들을 포함하고 있으며, 본 논문에서는 최신의 text 인식 기법들에 대한 평가를 위해 [56]과 동일한 테스트 이미지들을 사용함.
3.1.4 ICDAR13
- ICDAR13 데이터셋[126]은 수평 방향의 text 이미지를 포함하고 있으며, 많은 detection 및 recognition 기법들[35, 43, 46, 47, 49, 52–54, 56, 166]에서 사용되는 벤치마크 데이터셋임.
- 주어진 bounding box의 ground truth annotation은 [좌상단 x 좌표(x1), 좌상단 y 좌표(y1), 가로(x2), 세로(y2)] 와 같은 형태로 되어 있음.
- 해당 데이터셋의 detection 부분은 훈련용 229개 이미지, 테스트용 233개의 이미지로 구성되어 있으며, recognition 부분은 훈련용 848개의 word 이미지, 테스트용 1095개의 word 이미지로 구성되어 있음.
- 해당 데이터셋 내 모든 text 이미지들은 품질이 좋으며, text 영역은 전형적으로 이미지 내 가운데 위치함.
3.1.5 ICDAR15
- ICDAR15 데이터셋[75]은 text detection 또는 recognition 체계를 평가하는데 사용되어짐.
- detection 부분은 훈련용 1000개, 테스트용 500개로 구성되는 전체 1500개의 이미지가 있으며, recogntion 부분은 훈련용 4468개, 테스트용 2077개 이미지로 구성되어 있음.
- 해당 데이터셋은 다양한 방향을 갖는 worl-level의 text를 포함하고 있으며, ICDAR13 데이터셋에 포함된 것들보다 다른 조명 및 복잡한 배경 상태에서 캡처되었지만, 대부분의 이미지들은 실내 환경에서 캡처됨.
- scene text detection에 있어, ICDAR13 [126]에서 사용된 직사각형(rectangular) 형태의 ground-truth는 여러 방향을 갖는 text를 표현하는 용도로는 다음과 같은 이유에서 적합하지 못함. (1). 불필요한 중복을 야기함, (2). 가장자리(marginal)의 text를 정확하게 localization 할 수 없음, (3). 불필요한 배경 잡음을 제공함[175].
- 따라서 위의 문제를 해결하고자, 이러한 데이터셋들에 대한 annotation들은 text의 네 모서리 꼭지점을 나타내는 [x1, y1, x2, y2, x3, y3, x4, y4]의 사각형(quadrilateral) boxes로 표현되어짐.
3.1.6 COCO-Text
- 이 데이터셋은 [172]에서 처음 소개되었으며, 현재까지 가장 크고 도전적인 text detection 및 recognition 데이터셋임.
- 표 5에서 볼 수 있듯이, 해당 데이터셋은 63,686개의 annotation된 이미지들을 포함하고 있으며, 훈련용 이미지가 43,686개, 검증 및 테스트용 이미지로 20,000개를 제공하고 있음.
- 동일한 이미지셋에 대해 173,589개 대신 239,506개의 annotation된 text instance를 포함하고 있으므로 본 논문에서는 해당 데이터셋의 두번째 version인 COCO-Text를 사용함.
- ICDAR13에서와 같이, 해당 데이터셋의 text 영역은 직사각형의 bounding box들을 사용하여 word-level로 annotation되어 있음.
- 또한, 해당 데이터셋의 text instance는 야외 장면, 운동장, 식료품점과 같은 다양한 장면에서 캡처되었으며, 다른 데이터셋과 달리 저해상도, 특수 문자, 부분적인 가려짐을 가진 이미지들도 포함되어 있음.
3.1.7 SVT
- Street View Text (SVT) 데이터셋[77]은 Google의 Street View를 사용하여 수집되었으며, 흐릿함(blurriness) 및(또는) 해상도의 가변성이 높은 scene text들이 포함된 실외 이미지들의 모음으로 구성되어 있음.
- 표 5에서 볼 수 있듯이, 해당 데이터셋은 detection 및 recognition task에 대한 평가를 위해 각각 250개, 647개의 이미지들을 포함하고 있으며, 본 논문에서는 해당 데이터셋을 최신의 인식 체계를 평가하는데 사용함.
3.1.8 SVT-P
- SVT-Perspective (SVT-P) 데이터셋 [170]은 원근 왜곡이 있는 scene text 인식을 평가하기 위해 특별히 고안되었음.
- Google의 Street View에서 정면이 아닌 각도를 갖는 스냅샷에서 수집된 645개의 crop된 text instance를 갖는 238개의 이미지들로 구성되어 있으며, 많은 이미지들은 원근 왜곡이 되어 있음.
3.1.9 IIIT 5K-words
- IIIT 5K-words 데이터셋은 5000개의 word가 crop된 scene 이미지들을 포함하고 있으며[139], word 인식 task를 위해서만 사용됨.
- 훈련용 2000개, 테스트용 3000개의 word 이미지로 분할되어 있으며, 본 논문에서는 평가를 위한 테스트셋으로만 사용함.
3.1.10 CUT80
- Curved Text (CUT80) 데이터셋은 곡선이 있는 text 이미지들에 초점을 둔 최초의 데이터셋임[140].
- 해당 데이터셋은 text detection 및 recognition 알고리즘의 평가를 위해 각각 80개의 전체 이미지와 280개의 crop된 word 이미지들을 포함하고 있음.
- 비록 CUT80 데이터셋이 원래 곡선이 있는 text detection을 위해 고안되었지만, scene text recognition을 위해서도 널리 사용되고 있음[140].
3.2 Evaluation Metrics
ICDAR의 표준 평가 metric [75, 126, 137, 176]은 text detection 기술들 간의 정량적 비교를 하기 위해 가장 일반적으로 사용되는 프로토콜임[1, 2].
3.2.1 Detection
[35, 43, 46, 47]에서와 같이 주어진 text detector의 성능을 정량화 하기 위해, 본 논문에서는 정보 검색 분야에서 사용되는 Precision (P) 및 Recall (R) metric를 활용함. 추가로, 아래의 식으로 얻을 수 있는 H-mean 또는 F1-score를 사용함.

여기서 Precision 및 Recall 계산은 j번째 ground-truth 및 i번째 detection bounding box에 대해 얻은 ICDAR15의 intersection over union (IoU) metric [75]을 사용하여 수행됨. 올바른 검출에 대한 계수(counting)를 위해 IoU 임계값이 0.5 이상인 경우를 사용함.

3.2.2 Recognition
Word recognition accuracy (WRA)는 text 인식 체계를 평가하기 위해 character recognition accuracy 대신 일상 생활에 적용되므로, 일반적으로 사용되는 평가 metric임[16, 52–54, 56]. crop된 word 이미지 셋이 주어진 경우, WRA는 아래와 같이 계산됨.

3.3 Evaluation of Text Detection Techniques
3.3.1 Quantitative Results
detection 기법들에 대한 일반화 능력을 평가하기 위해 ICDAR13 [126], ICDAR15 [75], COCO-Text [84] 데이터셋에 대해 검출 성능을 비교하였으며, 표 6은 선택된 최신의 검출 기법들(PMTD [47], CRAFT[46], PSENet [113], MB [112], PAN [110], Pixellink [43], EAST [35])에 대한 검출 성능을 나타내고 있음.
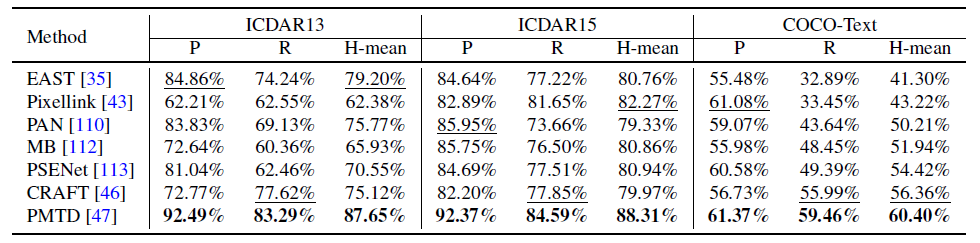
- 표에서 볼 수 있듯이, ICDAR13 데이터셋에서는 ICDAR15 데이터셋에 포함된 도전적인 조건들이 적음에도 불구하고, 고려했던 모든 기법들의 검출 성능은 떨어짐.
- ICDAR15와 ICDAR13의 데이터셋에 대해 동일한 기법의 성능을 비교했을 때, H-mean 관점에서 PMTD는 최소의 성능 하락(~0.6%)을 보인 반면에, ICDAR15에서는 두번째로 우수한 성능 순위를 보였던 Pixellink는 ICDAR13에서 H-mean 값이 ~20.0%까지 하락하는 가장 안좋은 결과를 보임.
- 추가로, COCO-Text 데이터셋에 대해서는 모든 기법들이 상당한 검출 성능 하락을 보였으며, 이는 해당 모델들이 서로 다른 도전적인 데이터셋들에 대해서는 아직까지는 일반화 능력을 제공하지 못한다는 것을 나타내고 있음.
3.3.2 Qualitative Results
그림 9는 ICDAR13, ICDAR15, COCO-Text 데이터셋의 몇몇 도전적인 시나리오에 대해 고려된 기법들[35, 43, 46, 47, 110, 112, 113]을 적용한 검출 결과 샘플들을 나타내고 있음.

- 비록 가장 우수한 text detector인 PMTD와 CRAFT detector가 다양한 방향 및 부분적인 가려짐 수준에서 text 검출 시 보다 나은 강건함을 보이긴 했지만, 이러한 검출 결과들은 해당 기법들의 성능이 여전히 완벽으로부터는 멀리 있다는 것을 나타내고 있음.
- 특히, text instances가 어려운 폰트, 색상, 배경, 조명 변화, in-plane 회전 또는 도전적인 요소들의 조합 등과 같이 어려운 경우에 영향을 받으면 더욱 성능이 하락하게 됨.
지금부터는 scene text detection 시 접하게 되는 일반적인 어려움에 대해서 분류를 하여 이야기를 할 예정임.
1) 다양한 해상도 및 방향
- 보행자 검출[177] 또는 차량 검출[178, 179]와 같은 detection task와 달리, 자연 환경의 text는 보통 보다 넓고 다양한 해상도와 방향을 갖고 나타나게 되며, 이는 부족한 검출 성능을 쉽게 야기하게 됨[2, 3].
- 예를 들어, 그림 9의 (a)의 결과에서 볼 수 있듯이, ICDAR13 데이터셋에 대해 모든 기법들은 기본적인 파라미터들을 사용한 경우 저해상도 및 고해상도의 text 검출에 실패를 하게 되며, 같은 결론을 ICDAR15 데이터셋을 이용한 그림 9의 (h)에서, COCO-Text 데이터셋을 이용한 그림 9의 (q)에서 볼 수 있음.
- 뿐만 아니라, 이러한 결론은 그림 10에서 볼 수 있듯이 고려된 데이터셋들에 대해 pixel들의 word 높이 분포를 보면 확인 할 수 있음.

- 고려된 검출 모델들은 여러 방향을 갖는 text를 처리하는데 초점을 두긴 했지만, in-plane 회전 또는 높은 곡률에 영향을 받은 text를 검출하는데는 어려움을 겪을 뿐만 아니라, 이러한 도전적인 요소들을 해결하는데는 있어서는 여전히 강건함이 부족함.
- 예를 들어, ICDAR13 데이터셋에 대해서는 그림 9의 (a)에서, ICDAR15 데이터셋에 대해서는 그림 9의 (j)에서, COCO-Text 데이터셋에 대해서는 그림 9의 (p)에서 각각 낮은 검출 성능을 확인 할 수 있음.
2) 가려짐
- 다른 object detection task와 유사하게 text는 그림 9에서 볼 수 있듯이, text instance에 놓인 object나 text처럼 자체적으로 또는 다른 objects들에 의해서 가려질 수 있음.
- 따라서, text detection 알고리즘이 적어도 부분적으로 가려진 text를 검출할 것으로 예상되지만, 그림 9의 (e)와 (f)의 샘플 결과에서 볼 수 있듯이, 연구된 기법들은 주로 부분적으로 가려진 영향에 의해 text 검출에 실패를 함.
3) 열화된 영상 품질
- 자연 환경에서 캡처된 text 이미지는 일반적으로 다양한 조명 조건(그림 9의 (b)와 (d)), 모션 블러(그림 9의 (g)와 (h)), 낮은 명암대비의 text(그림 9의 (o)와 (t)) 등에 대해 영향을 받게 됨.
- 그림 9에서 볼 수 있듯이, 연구된 기법들은 이러한 유형의 이미지에 대해서는 저조하게 동작하며, 이는 존재하는 text detection 기술이 이러한 도전적인 요소를 명시적으로 해결하지 못했기 때문임.
3.3.3 Discussion
본 장에서는, 언급된 detection 기법들에 대해 강건함(robustness) 및 속도를 고려하여 평가 함.
1) 검출의 강건함
- 그림 10에서 볼 수 있듯이, 3개 대상의 scene text detection 데이터셋들 안에 존재하는 대부분의 대상 word들은 낮은 해상도를 갖으므로 text 검출을 더 어렵게 만듬.
- 다양한 IoU 값에 대해 detector의 강건함을 비교하기 위해, 그림 11은 연구된 기법들에 대해 IoU 임계값의 범위를 0~1 사이로 변화시키면서 계산된 H-mean에 대해 나타내고 있음.

- 해당 그림으로부터 IoU 임계값을 0.5 초과(IoU > 0.5)로 증가시키면 3개의 데이터셋 모두에서 detector가 달성한 H-mean 값은 빠르게 감소한다는 것을 알 수 있으며, 이는 고려된 전략들이 더 높은 임계값에 대해서는 적절한 중첩 비율(IoU)를 제공하지 않음을 나타냄.
- 보다 구체적으로, ICDAR13 데이터셋(그림 11의 (a))에서는 EAST[35] detector가 IoU > 0.8인 경우부터는 PMTD[47]의 성능을 능가하게 되며, 이는 EAST detector가 ICDAR13 데이터셋에 풍부한 다양한 규모(scale)의 text instance를 보다 정확하게 검출할 수 있는 multi-channel FCN network를 사용하는 것에 기인하고 있음.
- 또한, ICDAR15에서는 2위를 차지한 Pixellink [43]가 ICDAR13에서는 가장 나쁜 검출 성능을 보이며, 이렇게 저조한 성능은 그림 9의 정성적 결과의 도전적인 경우들에서도 확인 할 수 있음.
- COCO-Text [84] 데이터셋의 경우, 모든 방법들은 해당 데이터셋에서 저조한 H-mean 성능을 나타내며(그림 11의 (c)), 일반적으로 IoU > 0.7 인 경우에는 detector의 H-mean이 ~60%에서 ~30% 미만으로 절반 가량 감소를 하게 됨.
- 요약하자면, IoU < 0.7 인 경우에는 EAST와 Pixellink의 H-mean 값보다 PMTD와 CRAFT의 H-mean 값이 보다 우수함.
- CRAFT는 character 기반 방법이므로, 개별 character를 이용하여 어려운 폰트의 word를 localization 하는데 있어서 더 잘 동작하게 됨.
- 또한, 대부분의 다른 기법들에서 사용했던 전체 word에 대한 detection을 사용한 것이 아니라, 개별 character를 localization 할 수 있는 특성으로 인해 서로 다른 크기를 갖는 text를 보다 잘 처리할 수 있음.
- COCO-Text 및 ICDAR15 데이터셋은 여러 방향 및 곡선을 갖는 text가 포함되어 있기 때문에, 그림 11에서 볼 수 있듯이 PMTD는 IoU > 0.7 에 대해 정확한 검출을 위한 다른 기법들 대비 부정확한 검출에 있어서 강건함을 보여줌.
- 이는 이 기법이 임의의 모양을 갖는 text를 보다 잘 예측할 수 있음을 의미하며, 곡선 형태의 text, 다양한 방향을 갖는 어려운 폰트, 그림 9의 in-plane으로 회전된 text와 같은 어려운 경우들에 대해서도 명백함.
2) 검출 속도
- 검출 기법들에 대한 속도 평가를 위해, 그림 12에서는 IoU >= 0.5인 경우에 대해 각 검출 알고리즘의 H-mean 대비 frame per second(FPS)를 비교한 결과를 나타내고 있음.
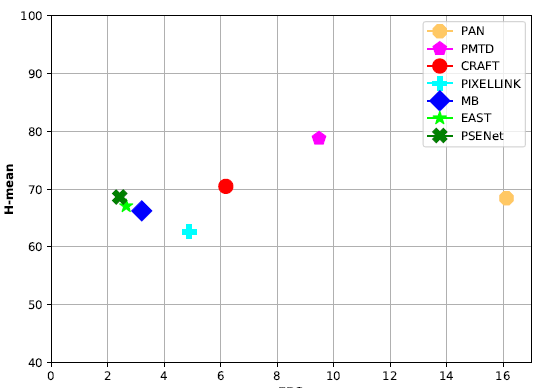
- 가장 느린 detector는 PSENet [113]이며, 가장 빠른 detector는 PAN [110]이고, PMTD [47]은 가장 우수한 H-mean 값을 가지면서 두번째로 빠른 detector의 성능을 보임.
- PAN은 backbone으로 경량 모델인 18개의 layers(ResNet18)를 갖는 ResNet[148]을 이용하는 낮은 계산 비용의 segmentation head를 활용하고 몇 단계의 후처리를 적용하여 효율적인 detector를 생성함.
- 반면에, PSENet은 text instance 예측을 위해 backbone으로 좀 더 깊은 모델을(50개의 layer를 가진 ResNet) 사용하고 여러개의 scale를 사용하므로 테스트 시 속도가 느려지게 됨.
3.4 Evaluation of Text Recognition Techniques
3.4.1 Quantitative Results
이번 장에서는 규칙적인 text 데이터셋[126, 139, 171] 및 불규칙적인 text 데이터셋[75, 84, 140, 170]에 대해 선택된 scene text recogntion 기법들[16, 52-55]을 식 (3)에 정의된 word recognition accuracy (WRA) 관점에서 비교를 하였으며, 표 7에 정량적인 결과를 요약함.

- 표에서 볼 수 있듯이, 모든 기법들은 일반적으로 규칙적인 text를 가진 데이터셋[126, 139, 171]에서 불규칙적인 text를 가진 데이터셋[75, 84, 140, 170]보다 더 높은 WRA 값을 달성함.
- 게다가, feature 추출 단계에서 text 이미지를 공간적으로 변환하기 위한 교정(rectification) 모듈을 포함하고 있는 기법들, 즉 ASTER [16], CLOVA [56], STAR-Net [54] 등은 불규칙한 text를 가진 데이터셋에서 보다 잘 수행되어짐.
- 추가로, attention 기반 기법들(ASTER [16], CLOVA [56])은 CTC 기반 기법들(CRNN [52], STAR-Net[54], ROSETTA [55])보다 불규칙한 text를 정렬하는 문제를 보다 잘 다룰 수 있기 때문에 보다 우수한 성능을 보임.
- 연구된 text recognition 기법들은 표 3에서 볼 수 있듯이 훈련을 위해 합성 이미지만 사용했음에도, 자연 환경의 이미지에서 text recognition을 처리할 수 있었다는 점에 주목할 필요가 있음.
- 하지만, COCO-Text 데이터셋의 경우 각각의 방법들은 다른 데이터셋에서 얻은 WRA 값보다 훨씬 더 낮은 WAR 값을 보였으며, 이는 연구된 기법들이 완전히 직면하지 못한 데이터셋 내 더 복잡한 상황들이 존재하는데 기인하고 있다고 할 수 있음.
다음 장에서는 대부분의 최신의 scene text recognition 체계가 현재 직면하고 있는 도전적인 요소들에 대해 강조하여 설명할 예정임.
3.4.2 Qualitative Results
본 장에서는 고려된 text recognition 전략들과 관련하여 정량적인 비교 뿐만 아니라 존재하는 기술들에서 여전히 부분적으로 혹은 완전하게 실패하게 되는 도전적인 시나리오에 대해 조사를 함. 그림 13은 ICDAR13, ICDAR15, COCO-Text 데이터셋에 대해 고려된 text recognition 기법들의 정성적 성능을 나타내는 샘플들을 보여주고 있음.

- 그림 13의 (a)에서 볼 수 있듯이, [16, 53, 54, 56]의 기법들은 여러 방향성 및 곡선을 갖는 text에 대해서 잘 동작하였으며, 이러한 기법들은 불규칙한 text를 표준적인 포맷으로 교정하도록 파이프라인 내에 교정 모듈로서 TPS(Thin-Plate Spline)를 채택했기 때문임.
- 따라서 이렇게 정규화된 이미지에서 이후의 CNN은 feature를 보다 잘 추출할 수 있게 됨. 그림 13의 (b)는 복잡한 배경 또는 보지 못한(unseen) 폰트에 대한 text를 설명하고 있으며, 이 경우에 있어 feature 추출 시 backbone으로 deep한 CNN 아키텍처인 ResNet을 활용한 기법들(ASTER, CLOVA, STAR-Net, ROSETTA)이 VGG를 사용한 기법들(RARE, CRNN) 보다 뛰어난 성능을 보임.
- 비록 고려된 최신의 기법들이 그림 13의 (c)와 같이 몇몇 도전적인 예에서 text를 인식할 수 있는 능력을 보여주었지만, 이러한 기법들이 여전히 명백하게 다루기 어려운 도전적인 경우들(붓글씨(calligraphic) 폰트, 심한 가려짐, 저해상도 및 조명 변화를 가진 text)이 있음.
그림 14는 고려된 벤치마크 데이터셋에서 연구된 모든 recognition 기법들이 처리에 실패하는 도전적인 경우들에 대해서 나타내고 있으며, 본 장의 나머지 부분에서는 이렇게 실패한 경우들을 분석하고 이러한 도전적인 요소들을 다룰 수 있는 향 후 연구에 대해서 제안을 할 예정임.

1) 방향성을 갖는 text
- 존재하는 최신의 scene text recognition 기법들은 수평 방향[52, 61], 여러 방향성[64, 66], 곡선을 갖는 text[16, 53, 56, 70, 152, 166] 등을 인식하는데 보다 초점을 두었으며, 공간 교정(spatial rectification) 모듈[70, 154, 166]을 활용하고 전형적으로 text를 읽기 위해 설계된 sequence-to-sequence 모델을 사용함.
- 임의의 방향에 있는 text 인식을 해결하기 위한 이러한 시도들에도 불구하고, 자연 환경 이미지에는 심한 곡선을 갖는 text, in-plane 회전 text, 수직 방향 text, 그림 14의 (a)와 같이 아래서 위로(bottom-to-top), 위에서 아래(top-to-bottom)로 쌓여 있는 text 등과 같이 이러한 방법들이 처리할 수 없는 여전히 방향성을 가진 text 유형들이 존재함.
- 추가로, 수평 및 수직 방향의 text는 서로 다른 특성을 갖기 때문에, 연구자들은 최근에 통합된 프레임워크 내에 양쪽 유형의 text 인식을 위한 기술을 고안하기 위해 시도함[180, 181].
- 그러므로, 향 후 연구는 서로 다른 방향에 대해 동시에 인식할 수 있는 모델을 구축하는 것이 필요함.
2) 가려짐이 있는 text
- 비록 존재하는 attention 기반 기법들[16, 53, 56]이 부분적인 가려짐을 고려했을 때 text를 인식할 수 있는 능력을 보였지만, 그림 14의 (b)와 같이 가려짐이 심한 경우의 text 인식에 있어서는 성능이 떨어짐.
- 이는 현재의 존재하는 기법들이 가려짐을 극복하기 위해 문맥 정보를 광범위하게 활용하지 못하고 있기 때문임.
- 따라서 향 후 연구들은 가려진 text로 인해 보이지 않는 characters를 예측 할 때, 문맥을 최대한 활용할 수 있는 우수한 언어 모델[182]를 고려해야 함.
3) 열화된 영상 품질
- [16, 52–56]과 같은 최신의 text recognition 기법들은 인식 정확도에 있어서 저해상도, 조명 변화 등과 같은 열화된 이미지 품질이 인식 정확도에 주는 영향을 특별히 극복하지 못했다는 점에 유의할 필요가 있으며, 불충분한 인식 성능은 그림 14의 (c)와 (d)의 샘플에 대한 정성적인 결과로부터 관찰할 수 있음.
- 제안된 미래 연구로는, image super-resolution [183], image denoising [184, 185], 장애물(obstructions)을 통한 학습 [186]과 같은 이미지 향상(enhancement) 기술이 어떻게 이러한 문제를 해결할 수 있는지에 대해 연구하는 것이 중요함.
4) 복잡한 폰트
- 자연 환경 내 이미지에는 현재의 기법들이 명시적으로 처리할 수 없는 그래픽 폰트(Spencerian Script, Christmas, Subway Ticker)들을 갖는 몇몇의 도전적인 text들이 있음(그림 14의 (e)를 참고).
- 자연 환경 내 이미지의 복잡한 폰트를 갖는 text를 인식함에 있어, 이러한 체계의 특징 추출 단계를 개선함으로써 서로 다른 폰트를 인식할 수 있는 체계를 설계하거나 한 폰트에서 다른 폰트로의 mapping을 학습하는 style transfer 기술[187, 188]을 사용하는 것을 강조할 수 있음.
5) 특수 문자
- 영.숫자 문자에 추가로, 자연 환경의 이미지에는 특수 문자(예: 그림 14의 (f)에 있는 the $, /, -, !, :, @ and # 등의 문자)들이 많지만, 존재하는 text recognition 기법들은[52, 53, 56, 151, 155] 학습 및 테스트 동안에 이들을 배제시킴.
- 따라서, 이렇게 pretrained된 모델들을 특수 문자를 인식할 수 없는 어려움을 겪게 됨.
- 최근에 CLOVA[46]는 특수 문자에 대해 모델을 훈련하면 인식 정확도가 향상된다는 것을 보여주었으며, 향 후에는 text recognition 모델의 훈련 및 평가 모두에 있어서 특수 문자를 포함시키는 방법에 대한 연구가 필요하다는 것을 제안함.
3.4.3 Discussion
본 장에서는 ICDAR13, ICDAR15 and COCO-Text 데이터셋을 사용하여 다양한 word 길이 및 종횡비 하에 고려된 recognition 기법들[52, 53, 56, 151, 155]의 성능에 대한 실험적 연구를 수행하였으며, 추가적으로 이러한 기법들에 대해 인식 속도를 비교함.
1) word의 길이
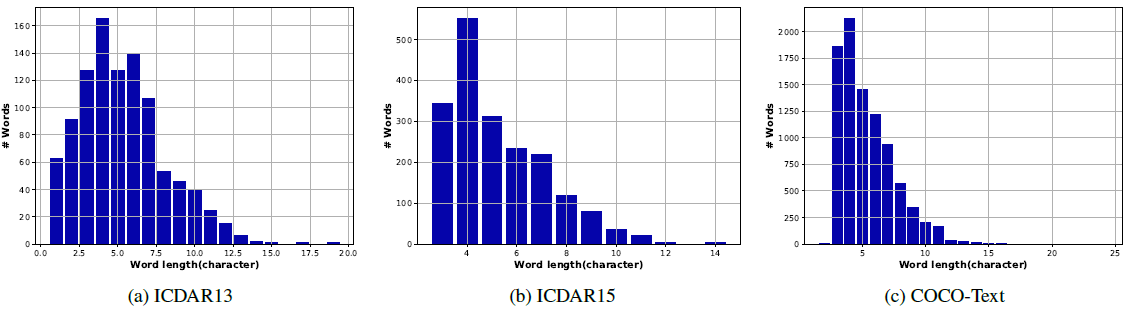
- 분석에 있어서, 먼저 그림 15와 같이 ICDAR13, ICDAR15, COCO-Text 데이터셋에 대해 서로 다른 word 길이를 갖는 이미지의 개수를 취득함.
- 그림 15에서 볼 수 있듯이, 대부분의 word들은 2~7자 사이의 characters를 갖는 word 길이를 갖고 있기 때문에 길이가 짧거나 중간을 갖는 word들을 분석하는데 초점을 둠.
- 그림 16은 ICDAR13, ICDAR15, COCO-Text 데이터셋에 대해 서로 다른 word 길이에 따른 text recognition 기법들의 정확도를 나타내고 있음.

- 그림 16의 (a)에서 볼 수 있듯이, ICDAR13 데이터셋에서는 character의 개수가 2보다 큰 word들의 경우에 모든 기법들은 일관성 있는 정확도 값을 보였으며, 이는 해당 데이터셋 내 모든 text instance들은 수평 방향이며 고해상도를 갖기 때문임. 하지만 character의 개수가 2인 word들에 대해서는 RARE가 가장 낮은 정확도(~58%)를 나타낸 반면, CLOVA는 가장 높은 정확도(~83%)를 나타냄.
- ICDAR15 데이터셋에 대해서는 고려된 기법들의 인식 정확도가 ICDAR13[126]과 유사하게 일관적인 추세를 따르고 있음. 하지만, 인식 성능은 일반적으로 ICDAR13보다 낮으며 이는 해당 데이터셋에는 ICDAR13보다 더 많은 블러가 있고, 저해상도와 회전된 이미지들을 포함하고 있기 때문임.
- COCO-Text 데이터셋에 대해서는 ASTER이 가장 우수한 정확도를, CLOVA가 두번째로 우수한 결과를 보였으며, character의 개수가 12개 이상인 word 길이에서의 약간의 변동을 제외하고는 전반적으로 모든 방법들이 유사한 추세를 따름.
2) 종횡비
본 실험에서는 서로 다른 종횡비(height/width)를 갖는 word에 대해 연구된 기법들이 달성한 정확도에 대해서 살펴봄.
- 그림 17에서 볼 수 있듯이, 고려된 데이터셋 내 모든 word 이미지의 종횡비는 0.3~0.6 사이임.
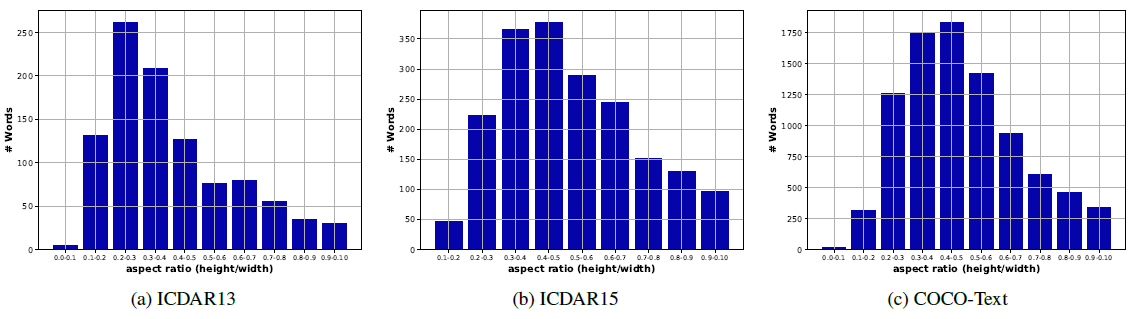
그림 18은 ICDAR13, ICDAR15, COCOText 데이터셋 상에서 계산된 word 종횡비 대비 연구된 기법들[16, 52–56]의 WRA 값을 보여줌.

- 그림으로부터, 0.3 미만의 종횡비를 갖는 이미지들에 대해서는 연구된 기법들 모두 3개의 고려된 데이터셋에 대해 낮은 WRA 값을 보였으며, 이는 이러한 범위의 대부분에는 주어진 word 내 모든 character를 올바르게 예측하는 평가 과제에 직면한 긴 word의 text를 포함하고 있기 때문임.
- 종횡비가 0.3 이상이며, 0.5 이하인 경우의 이미지(word 당 4~9개의 character들을 포함하는 중간 word 길이의 이미지들이 포함됨)에 대해서는, 그림 18에서 볼 수 있듯이 연구된 기법들 모두 가장 높은 WRA 값을 보임.
- 그림 18에서는 종횡비가 0.6 이상인 이미지들에 대해 고려된 최신의 기법들을 평가할 시 모든 기법들은 WRA 값이 낮아진 것을 또한 관찰할 수 있으며, 이는 이러한 이미지들의 word들은 대부분 길이가 짧으며, 저해상도를 갖기 때문임.
3) 인식 시간
고려된 최신의 scene text recognition 모델들[16, 52–56]에 대해, WRA 대비 인식 시간에 대한 비교 연구를 수행하였음.
- 그림 19는 테스트 batch size가 1일 때, word 이미지 당 추론 시간을 milliseconds로 나타낸 결과를 보여주고 있으며 더 큰 batch size를 사용하면 추론 시간을 줄일 수 있음.

- 가장 빠른 기법은 CRNN[52]으로 word 당 time이 ~2.17 msec를, 가장 느린 기법은 ASTER[16]으로 word 당 time이 ~23.26 msec를 보였으며 이는 이러한 모델들의 계산적 요구들에는 큰 gap이 있음을 설명함.
- 비록 attention 기반 기법들(ASTER [16], CLOVA [56])이 CTC 기반 기법들(CRNN [52], ROSETTA [55], STAR-Net [54])보다 높은 WRA 값을 나타냈지만, CTC 기반 기법들보다 훨씬 더 느린 속도를 보였으며, 이는 attention 기반 기법들의 아키텍처에서 사용되는 보다 deep한 feature extractor와 교정(rectification) 모듈 때문임.
3.5 Open Investigations for Scene Text Detection and Recognition
object detection 및 recognition 문제의 최근 발전에 따라, 딥러닝 기반의 scene text detection 및 recognition 프레임워크들은 몇몇 벤치마크 데이터셋에 대해 H-mean 성능과 인식 정확도가 약 80%~95%일 정도로 빠른 진척을 보임. 하지만 앞에서 논의한 바와 같이, 향 후 연구에 대해서는 아직도 해결하지 못한 많은 문제가 있음.
3.5.1 Training Datasets
- recognition 알고리즘의 훈련에 있어서 합성 데이터셋의 역할을 무시할 수 없지만, detection 기법들의 fine tunning을 위해서는 여전히 더 많은 실세계 데이터셋을 필요로 함.
- 따라서, generative adversarial network [189] 기반 기법들 또는 3D proposal 기반[190] 모델들을 이용하여 더 실제적인 text 이미지들을 만드는 것이 text detector 훈련을 위해 합성 데이터셋을 만드는 더 나은 방법이 될 수 있을 것임.
3.5.2 Richer Annotations
- detection 및 recognition 둘다 자연 환경 이미지의 도전적인 요소들을 정량화 하는데 있어 annotation의 부족으로 인해, 존재하는 기법들은 이러한 도전적 요소들의 처리에 대해 명확하게 평가를 할 수 없음.
- 따라서, 존재하는 기법들이 이러한 도전적인 요소들에 대해 평가될 수 있도록 벤치마크 데이터셋에 대해 더 많은 annotation이 추가적인 descriptors(예: 방향, 조명 상태, 종횡비, word 길이, 폰트 타입 등)로 지원되어야 하며, 이는 향 후 연구자들이 보다 강건하며 일반화된 알고리즘을 설계하는데 도움이 될 것임.
3.5.3 Novel Feature Extractors
- 어떤 유형의 features가 개선된 text detection 및 recognition 모델을 구축하는데 유용할지에 대해 더 잘 이해하는 것은 중요함.
- 예를 들어, 더 많은 수의 layer를 가진 ResNet[148]은 보다 나은 결과를 제공할 것이며[46, 191], 반면에 text를 다른 object들과 구분하고 다양한 text characters도 인식할 수 있는 효율적인 feature extractor가 무엇인지에 대해서는 아직 명확하지 않음.
- 따라서, detection 및 recognition 모두에서 backbone 역할을 하는 서로 다른 feature extraction 아키텍처에 대한 종속성(dependents)에 대해 보다 철저한 연구가 필요함.
3.5.4 Occlusion Handling
- 지금까지 scene text recognition의 존재하는 기법들은 이미지 내 대상 character들의 가시성(visibility)에 의존적이나, 심한 가려짐에 영향을 받은 text는 이러한 기법들의 성능을 크게 저하시킬 수 있음.
- BERT [182]와 같은 강력한 자연어 처리 모델을 기반으로 text recognition 체계를 설계하면 주어진 text에서 가려진 character들을 예측하는데 도움이 될 수 있음.
3.5.5 Complex Fonts and Special Characters
- 자연 환경 내 이미지들은 붓글씨(calligraphic) 폰트, 색상 등의 넓고 다양한 종류의 복잡한 폰트들을 가진 text를 포함하고 있음. 이러한 가변성들(variabilities)의 극복은 style transfer learning 기술 [187, 188]을 이용하여 실세계와 보다 유사한 text를 가진 이미지를 생성하거나 feature extraction 기법[192, 193]의 backbone을 개선함으로써 가능할 수 있음.
- 3.4.2 장에서 언급했듯이, 자연 환경 내 이미지에는 특수 문자들(예: $, /, -, !, :, @, #)이 많이 있지만, 학계에서는 훈련 시 특수 문자를 무시해왔으며, 이들에 대해서는 부정확한 인식 결과를 만들게 됨. 따라서, 향후에는 scene text detection 및 recognition 기법들의 훈련 시 특수 문자를 가진 이미지를 포함함으로써, 이러한 character들의 검출 및 인식에 있어서 모델 평가 시 도움이 될 수 있을 것임.
4 Conclusions and Recommended Future Work
최근의 scene text detection 및 recognition 관련 조사 논문들에서는 분석된 딥러닝 기반의 기법들에 대한 성능이 여러 데이터셋에 대해서 비교되었음에도 불구하고 개별 논문에서 보고된 결과가 평가에 사용되어 이러한 기법들 간의 직접적인 비교가 어렵다는 사실을 알게 되었으며, 이것은 일반적인 실험 설정, ground-truth, 평가 방법론 등의 부족 때문임.
- 본 논문에서는 최초로 딥러닝 기반의 기법 및 아키텍처에 초점을 두고 scene text detection 및 recognition 분야의 최근 발전에 대해 상세한 리뷰를 함.
- 그 다음, 최근의 최신 접근들을 나타내는 선택된 몇몇의 pre-trained된 scene text detection 및 recognition 기법들을 불리한 상황에서 성능을 비교를 위해, 도전적인 벤치마크 데이터셋에 대해 광범위한 실험을 수행함.
- 보다 구체적으로, ICDAR13, ICDAR15, COCO-Text 데이터셋에 대해 선택된 scene text detection 기법들을 평가할 때 다음과 같은 것들을 알게 됨:
- - 불규칙한 text의 위치를 예측하는데 있어서는 PixelLink, PSENET, PAN과 같은 segmentation 기반 기법들이 훨씬 더 강건함.
- - PMTD와 같은 Hybrid regression 및 segmentation 기반 기법은 여러 방향성을 가진 text를 처리할 수 있으므로, 모든 3개의 데이터셋에 대해 가장 우수한 H-mean 값을 보임.
- - CRAFT와 같이 character level에서 text를 검출하는 기법들은 불규칙한 모양의 text를 검출하는데 있어서 더 나은 성능을 보임.
- - 하나 이상의 도전적인 요소들에 의해 영향을 받는 text가 있는 이미지들에 대해서는 연구된 방법 모두 미약한 성능을 보임.
- 도전적인 벤치마크 데이터셋에서 scene text recognition 기법들을 평가함에 있어서, 다음과 같은 것들을 알게 됨:
- - 단지 훈련용으로만 합성된 scene 이미지들을 사용하는 scene text recognition 기법들은 해당 모델들의 fine-tunning 없이도 실세계의 이미지들을 인식할 수 있었음.
- - 일반적으로 ASTER 및 CLOVA와 같은 attention 기반 기법들은 CRNN, STARNET, ROSETTA와 같은 CTC 기반 기법들보다 feature extraction에 있어서 deep한 backbone에 대한 이점을, 교정(rectification)에 있어서 transformation network에 대한 이점을 얻을 수 있었음.
in-plane 회전, 여러 방향성 및 해상도를 가진 text, 원근 왜곡, 그림자 및 조명 반사, 이미지의 블러, 부분적인 가려짐, 복잡한 폰트 및 특수 문자 등의 자연 환경 이미지에서 text를 검출하거나 인식하기 위해서 해결하지 못한 도전적인 요소들이 남아 있는 것을 확인함. 본 논문에서는 이에 대해 논의하였으며, 이는 더 많은 잠재적인 향 후 연구 방향을 열어줄 수 있을 것임. 또한, 본 연구에서는 향 후 detector들이 보다 도전적인 조건에서 훈련 및 평가될 수 있도록 text instance에 대해 더 많은 설명이 있는 annotations을 보유하는 것의 중요성에 대해 강조를 함.
'Computer Vision > Optical Character Recognition' 카테고리의 다른 글
| [논문 읽기/2021] A Survey of Deep Learning Approaches for OCR and Document Understanding (0) | 2021.04.14 |
|---|
